
Game Theoretic Approaches for Deception and Counterdeception
Assistant Professor Zachary Sunberg
University of Colorado Boulder
May 5th, 2026
Why Game Theory?
- Example context: air defense against maneuvering attackers.
- Traditional approach: assume a model for the attacker, use optimal control to intercept.
- Attacker can exploit this approach by behaving unpredictably (a form of deception).
- If, instead, we play a Nash equilibrium strategy for a zero-sum game, the strategy is robust in the sense that we will do no worse if the other player changes their strategy.
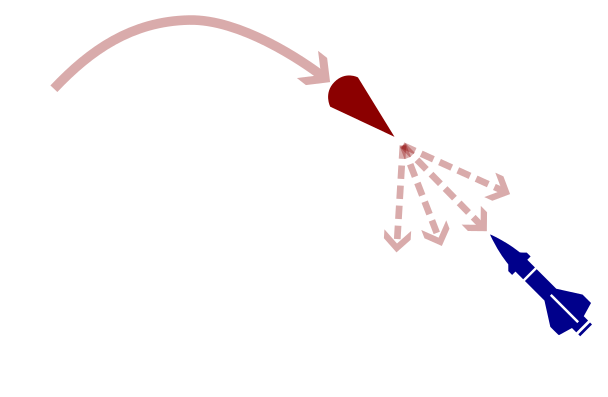
POSG Example: Missile Defense
POMDP Solution:
- Assume a distribution for the missile's actions
- Update belief according to this distribution
- Use a POMDP planner to find the best defensive action
Need some Game Theory!
Nash equilibrium: All players play a best response to the other players
A shrewd missile operator will use different actions, invalidating our belief
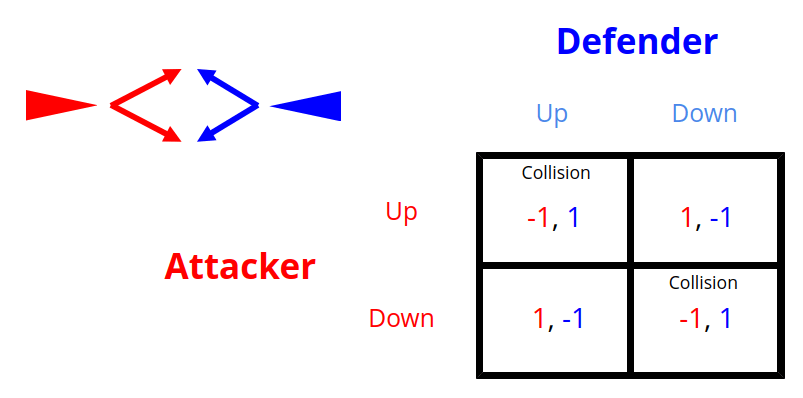
Simplified Missile Defense Game
|
|
|
|
|
Attacker
Defender
Up
Down
Up
Down
-1, 1
1, -1
1, -1
-1, 1
Collision
Collision
No Pure Nash Equilibrium!
Need a broader solution concept: Mixed Nash equilibrium (includes deceptive behavior like bluffing)
Nash equilibrium: All players play a best response to the other players
Why Game Theory?

Is a Nash equilibrium strategy a good choice in real life against humans?
Yes! Example: Superhuman play in poker with deception through bluffing.
Tabletop Game 2: Poker
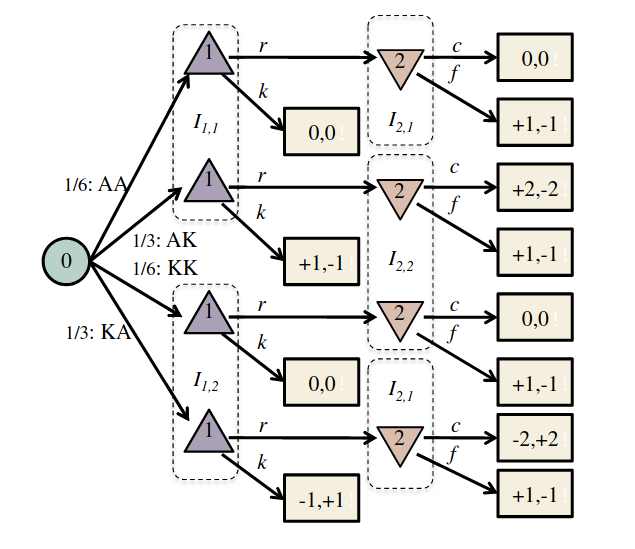
Image: Russel & Norvig, AI, a modern approach
P1: A
P1: K
P2: A
P2: A
P2: K
Part 1: Online Planning in POSGs

Tyler Becker
Joined DECODE AI project Fall 2024
Partially Observable Stochastic Games (POSGs)
- Environment has state \(s \in S\)
- Agents act simultaneously with \(a^i\) forming joint action \(\mathbf{a}\)
- State transitions according to \(T(s' \mid s, \mathbf{a})\)
- Each agent receives reward \(R^i(s, \mathbf{a}, s')\)
- Each agent receives an observation \(o^i\) with distribution \(Z(o^i \mid \mathbf{a}, s')\)

State space \(S\)

Actions
\(\mathbf{a}\)
\(a^1\)
\(a^2\)
\(a^n\)
Environment with
shared state \(s\)
Policy \(\pi^1\)
Policy \(\pi^1\)
Policy \(\pi^n\)
\(\vdots\)
Observations
\(\mathbf{o}\)
\(o^1\)
\(o^2\)
\(o^n\)
\(S = \mathbb{R}^{12}\)
\(\times \mathbb{R}^{12}\)
\(\times \mathbb{R}^{\infty}\)
Two ways to represent uncertainty
Single Player (POMDP): Beliefs
Extensive Form Game: Information Set
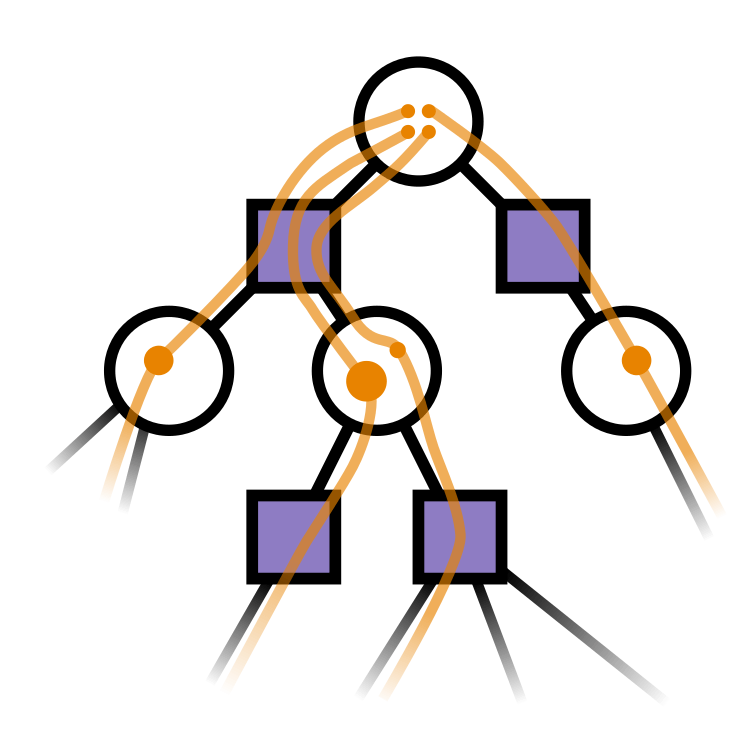

Image: Russel & Norvig, AI, a modern approach
P1: A
P1: K
P2: A
P2: A
P2: K
Text
Online POMDP Planning
Environment
\(Q(b, a)\)
Belief \(b\)
Belief Updater
Planner
State \(s\)


Observation \(o\)

Why are POMDPs difficult?
- Curse of History
- Curse of dimensionality
- State space
- Observation space
- Action space

[Lim, et al., 2023, JAIR]
Tabletop Game 1: Go
Improvements Needed
- Simultaneous Play
- State Uncertainty


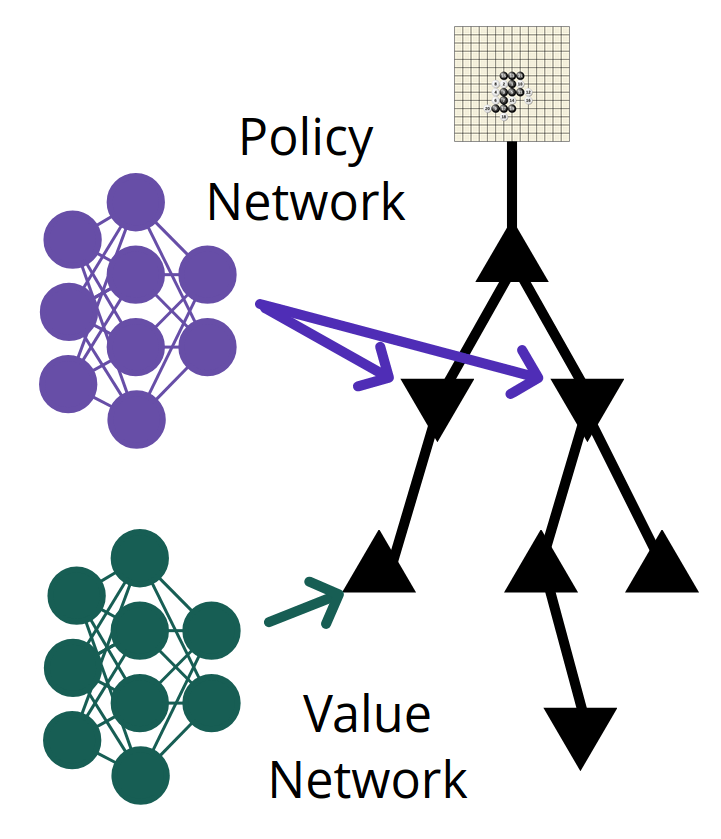
Policy Network
Value Network
POSGs: Challenges and Existing Tools
- Large state spaces
- Partial observations
- Strategic opponents
- Deception and counter-deception
- Our approach: Build on these three tools
| Tool | Good At | Missing |
|---|---|---|
| POMDP* solvers | State uncertainty | Strategic opponents |
| EFG** Solvers | Strategic opponents | Probabilistic beliefs |
| AlphaZero | Learned search | Simultaneous moves |
* A POMDP (Partially Observable Markov Decision Process) is a single agent POSG (much easier)
** EFG = Extensive Form Game
Image: Russel & Norvig, AI, a modern approach
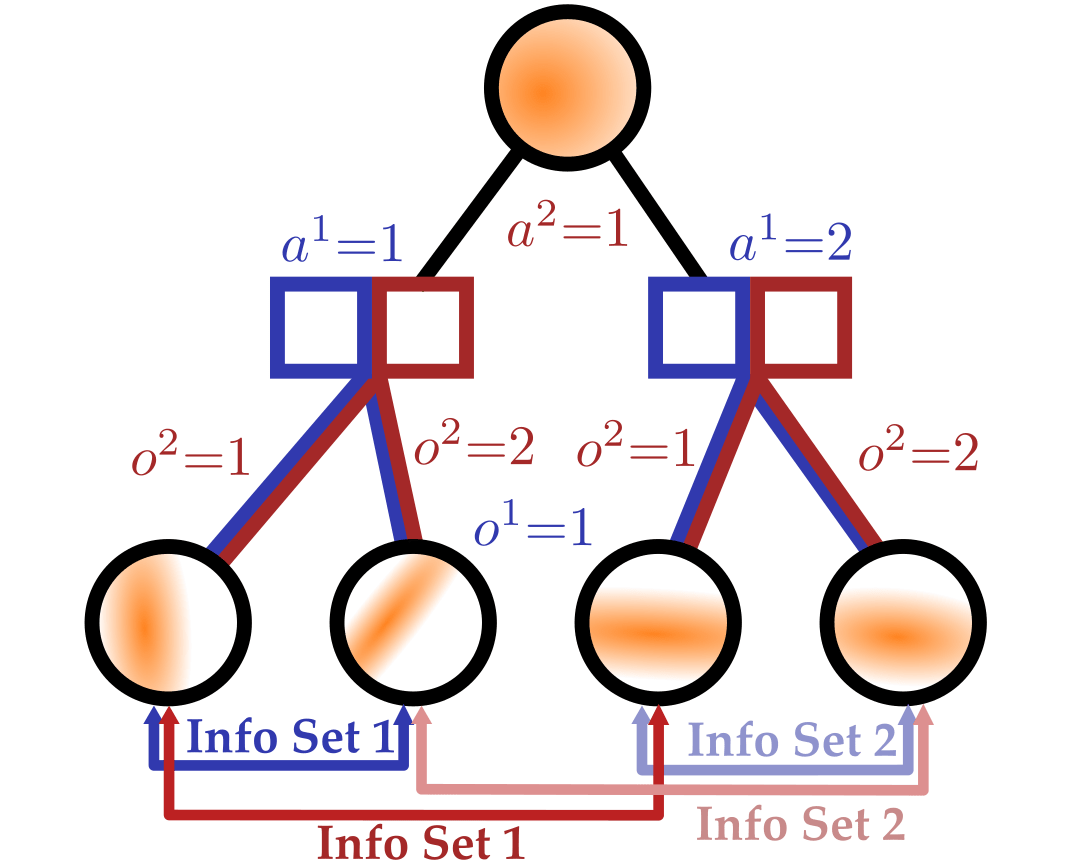
- CDIT (conditional distribution infoset trees) = particles + information sets
- Particles approximate hidden state
- Information sets preserve strategic uncertainty
- CFR (counterfactual regret minimization) searches for low-exploitability policies
Particle-Filter POSGs
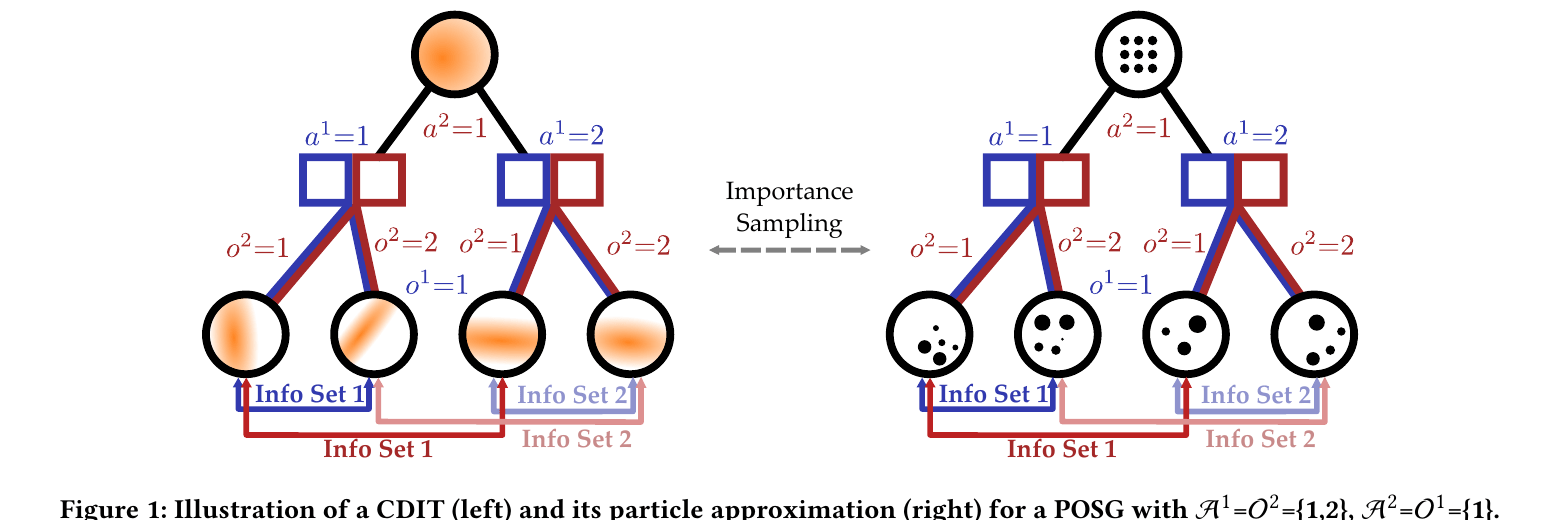
Online Planning Structure: CDIT
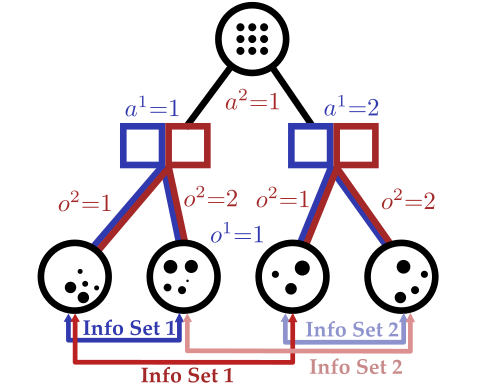
[Becker & Sunberg, AAMAS 2025]
Our approach: combine particle filtering and information sets
Joint Belief
Joint Action
- Standard uncertainty-aware planners handle hidden states, but not strategic interaction
- Standard game-theoretic planners handle other agents, but scale poorly to physical state spaces
- Need planning methods for uncertain, multi-agent, real-world environments
Test Environment: Partially Observable Tag
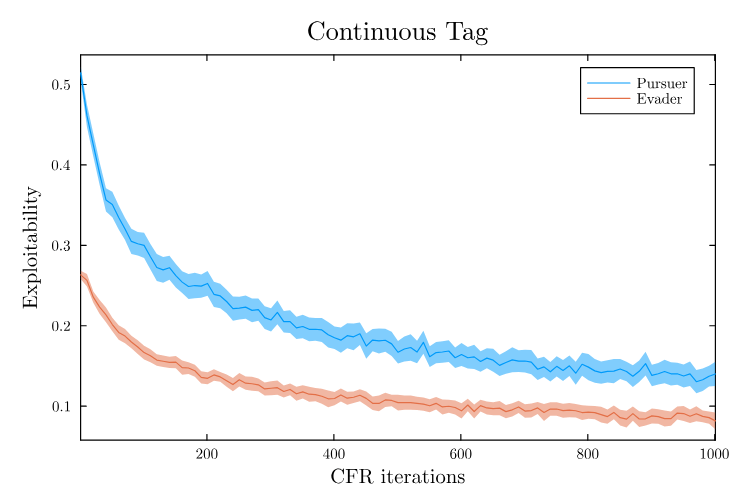
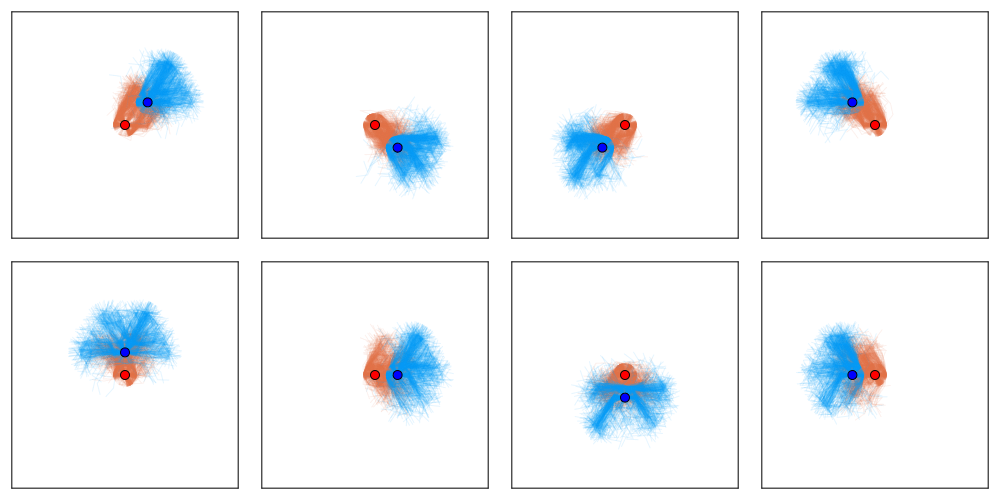
[Becker & Sunberg, AAMAS 2025]
- Equilibrium policies are stochastic and hide intent
- Exploitability measures vulnerability - demonstrably decreases
What the CDIT Gives Us
[Becker & Sunberg, AAMAS 2025]
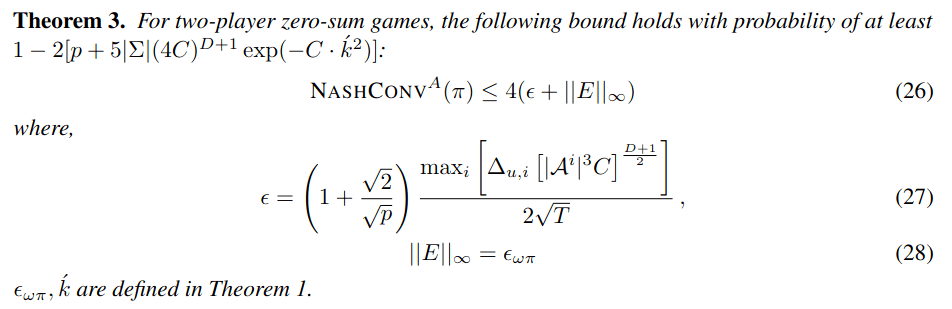
- Equilibrium search without state enumeration
- Continuous-state POSG planning
- Probabilistic exploitability bounds
- No direct dependence on state space size
Combining with Learning: Simultaneous Alpha Zero

- AlphaZero assumes turn-taking
- Markov Games (e.g. POSGs) move simultaneously
- Each state becomes a matrix game
- Search improves both players' policies
Alpha Zero
SimultaneousAlpha Zero
(Ours)
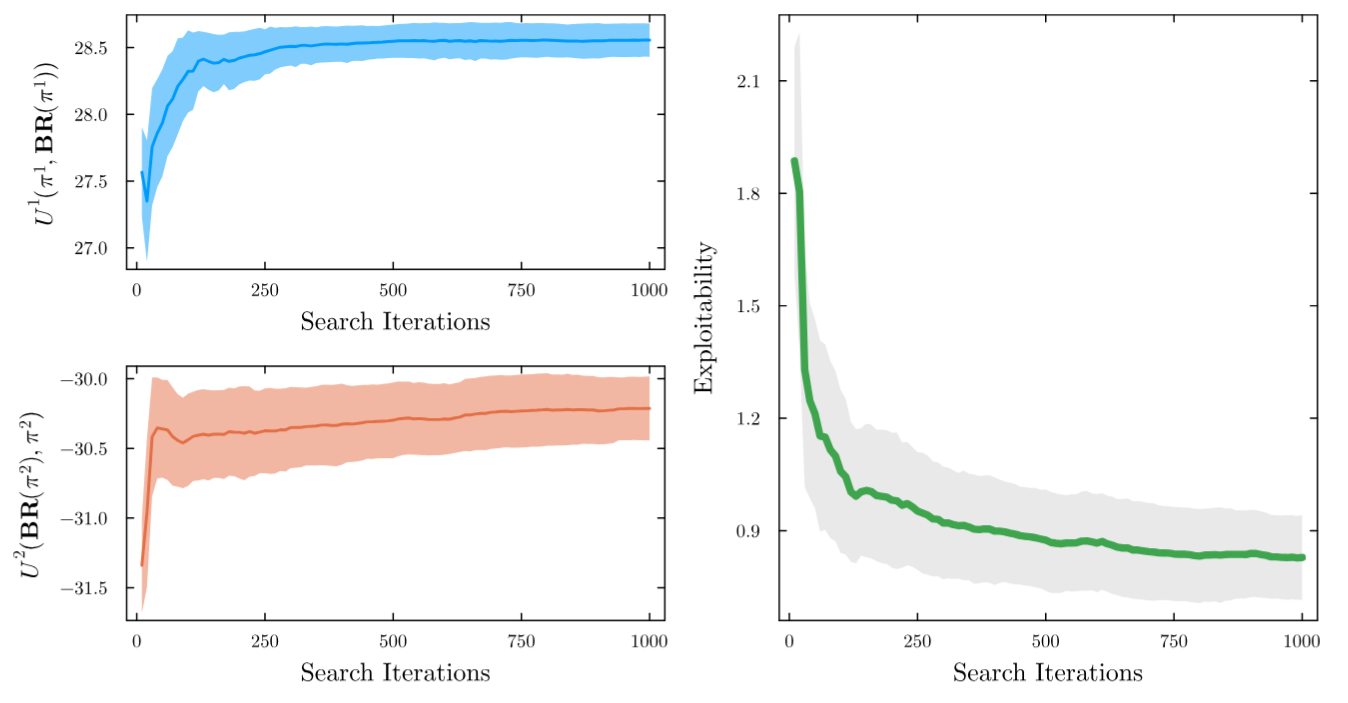
Search Improves Robustness
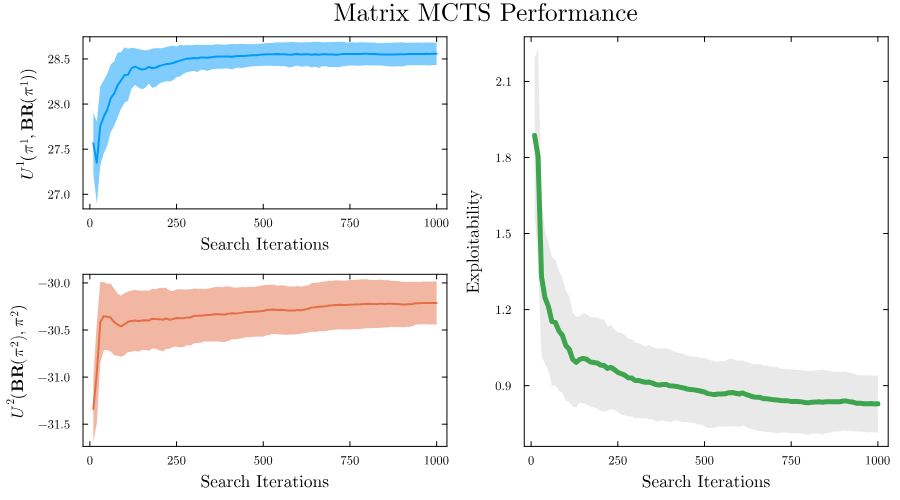
- Best-response value improves; exploitability falls
- Mixed actions prevent exploitation
- Deeper search provably reduces exploitability
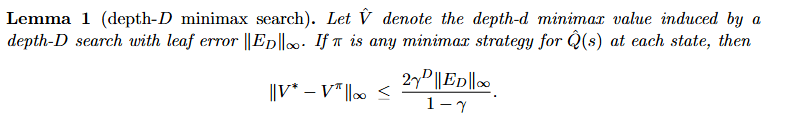
Counter-Deception in SDA
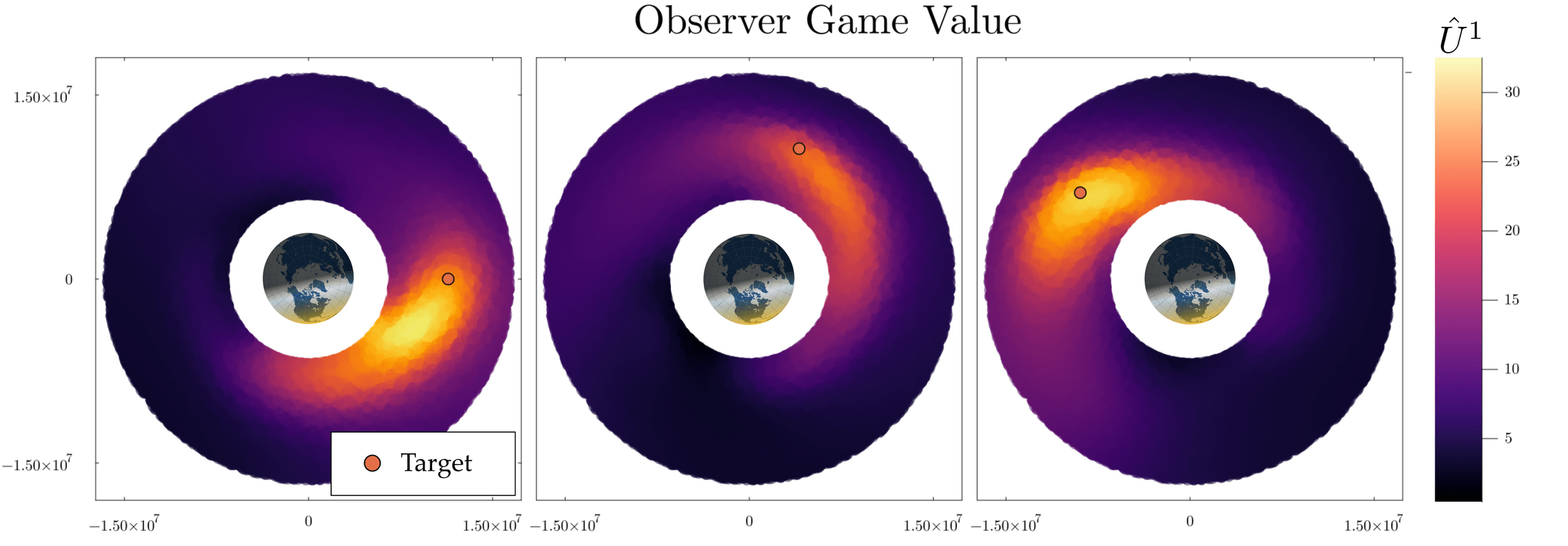
- Target exploits eclipse and occlusion
- Observer learns sensing geometry and robust manuevering strategies

- Observer satellite seeks well-illuminated vantage-points of target satellite
1. Simultaneous Play:
Space Domain Awareness
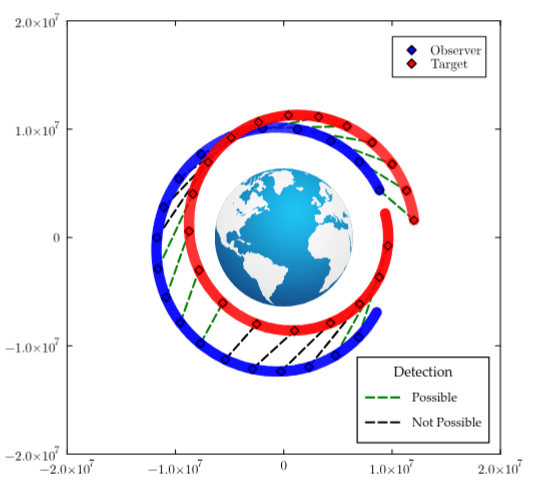
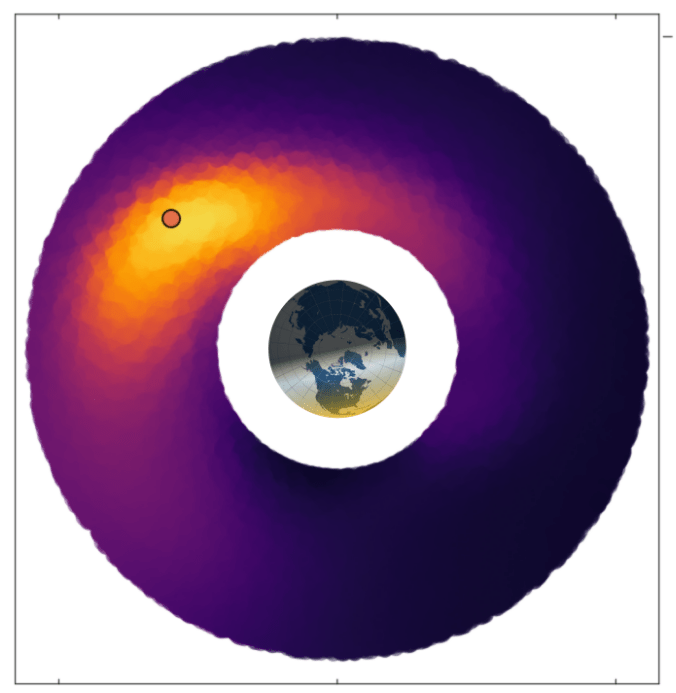

[Becker & Sunberg, AMOS 2025]
What about state uncertainty?
Up Next: Policy State Approximation

Reduce histories to a representative set, to make online planning tractable
Part 2: Optimal Deception on Shared Channels

Mel Krusniak
Joined DECODE AI project Jan. 2026
Motivation: Informed Pursuit-Evasion
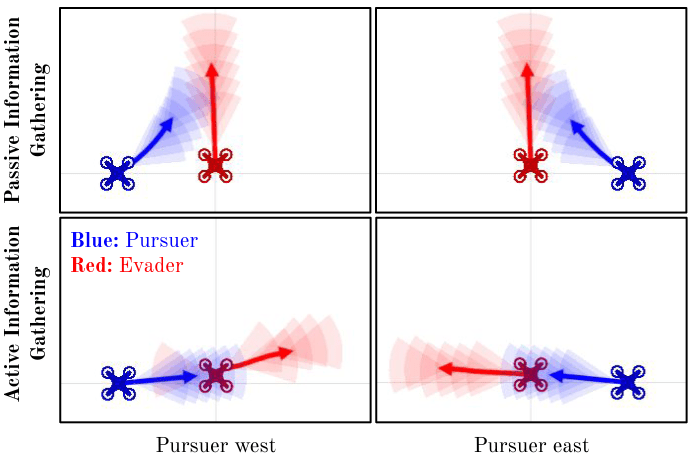
Past work: How do we teach adversarial agents in trajectory space to hide and seek information about each other?
Present work: How do we teach a higher-level broadcaster to publicly share the "right" information with an ally?

Goal: Optimal Informer
Behavior

Consider a three player interaction with one player at a higher informational level.
- Pursuer, Evader: Competition with side goals, acting based on semi-public information.
- Informer: Sees the full state. Determines what semi-public information is broadcast.
Research thrust: Automatically choose what information to broadcast, what channel to use, and how precisely to convey it.
Preliminary Methods
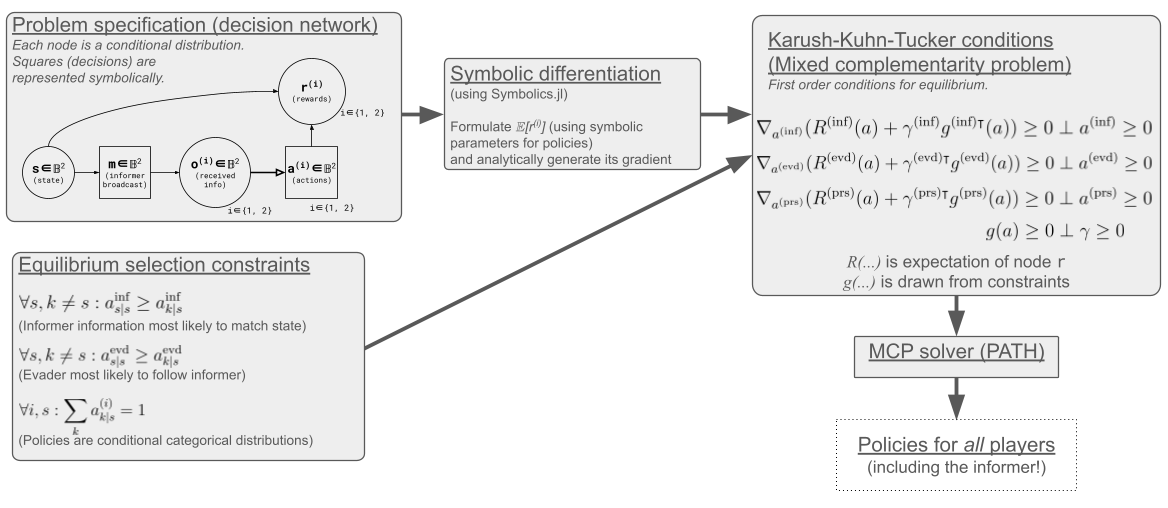
"When should I lie?"
(or "what channels are safe?")
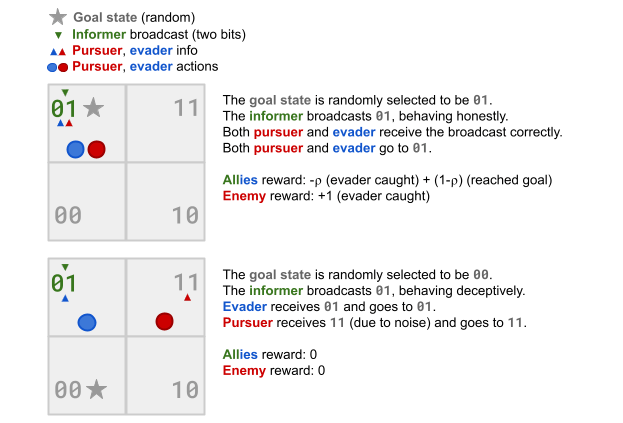
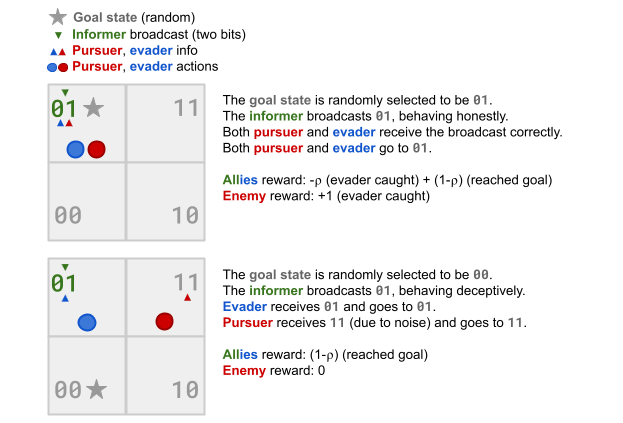
Test environment: Discrete tag in a 2x2 grid.
Four states, two bits of information.
"When should I lie?"
(or "what channels are safe?")
Test environment: Discrete tag in a 2x2 grid.
Four states, two bits of information.
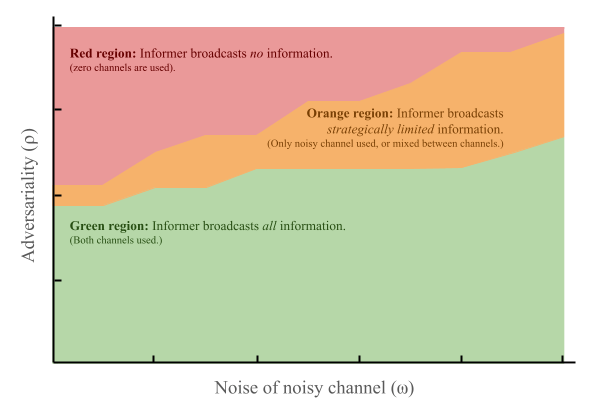
- Adversariality: Evader has a side goal.
It seeks a goal state with weight (1-⍴).
Goal is random, but seen by the informer.
- Noise: Pursuer has worse observations.
The second bit (or "channel") is perturbed with probability ⍵.
\[r^{(\text{evd})}(a) = (1 - \rho) \; r^{(\text{evd})}_{\text{reach\_goal}}(a) + \rho \;r^{(\text{evd})}_{\text{avoid\_psr}}(a)\]
Long Term Goals
This is one example of an "information game." Others of interest include:
- Channel takeover prevention / "confirm-then-commit" tactics
- Dogwhistle / "double speak" identification
- Information denial via mixed strategies
Game theory, machine learning, and control theory all contribute useful tools, but converting between formalizations is fraught, error-prone, and inefficient.
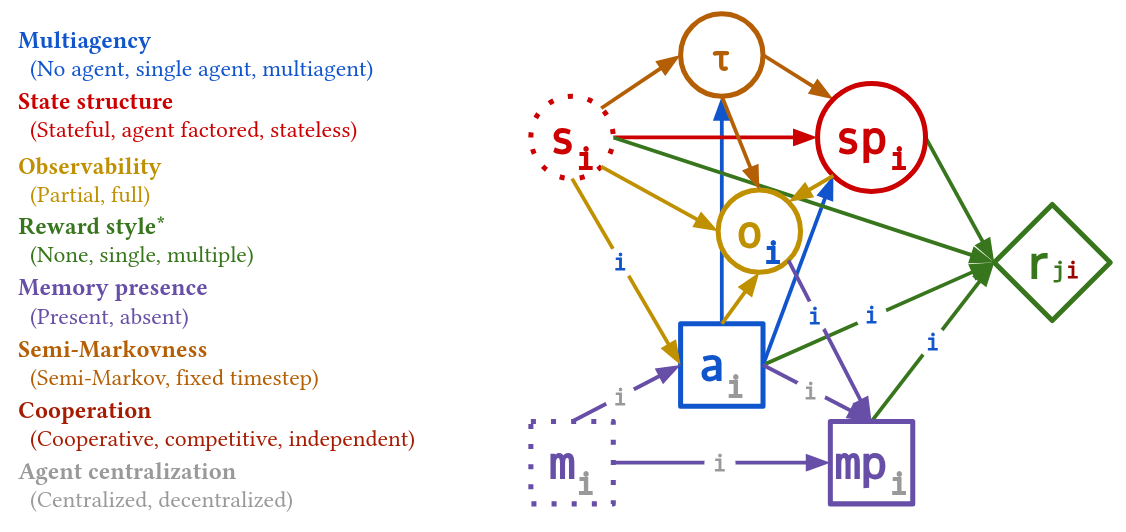
Decisions.jl: Representing and solving games with arbitrary decision networks
Open Source Software!

[Krusniak et al. AAMAS 2026]
Decisions.jl
Arbitrary Dynamic Decision Networks

POMDPs.jl
using POMDPs, QuickPOMDPs, POMDPTools, QMDP
m = QuickPOMDP(
states = ["left", "right"],
actions = ["left", "right", "listen"],
observations = ["left", "right"],
initialstate = Uniform(["left", "right"]),
discount = 0.95,
transition = function (s, a)
if a == "listen"
return Deterministic(s)
else # a door is opened
return Uniform(["left", "right"]) # reset
end
end,
observation = function (s, a, sp)
if a == "listen"
if sp == "left"
return SparseCat(["left", "right"], [0.85, 0.15])
else
return SparseCat(["right", "left"], [0.85, 0.15])
end
else
return Uniform(["left", "right"])
end
end,
reward = function (s, a)
if a == "listen"
return -1.0
elseif s == a # the tiger was found
return -100.0
else # the tiger was escaped
return 10.0
end
end
)
solver = QMDPSolver()
policy = solve(solver, m)Thank You!




(Opinions are my own)
DECODE AI May 2026
By Zachary Sunberg




