
5-7 Minutes About Online Planning in POMDPs and POSGs
Assistant Professor Zachary Sunberg
University of Colorado Boulder
April 18, 2026
Autonomous Decision and Control Laboratory

-
Algorithmic Contributions
- Scalable algorithms for partially observable Markov decision processes (POMDPs)
- Motion planning with safety guarantees
- Game theoretic algorithms
-
Theoretical Contributions
- Particle POMDP approximation bounds
-
Applications
- Space Domain Awareness
- Autonomous Driving
- Autonomous Aerial Scientific Missions
- Search and Rescue
- Space Exploration
- Ecology
-
Open Source Software
- POMDPs.jl Julia ecosystem

PI: Prof. Zachary Sunberg

PhD Students










What do people think of when someone says "POMDP"?
Intractable

\([x, y, z,\;\; \phi, \theta, \psi,\;\; u, v, w,\;\; p,q,r]\)

\(\mathcal{S} = \mathbb{R}^{12}\)
\(\mathcal{S} = \mathbb{R}^{12} \times \mathbb{R}^\infty\)
(Offline) Reinforcement Learning | Online Planning
\begin{aligned}
& \mathcal{S} = \mathbb{Z} \quad \quad \quad ~~ \mathcal{O} = \mathbb{R} \\
& s' = s+a \quad \quad o \sim \mathcal{N}(s, |s-10|) \\
& \mathcal{A} = \{-10, -1, 0, 1, 10\} \\
& R(s, a) = \begin{cases}
100 & \text{ if } a = 0, s = 0 \\
-100 & \text{ if } a = 0, s \neq 0 \\
-1 & \text{ otherwise}
\end{cases} & \\
\end{aligned}

State
Timestep
Accurate Observations
Goal: \(a=0\) at \(s=0\)
Optimal Policy
Localize
\(a=0\)
POMDP Example: Light-Dark
POMDP (decision problem) is PSPACE Complete

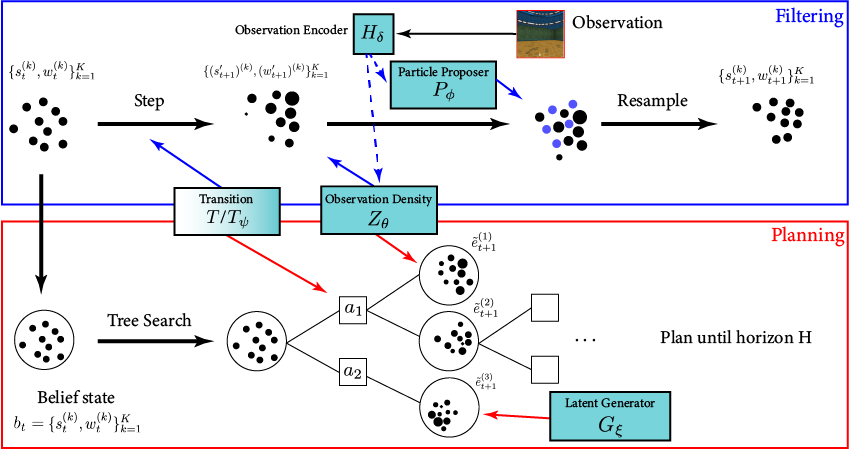
Online POMDP Planning
Environment

\(Q(b, a)\)
Belief \(b\)
Belief Updater
Planner
State \(s\)


Observation \(o\)

Online Planning Complements RL
- Composition: Components learned offline can be combined online
- Adaptation: The model used in an online planner can update without complete re-optimization
- Combination with Offline Optimization: Online planners can be used as improvement operators in offline optimization
- Explainability (?): At least all of the data used to make a decision is right there
[Deglurkar, Lim, Sunberg, & Tomlin, 2023]
Why is POMDP planning difficult?
- Curse of History
- Curse of dimensionality
- State space
- Observation space
- Action space
Tree size: \(O\left(\left(|A||O|\right)^D\right)\)
Curse of Dimensionality
\(d\) dimensions, \(k\) segments \(\,\rightarrow \, |S| = k^d\)



1 dimension
e.g. \(s = x \in S = \{1,2,3,4,5\}\)
\(|S| = 5\)
2 dimensions
e.g. \(s = (x,y) \in S = \{1,2,3,4,5\}^2\)
\(|S| = 25\)
3 dimensions
e.g. \(s = (x,y,x_h) \in S = \{1,2,3,4,5\}^3\)
\(|S| = 125\)
(Discretize each dimension into 5 segments)

\(x\)
\(y\)
\(x_h\)

Part II: Breaking the Curse
Integration
Find \(\underset{s\sim b}{E}[f(s)]\)
\[=\sum_{s \in S} f(s) b(s)\]
Monte Carlo Integration
\(Q_N \equiv \frac{1}{N} \sum_{i=1}^N f(s_i)\)
\(s_i \sim b\) i.i.d.
\(\text{Var}(Q_N) = \text{Var}\left(\frac{1}{N} \sum_{i=1}^N f(s_i)\right)\)
\(= \frac{1}{N^2} \sum_{i=1}^N\text{Var}\left(f(s_i)\right)\)
\(= \frac{1}{N} \text{Var}\left(f(s_i)\right)\)
(Bienayme)
Curse of dimensionality!
Inexact - but accuracy has no curse of dimensionality!
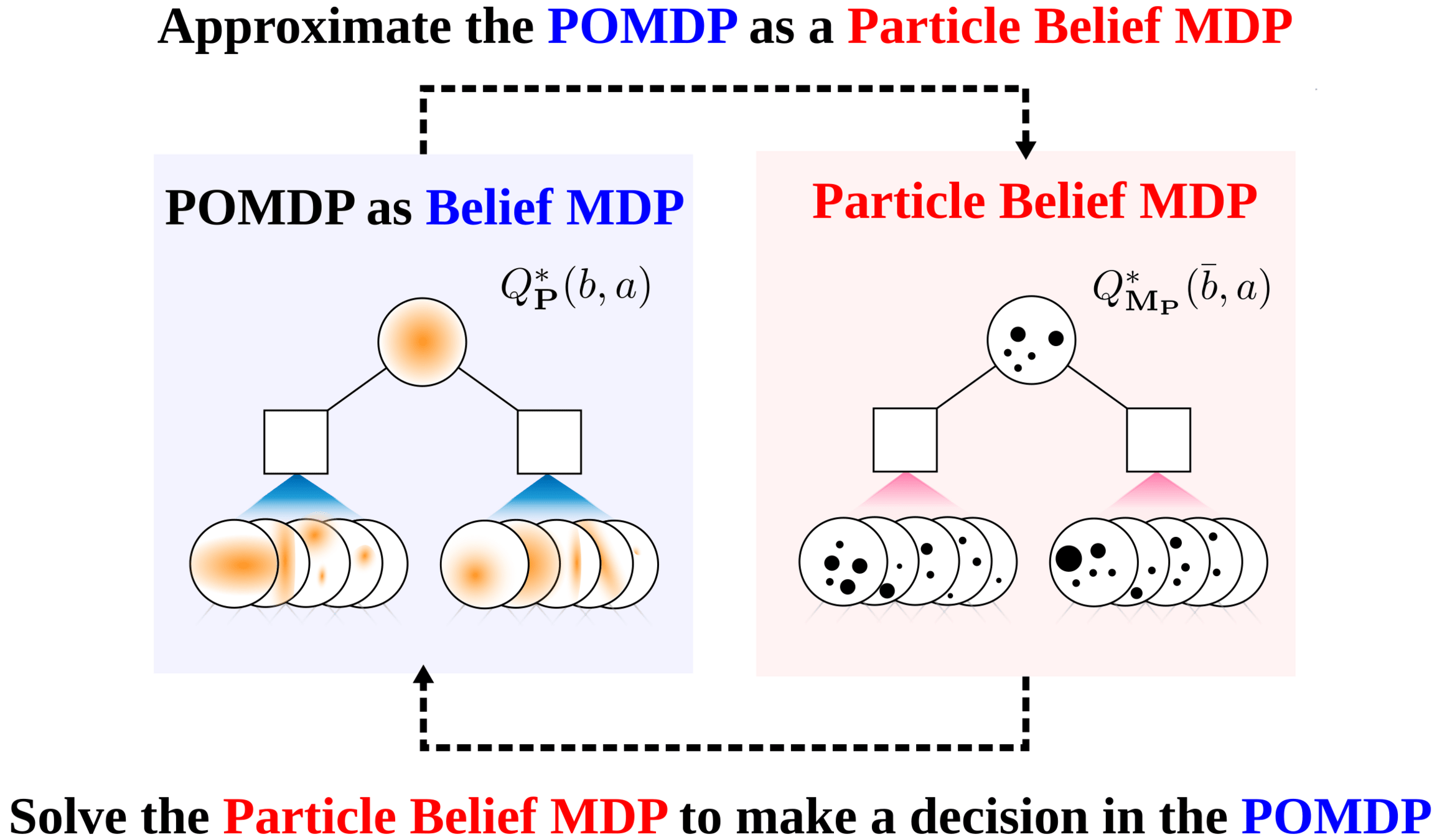
Particle Filter POMDP Approximation
POMDP Assumptions for Proofs

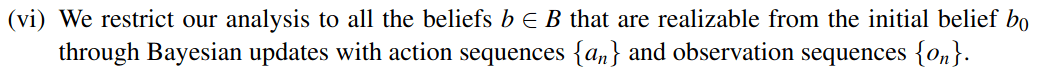
Continuous \(S\), \(O\); Discrete \(A\)
No Dirac-delta observation densities
Bounded Reward
Generative model for \(T\); Explicit model for \(Z\)
Finite Horizon
Only reasonable beliefs
Sparse Sampling-\(\omega\)


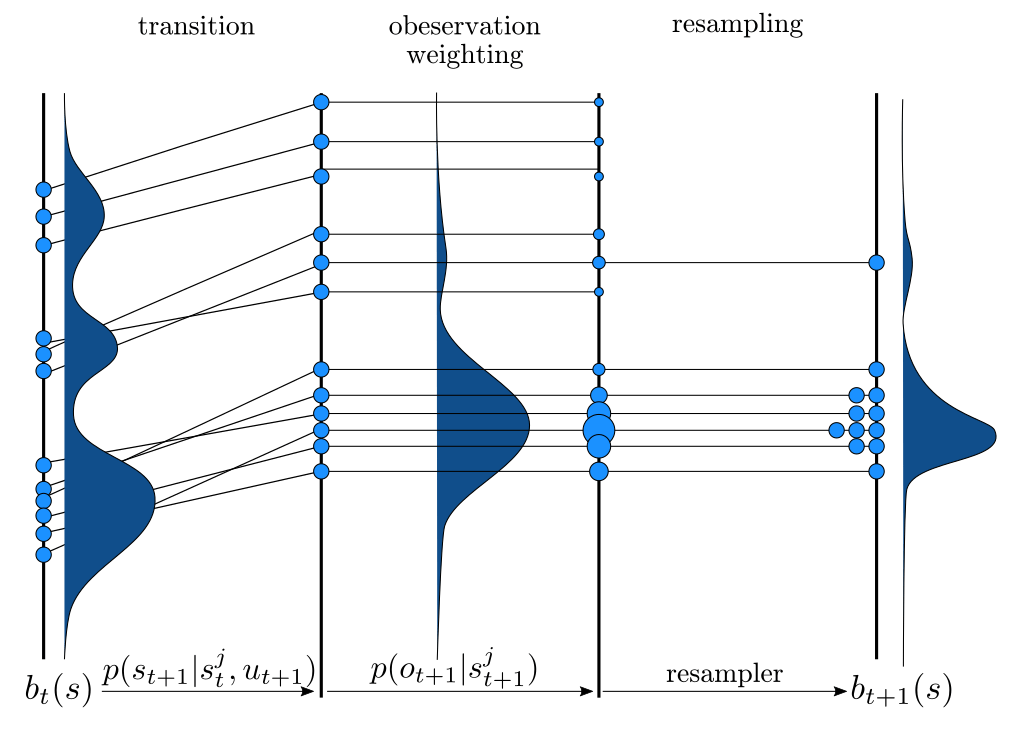
Key 1: Self Normalized Infinite Renyi Divergence Concentation
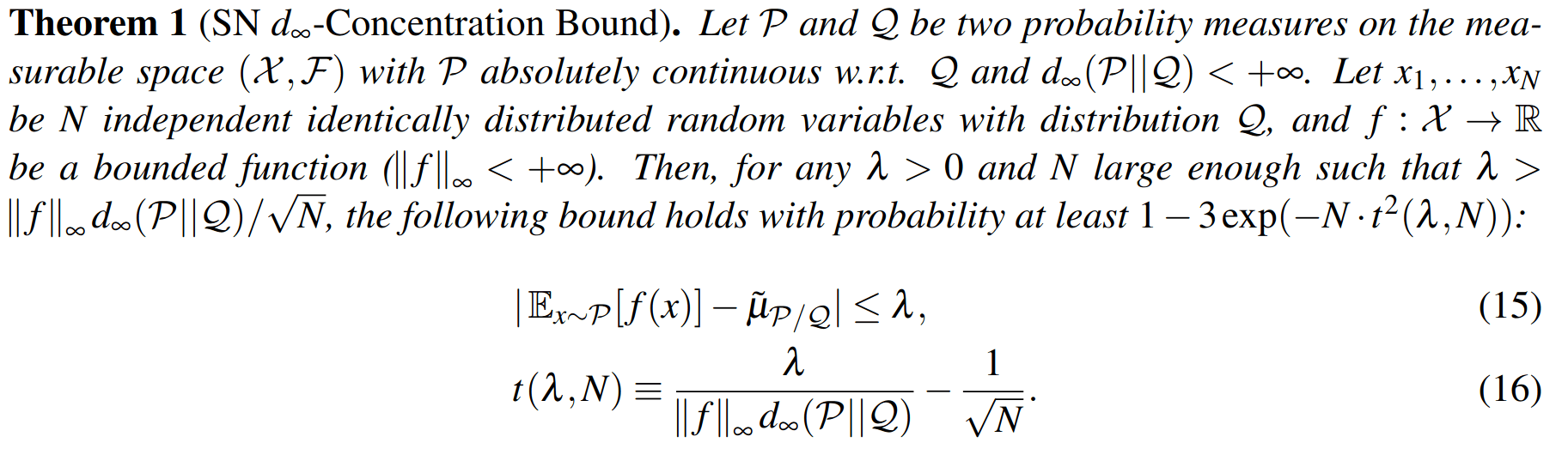
\(\mathcal{P}\): state distribution conditioned on observations (belief)
\(\mathcal{Q}\): marginal state distribution (proposal)
Key 2: Sparse Sampling
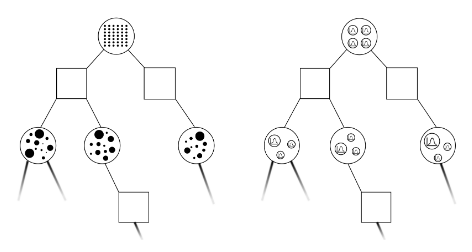
Expand for all actions (\(\left|\mathcal{A}\right| = 2\) in this case)
...
Expand for all \(\left|\mathcal{S}\right|\) states
\(C=3\) states

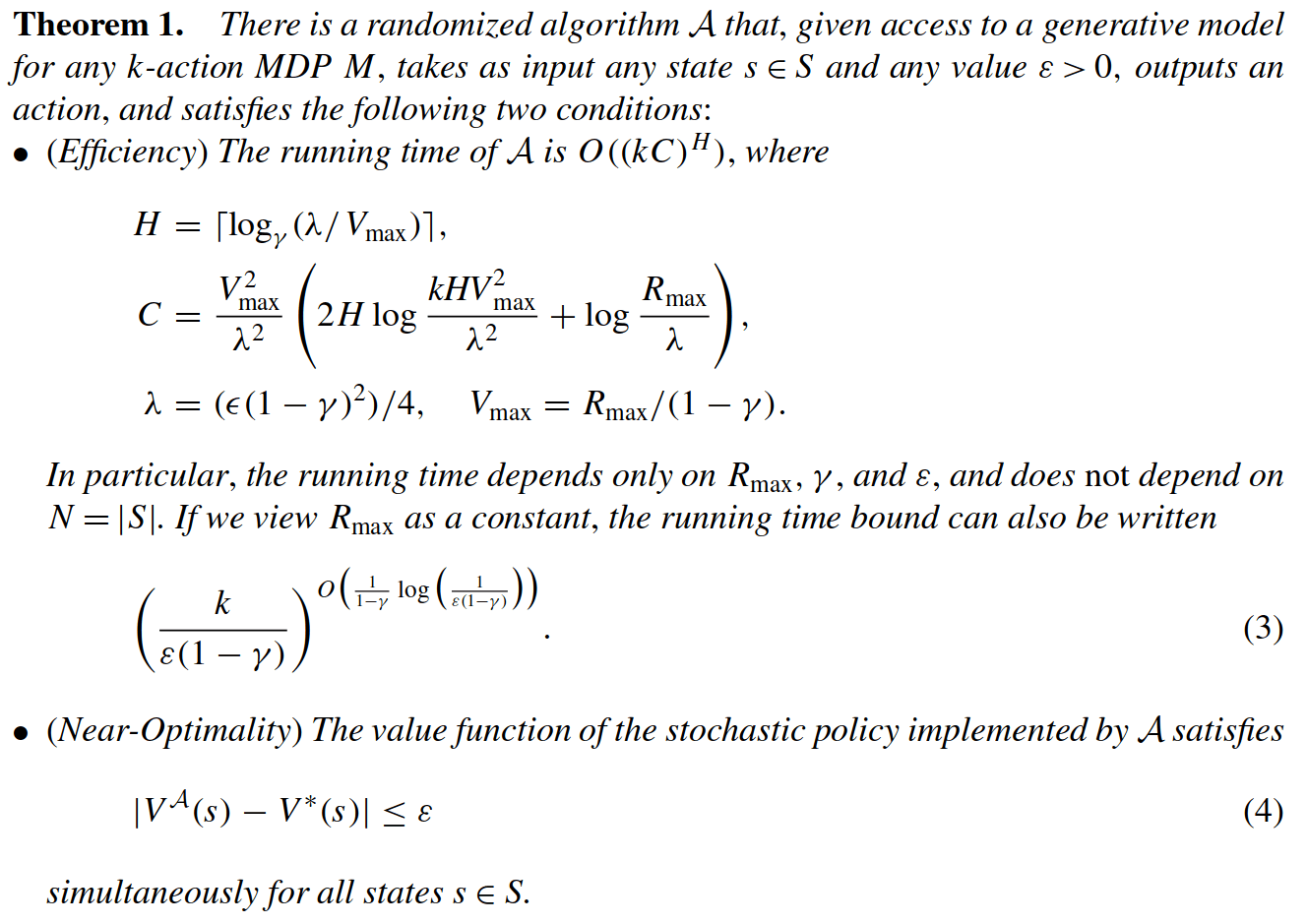
SS-\(\omega\) is close to Belief MDP

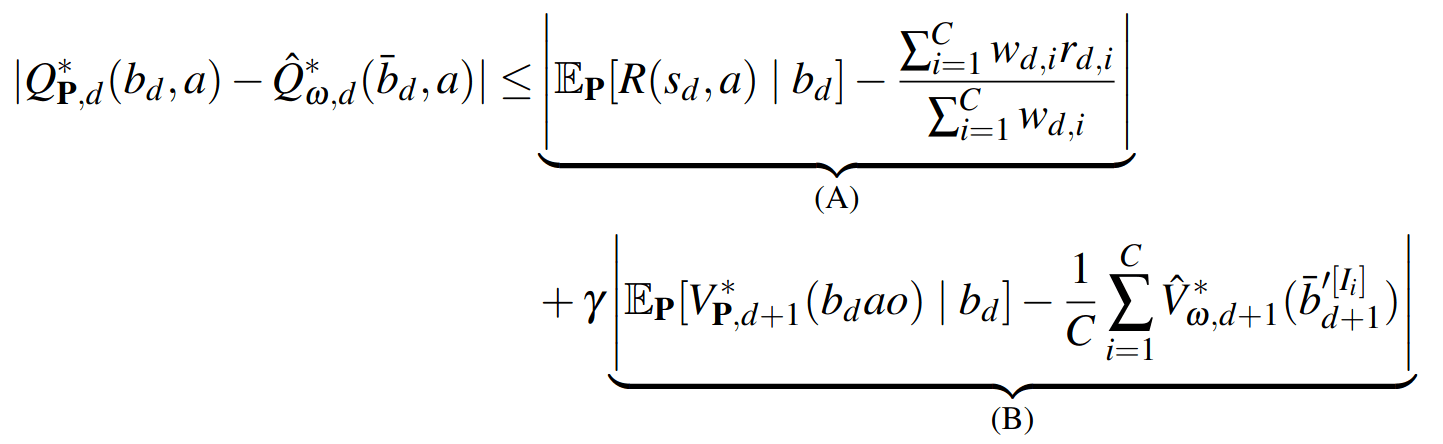
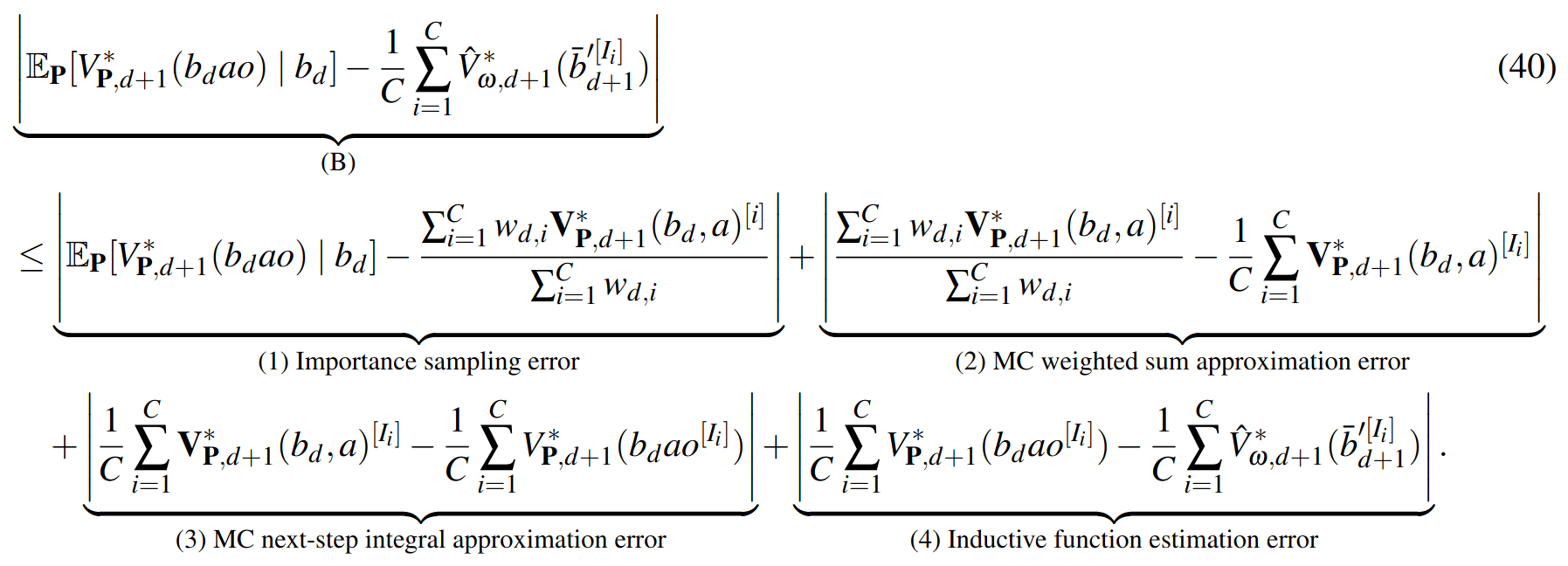
SS-\(\omega\) close to Particle Belief MDP (in terms of Q)

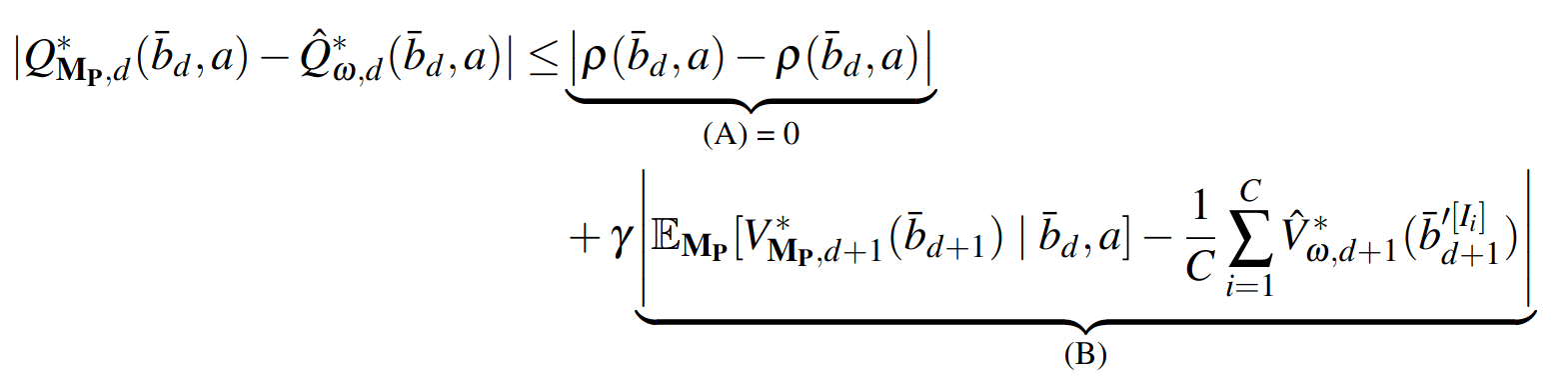
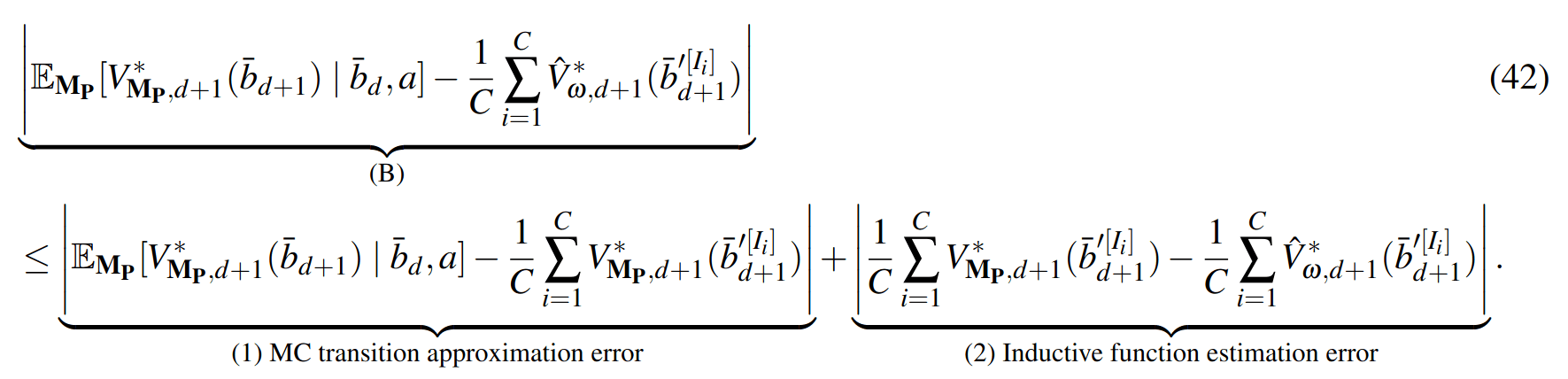
PF Approximation Accuracy
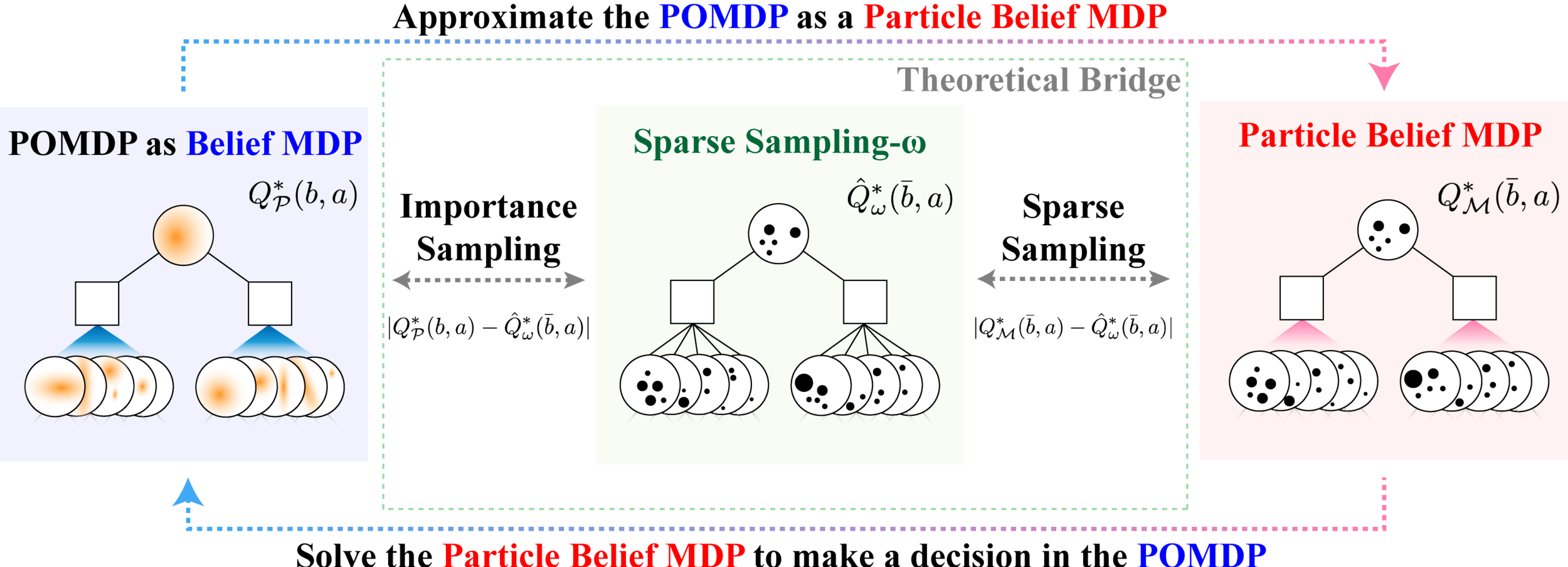
\[|Q_{\mathbf{P}}^*(b,a) - Q_{\mathbf{M}_{\mathbf{P}}}^*(\bar{b},a)| \leq \epsilon \quad \text{w.p. } 1-\delta\]
For any \(\epsilon>0\) and \(\delta>0\), if \(C\) (number of particles) is high enough,
[Lim, Becker, Kochenderfer, Tomlin, & Sunberg, JAIR 2023]
No direct dependence on \(|\mathcal{S}|\) or \(|\mathcal{O}|\)!

Particle belief planning suboptimality

\(C\) is too large for any direct safety guarantees. But, in practice, works extremely well for improving efficiency.
[Lim, Becker, Kochenderfer, Tomlin, & Sunberg, JAIR 2023]
Why are POMDPs difficult?
- Curse of History
- Curse of dimensionality
- State space
- Observation space
- Action space
[Lim, et al., 2023, JAIR]
Easy MDP to POMDP Extension

Example: POMDP Tracking in Crowds
State:
- Vehicle physical state
- Human physical state
- Human intention
- Target location

[Gupta, Aladum et al., IROS 2026]
Two Caveats
- Number of particles is too big for practical safety guarantees.
- Depends on the Renyi Divergence \(d_\infty(\mathcal{P} \Vert \mathcal{Q})\), which often grows in high-dimensional problems.
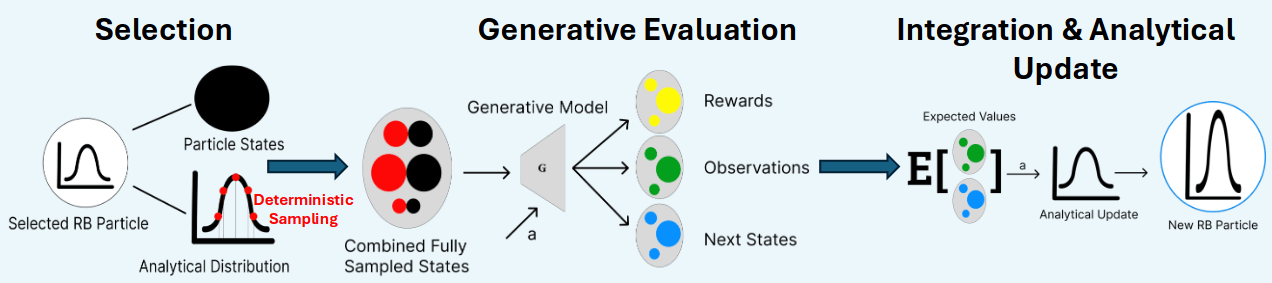
Possible Solution to 2:
Rao-Blackwellized POMDP Planning
\(p(s_t \mid h_t)\)
\(= p(s^a_t \mid s^p_t, h_t) \, p(s^p_t \mid h_t)\)
Analytical update (e.g. Kalman Filter)
Particle Filter

[Lee, Wray, Sunberg, Ahmed, ICRA 2026]
Marginal
Observation-Conditioned
Example 2: Meteorology
- State: physical state of aircraft, weather
- Belief: Weighting over several forecast ensemble members
- Action: flight direction, drifter deploy
- Reward: Terminal reward for correct weather prediction
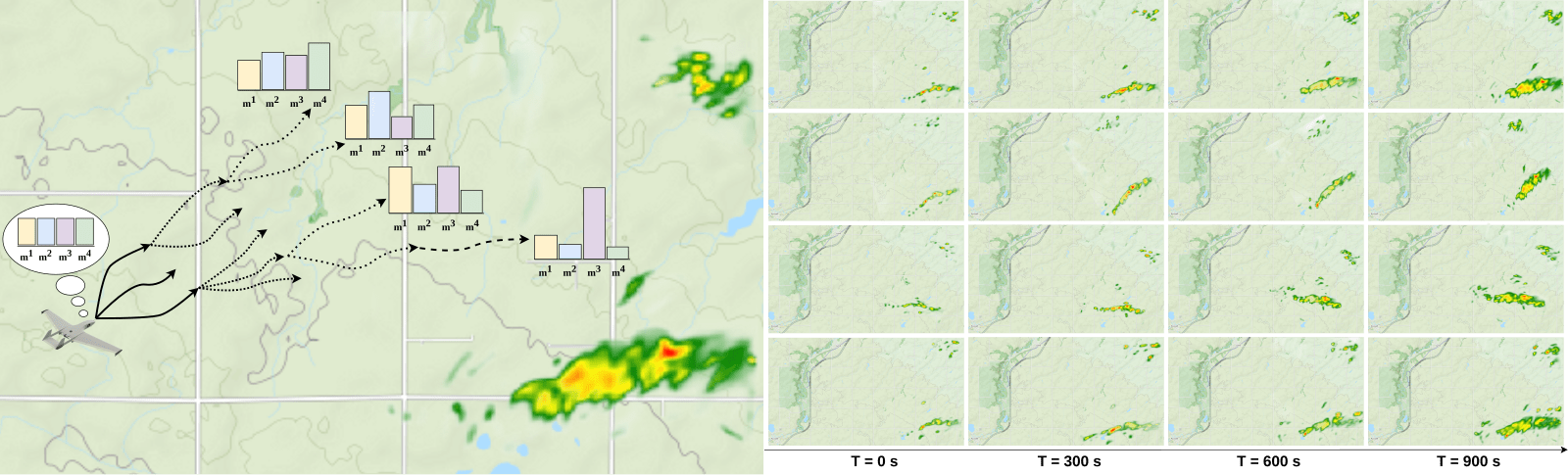
Example 2: Tornado Prediction
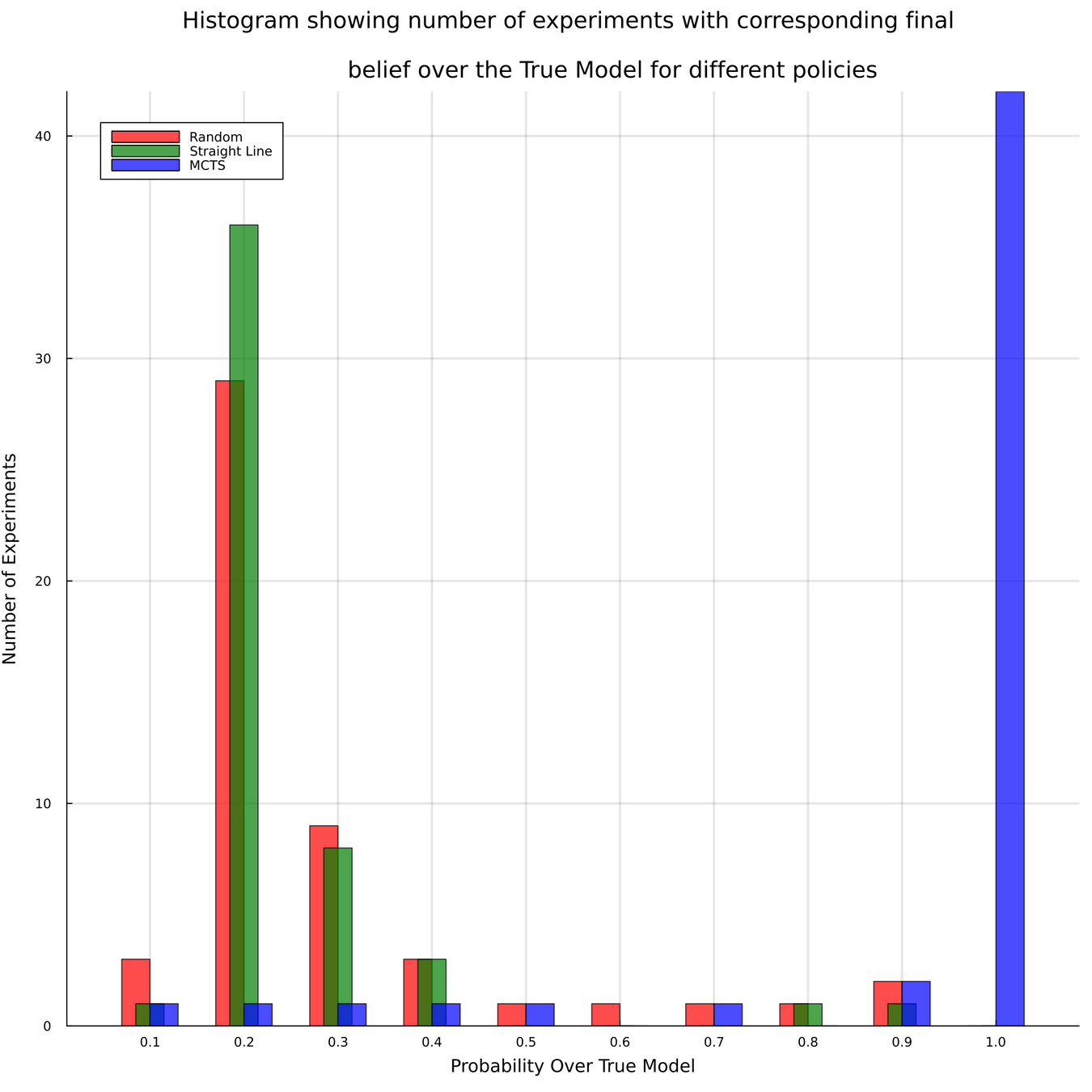
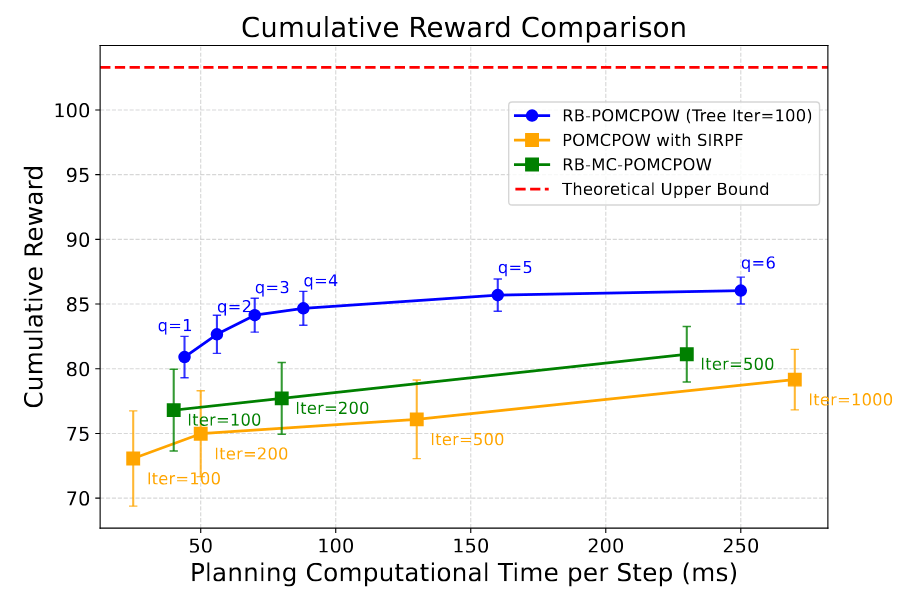
Rao-Blackwellized POMCPOW
- 30 ensemble members is not enough to capture the weather.
- Possible way forward: Rao-Blackwellize the particles
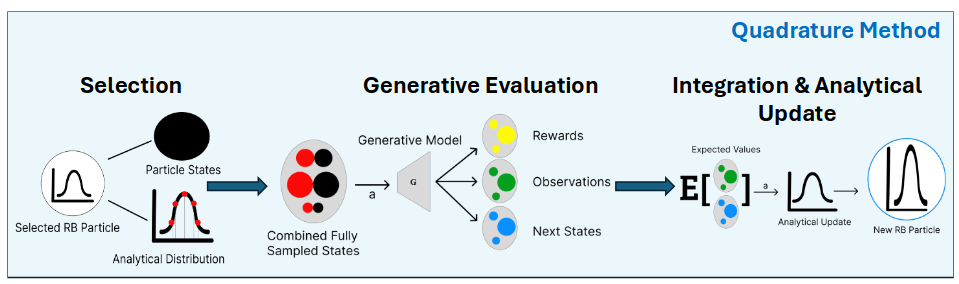
[Lee, Wray, Sunberg, Ahmed, ICRA 2026]
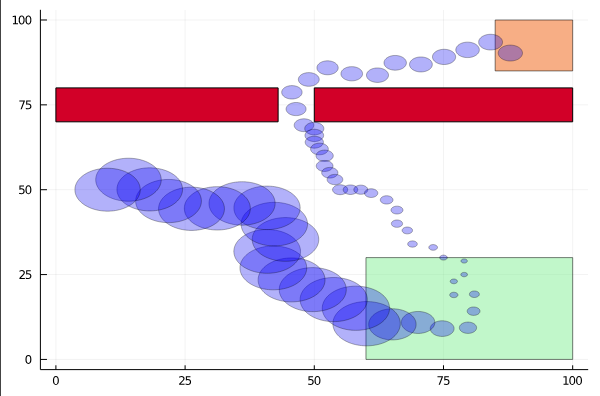
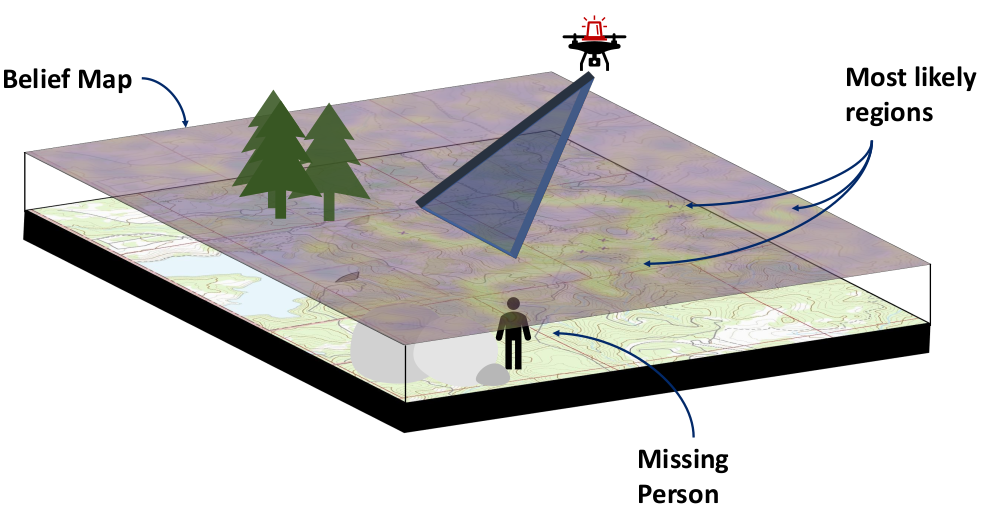
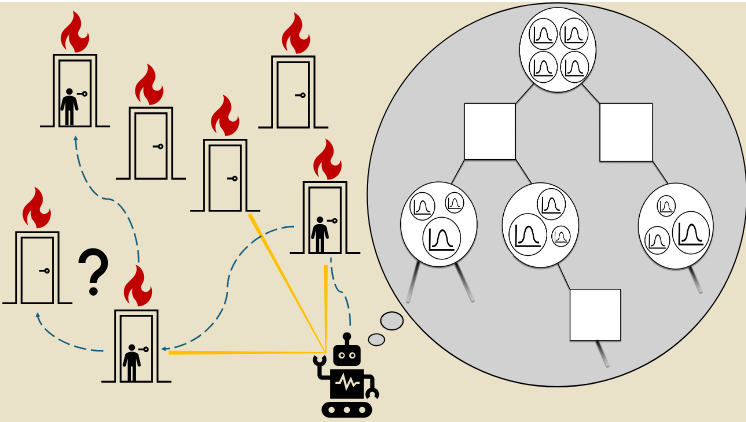
Example 3: Drone Search and Rescue
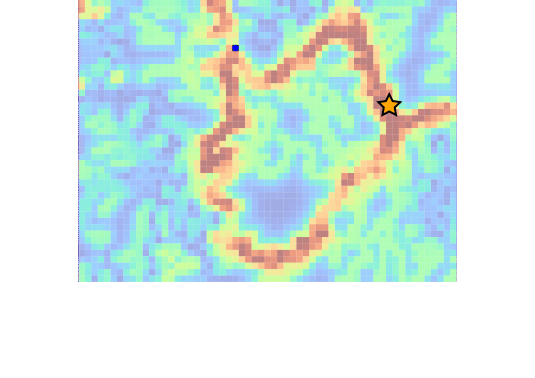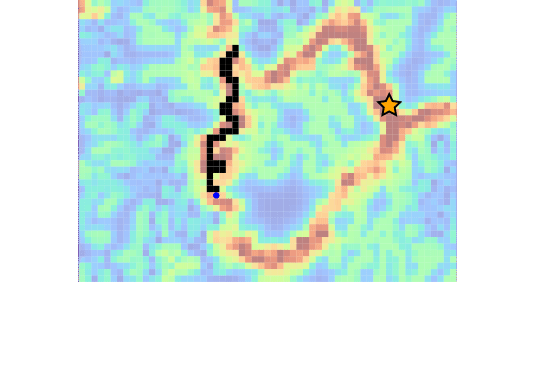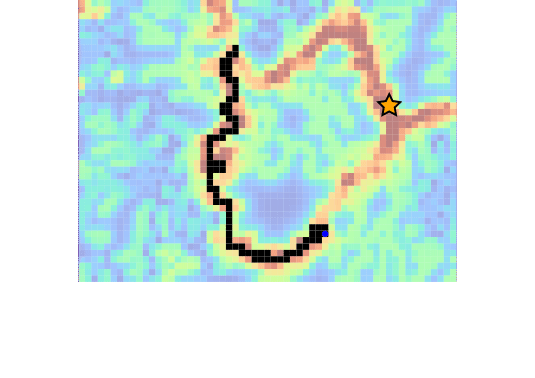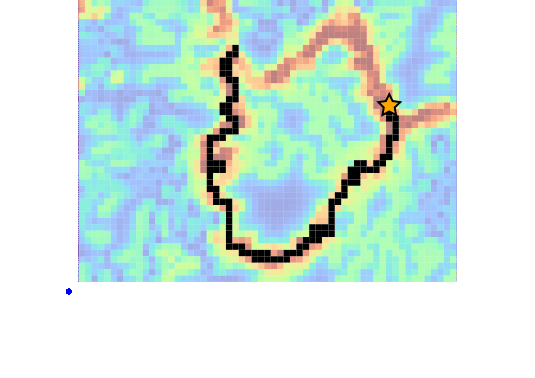
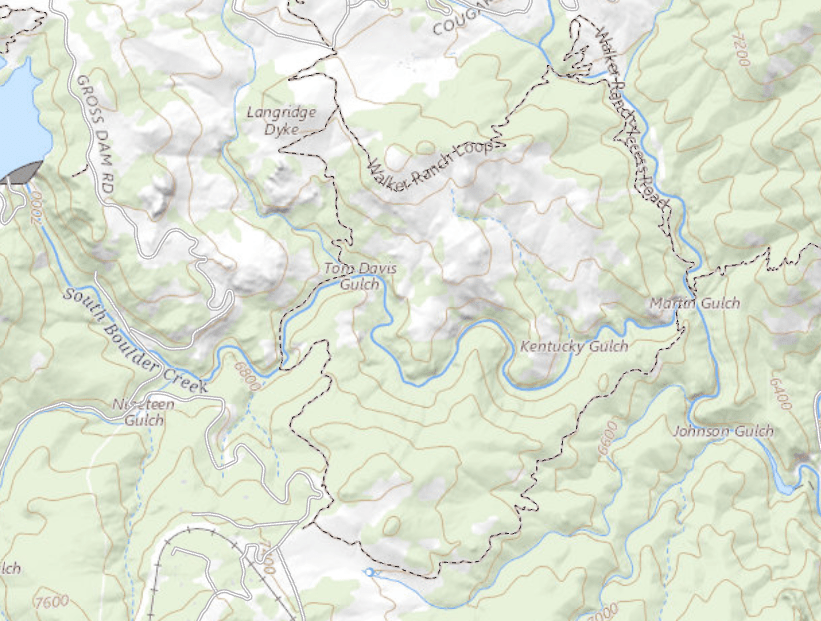
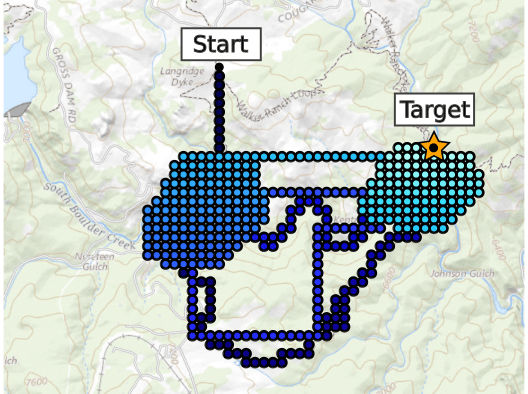


State:
- Location of Drone
- Location of Human
Baseline
Our POMDP Planner
[Ray, Laouar, Sunberg, & Ahmed, ICRA 2023]
Drone Search and Rescue



[Ray, Laouar, Sunberg, & Ahmed, ICRA 2023]


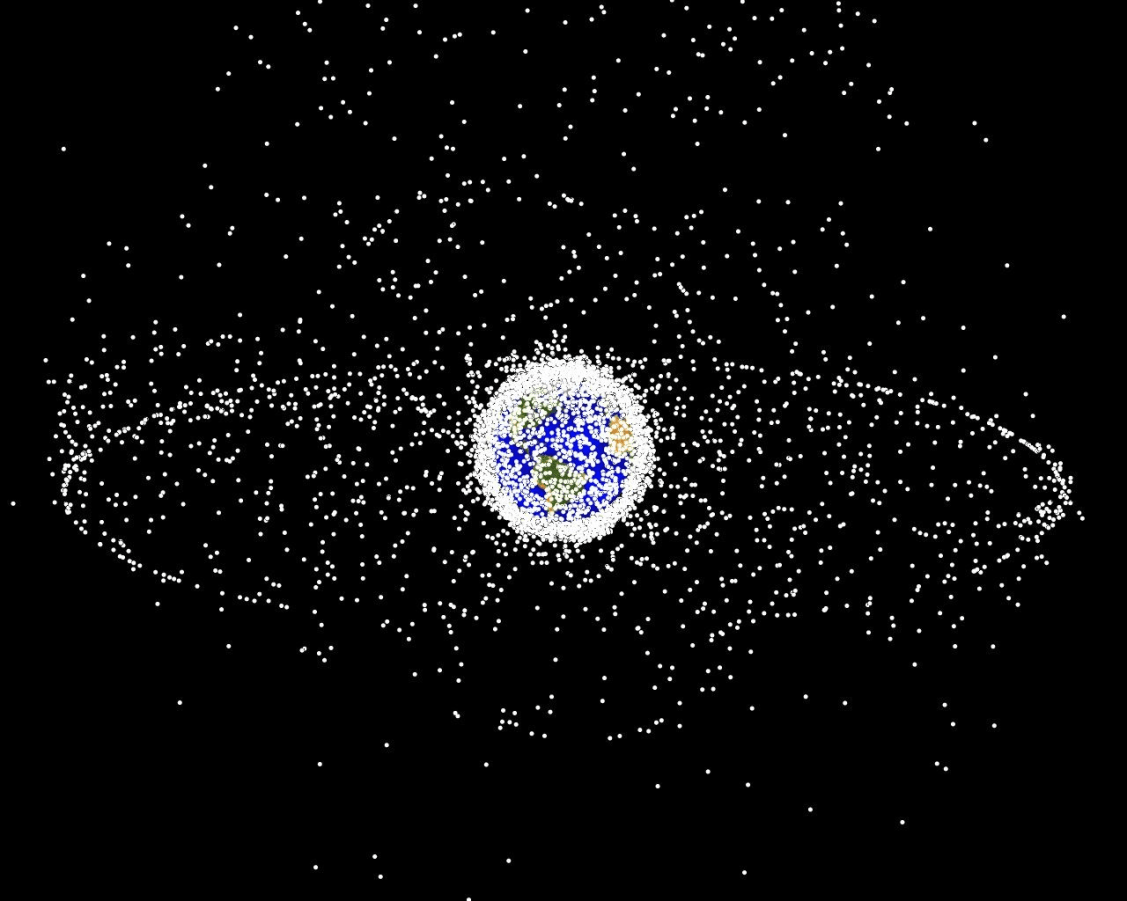
Space Domain Awareness

State:
- Position, velocity of object-of-interest
- Anomalies: navigation failure, suspicious maneuver, thruster failure, etc.
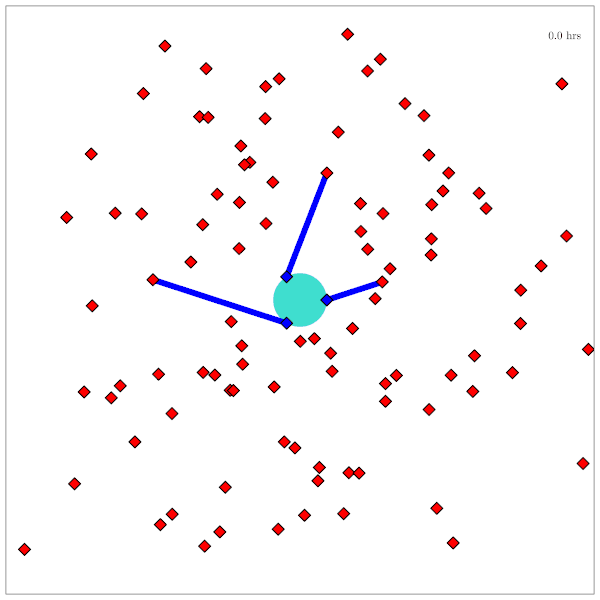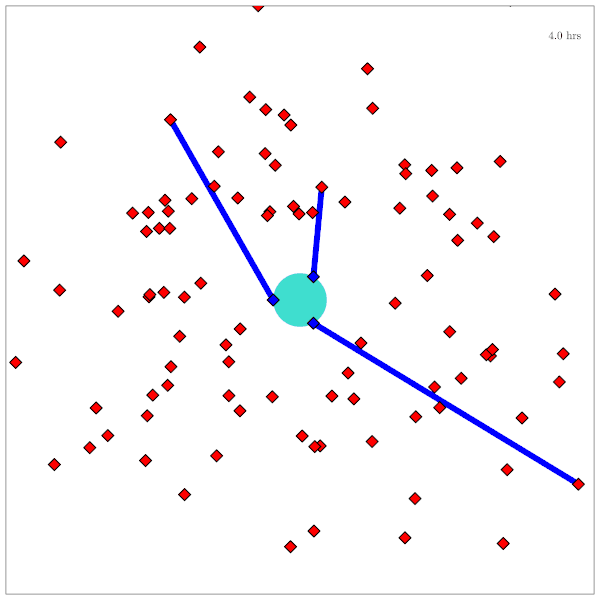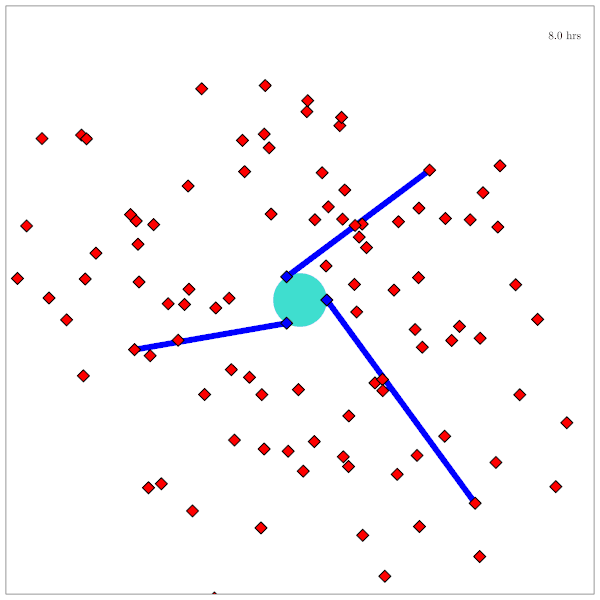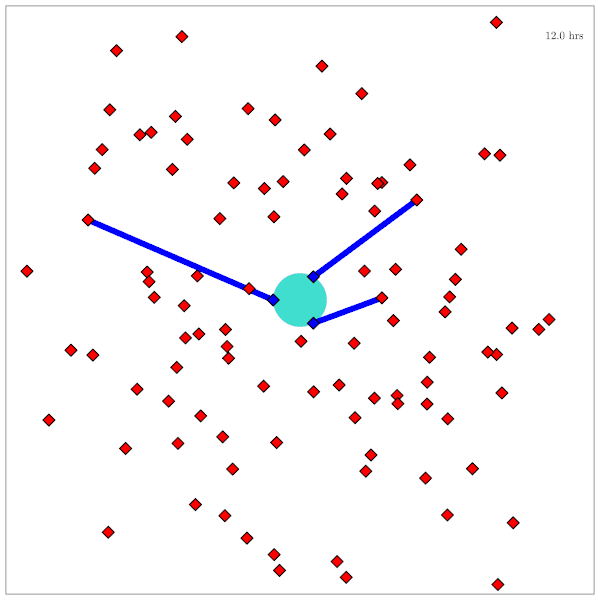
Catalog Maintenance Plan

[Dagan, Becker, & Sunberg, AMOS 2025]
Practical Safety Guarantees
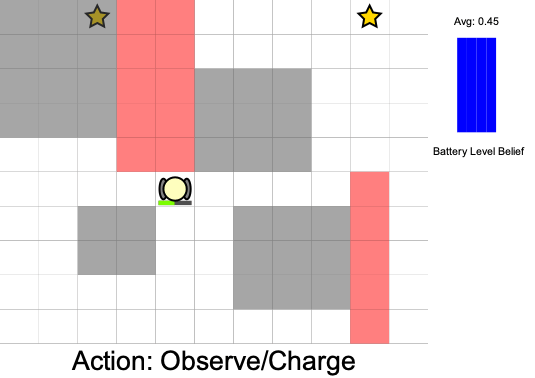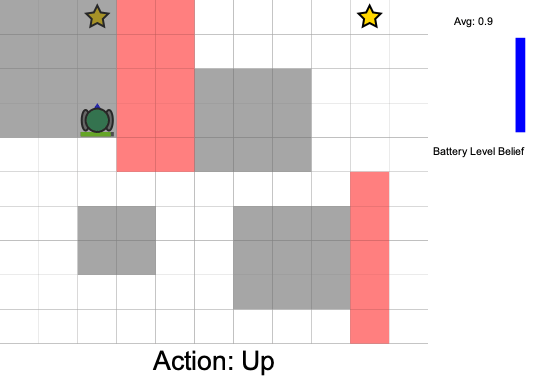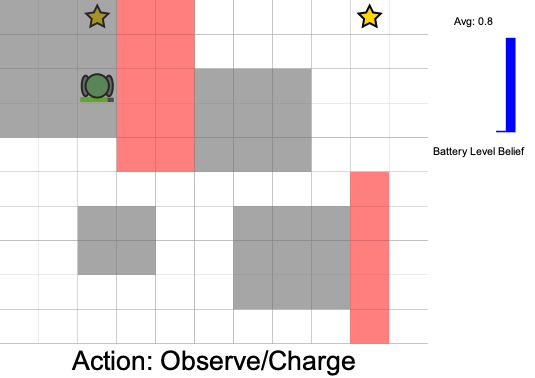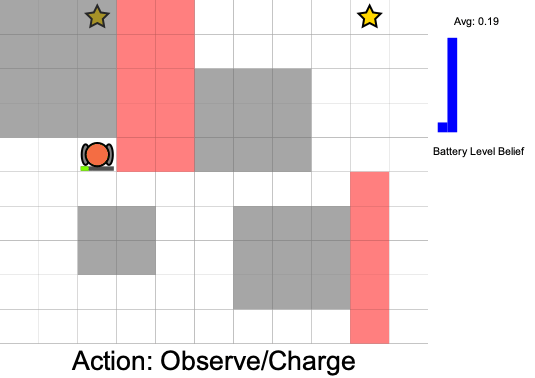
Three Contributions
- Recursive constraints (solves "stochastic self-destruction")
- Undiscounted POMDP solutions for estimating probability
- Much faster motion planning with Gaussian uncertainty


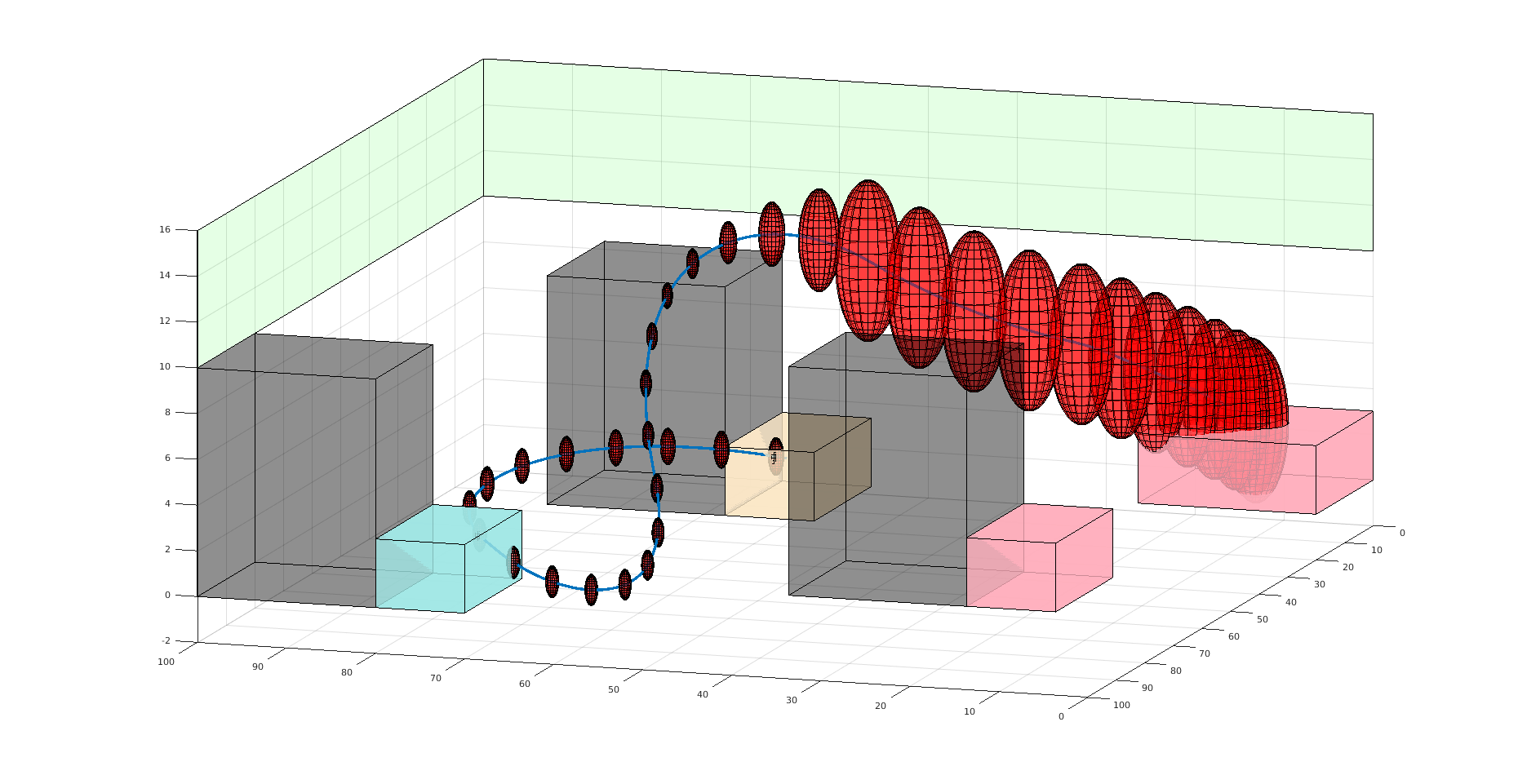
State:
- Position of rover
- Environment state: e.g. traversibility
- Internal status: e.g. battery, component health

[Ho et al., UAI 24], [Ho, Feather, Rossi, Sunberg, & Lahijanian, UAI 24], [Ho, Sunberg, & Lahijanian, ICRA 22]
Explainability: Reward Reconciliation

Calculate Outcomes
Calculate Weight Update
\( \frac{\epsilon - \alpha_a \cdot \Delta \mu_{h-a}}{\Delta\mu_{h-j} \cdot \Delta \mu_{h-a}} \Delta\mu_{h-j}\)
Estimate Weight with Update
\( \alpha[2]\)
\( \alpha[1]\)
\( a_{h}\) - optimal
\( a_{a}\) - optimal
\( \alpha_{h}\)
\( \alpha_{a}\)
\( R(s,a) = \alpha \cdot \boldsymbol{\phi}(s,a)\)
\(a_a\) outcomes: \(\mu_a\)
\(a_h\) outcomes: \(\mu_h\)
\(a_a\)
\(a_h\)
\( \hat{\alpha}_{h}\)
\(a_h\)
\(a_a\)
[Kraske, Saksena, Buczak, & Sunberg, ICAA 2024]
Multiple agents: How to be unpredictable
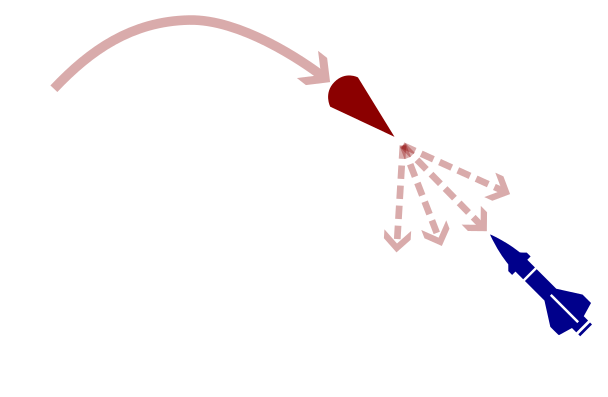
What is the best evader policy?
What is the best defender policy?
Depends on the best attacker policy?
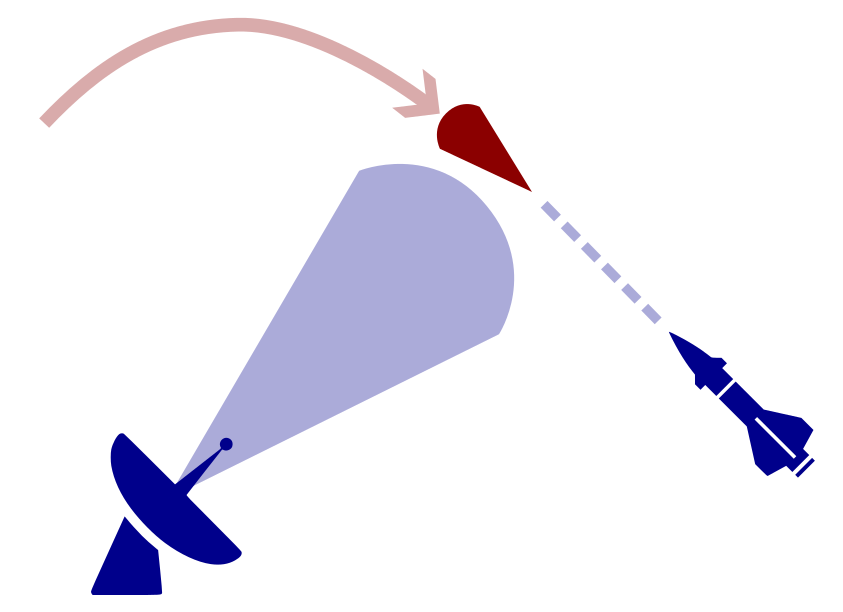
POSG Example: Missile Defense
POMDP Solution:
- Assume a distribution for the missile's actions
- Update belief according to this distribution
- Use a POMDP planner to find the best defensive action
Need some Game Theory!
Nash equilibrium: All players play a best response to the other players
A shrewd missile operator will use different actions, invalidating our belief
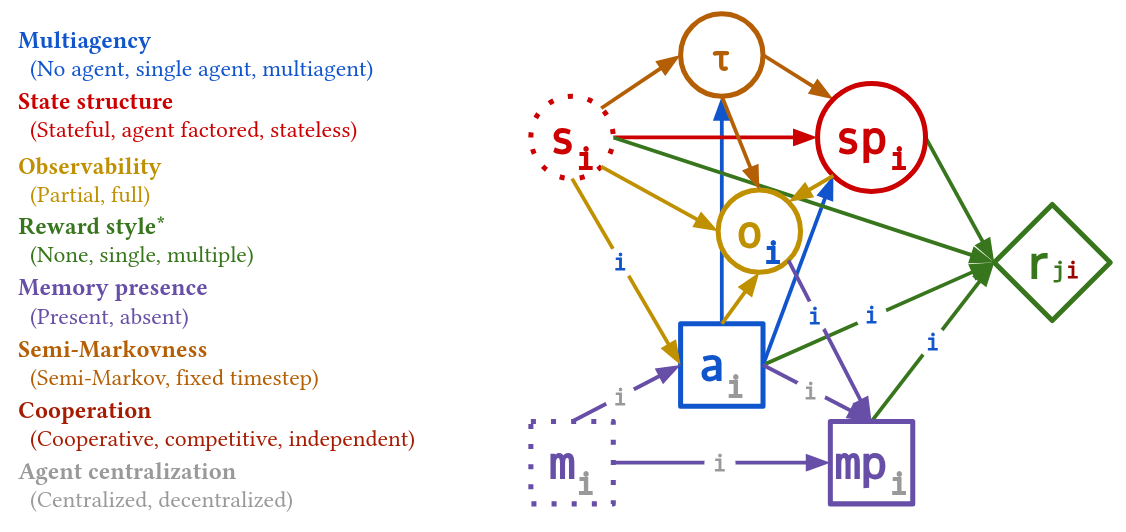
Partially Observable Stochastic Game (POSG)
Aleatory
Epistemic (Static)
Epistemic (Dynamic)
Strategic
- \(\mathcal{S}\) - State space
- \(T(s' \mid s, \bm{a})\) - Transition probability distribution
- \(\mathcal{A}^i, \, i \in 1..k\) - Action spaces
- \(R^i(s, \bm{a})\) - Reward function (cooperative, opposing, or somewhere in between)
- \(\mathcal{O}^i, \, i \in 1..k\) - Observation spaces
- \(Z(o^i \mid \bm{a}, s')\) - Observation probability distributions

Where has this been solved before?
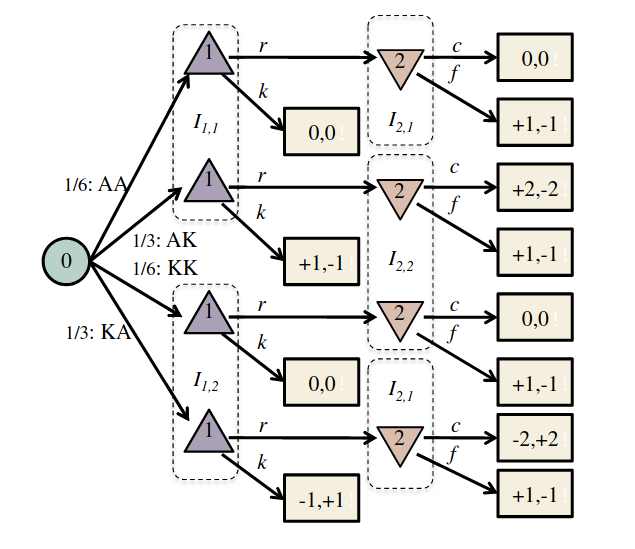
Image: Russel & Norvig, AI, a modern approach
P1: A
P1: K

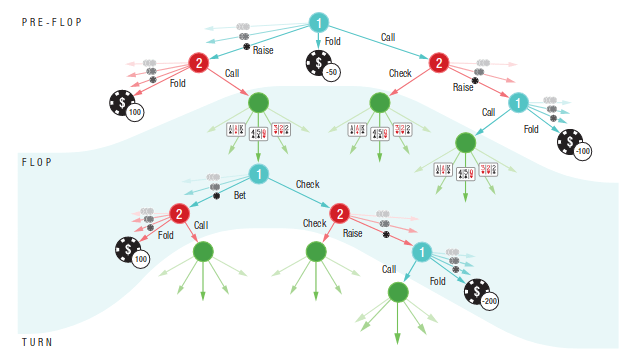
P2: A
P2: A
P2: K
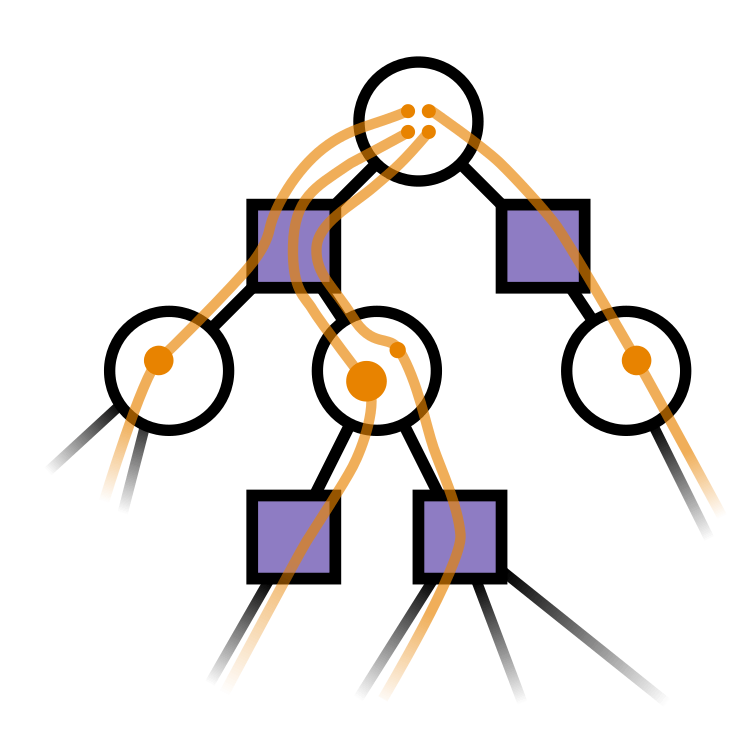
Conditional Distribution Info-Set Trees
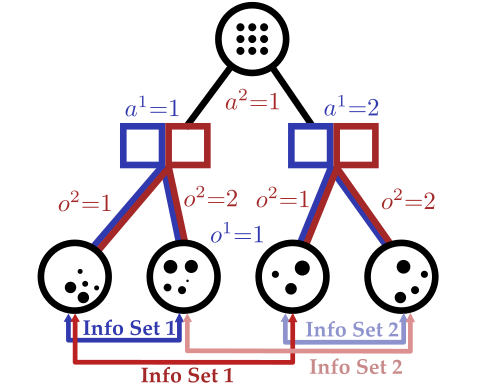
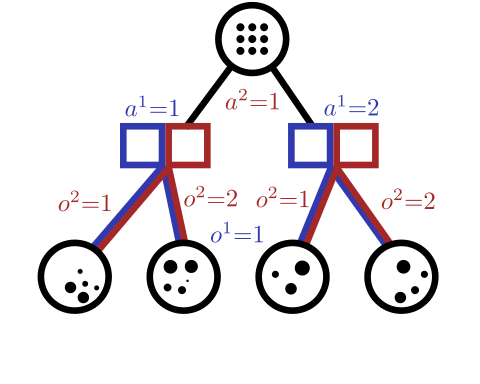
[Becker & Sunberg, AAMAS 2025 Short Paper]
Game Theory
Nash Equilibrium: All players play a best response.
Optimization Problem
(MDP or POMDP)
\(\text{maximize} \quad f(x)\)
Game
Player 1: \(U_1 (a_1, a_2)\)
Player 2: \(U_2 (a_1, a_2)\)
Collision
Example: Airborne Collision Avoidance
|
|
|
|
|
Player 1
Player 2
Up
Down
Up
Down
-6, -6
-1, 1
1, -1
-4, -4

Collision
Mixed Strategies
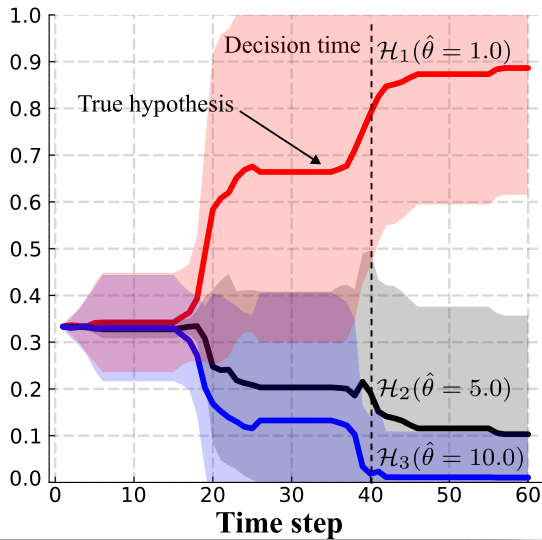
Nash Equilibrium \(\iff\) Zero Exploitability
\[\sum_i \max_{\pi_i'} U_i(\pi_i', \pi_{-i})\]
No Pure Nash Equilibrium!
Instead, there is a Mixed Nash where each player plays up or down with 50% probability.
If either player plays up or down more than 50% of the time, their strategy can be exploited.
Exploitability (zero sum):
Strategy (\(\pi_i\)): probability distribution over actions
|
|
|
|
|
Up
Down
Up
Down
-1, 1
1, -1
1, -1
-1, 1
Collision
Collision


Defending against Maneuverable Hypersonic Weapons: the Challenge
Ballistic
Maneuverable Hypersonic
- Sense
- Estimate
- Intercept
Every maneuver involves tradeoffs
- Energy
- Targets
- Intentions
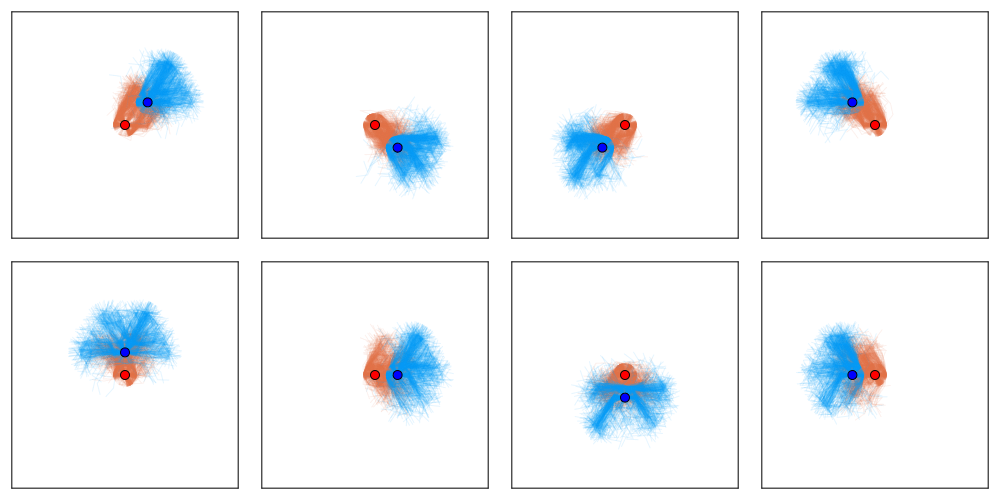
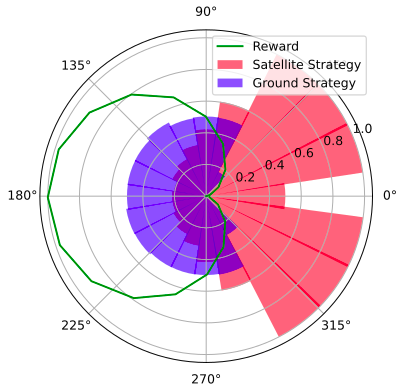
Simplified SDA Game

1
2
...
...
...
...
...
...
...
\(N\)
[Becker & Sunberg, AMOS 2022]
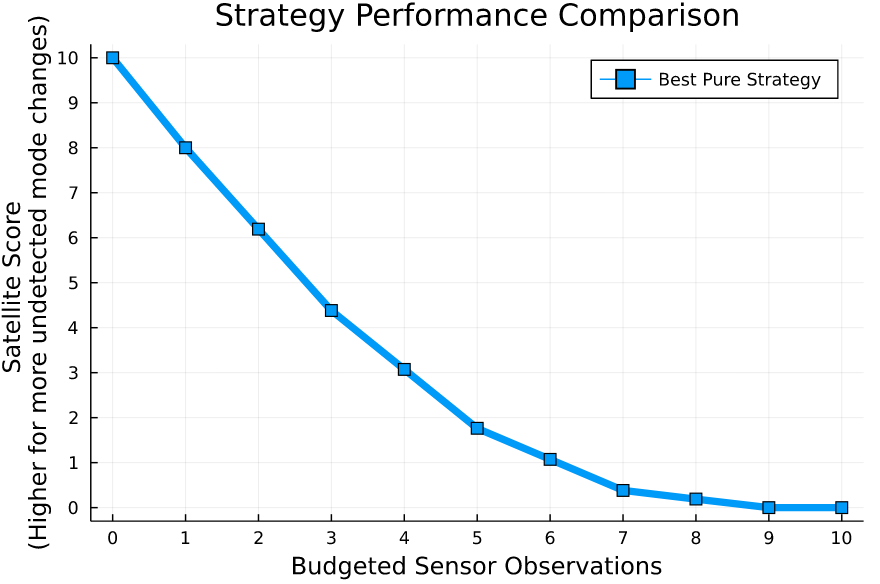
[Becker & Sunberg, AMOS 2022]
Counterfactual Regret Minimization Training
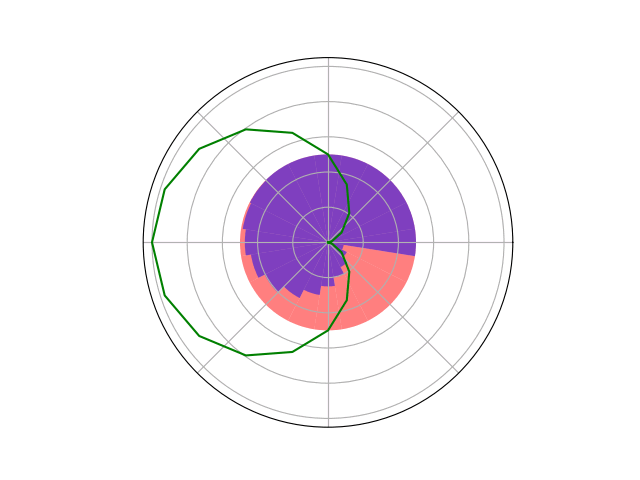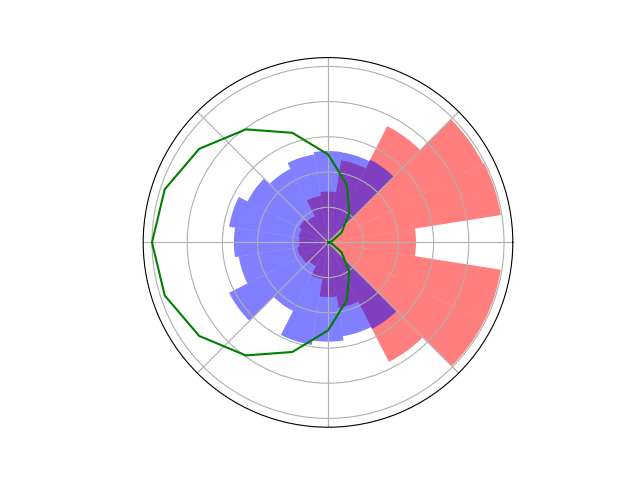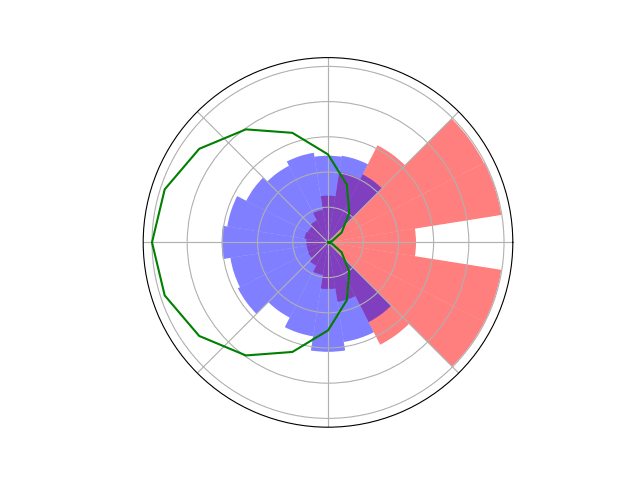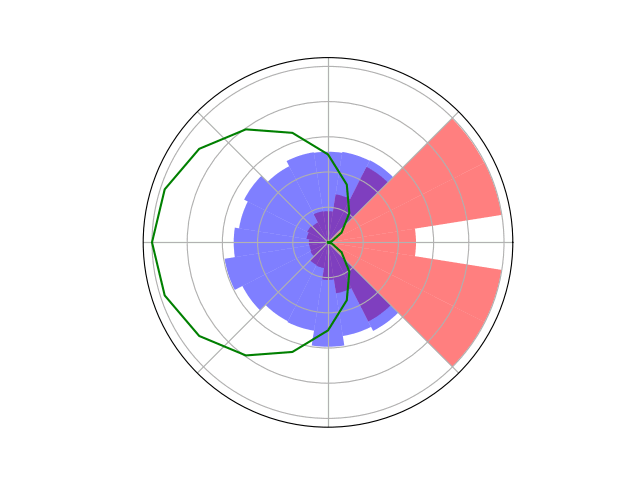
[Becker & Sunberg, AMOS 2022]
[Becker & Sunberg, AMOS 2022]
Simplified Missile Defense Game
|
|
|
|
|
Attacker
Defender
Up
Down
Up
Down
-1, 1
1, -1
1, -1
-1, 1
Collision
Collision
No Pure Nash Equilibrium!
Need a broader solution concept: Mixed Nash equilibrium (includes deceptive behavior like bluffing)
Nash equilibrium: All players play a best response to the other players
Tabletop Game 1: Go
Improvements Needed
- Simultaneous Play
- State Uncertainty


Policy Network
Value Network
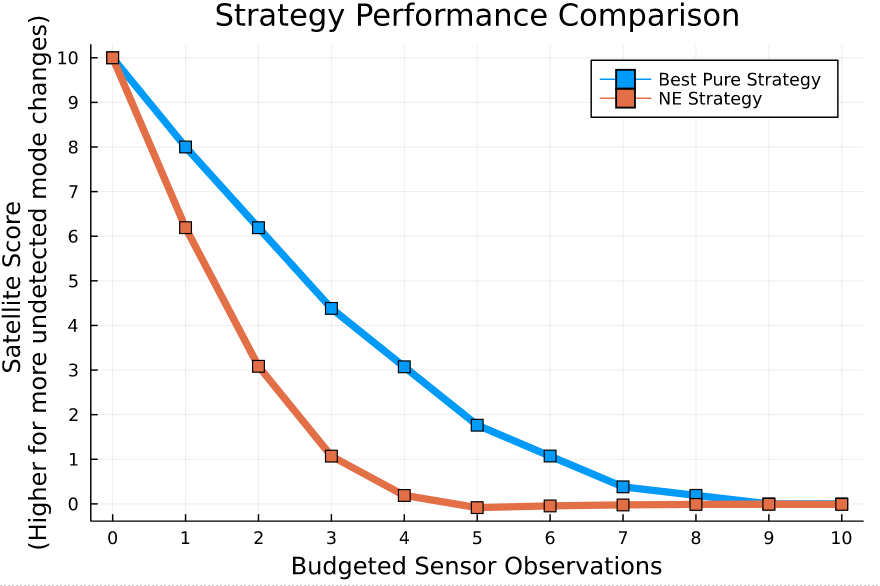
1. Simultaneous Play
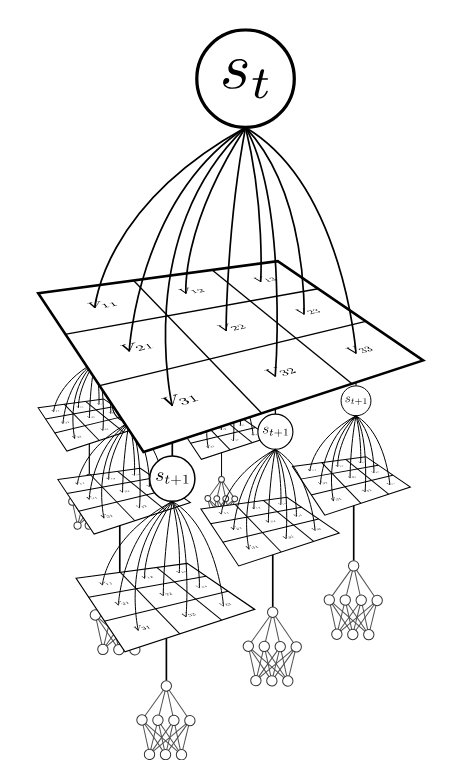
1. Exploration
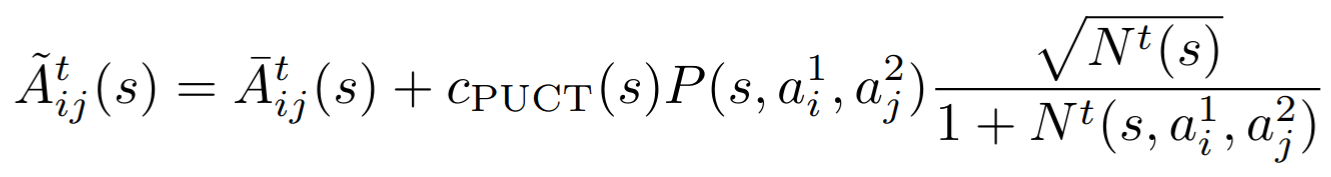
2. Selection
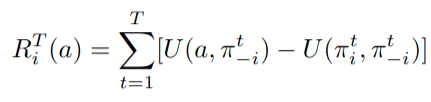
20 steps of regret matching on \(\tilde{A}\)
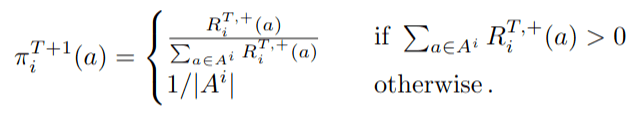
3. Networks
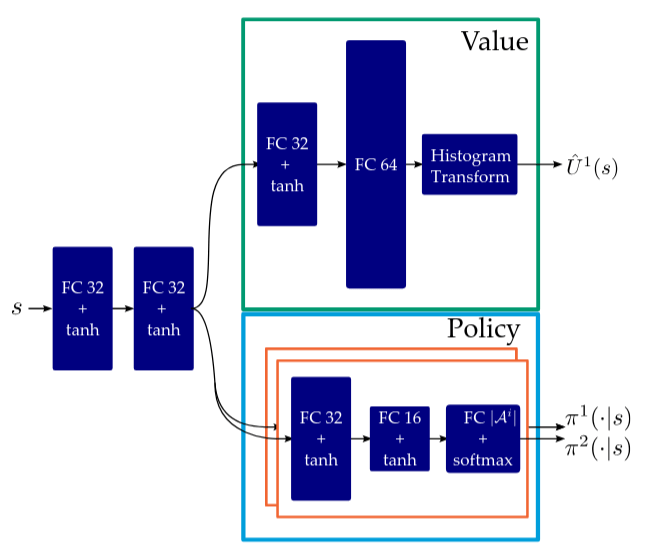
Policy trained to match solution to \(\bar{A}\)
Value distribution trained on sim outcomes
[Becker & Sunberg, AMOS 2025]
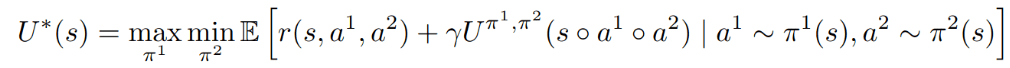
1. Simultaneous Play:
Space Domain Awareness
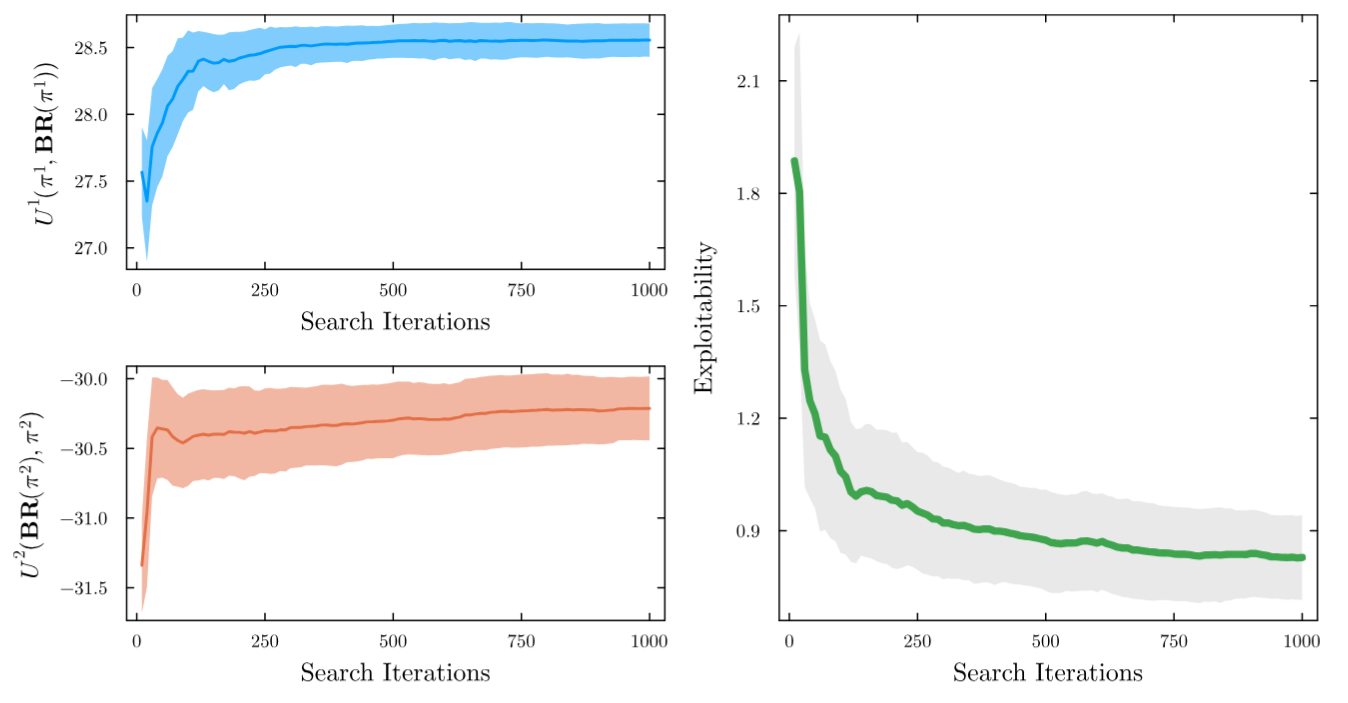
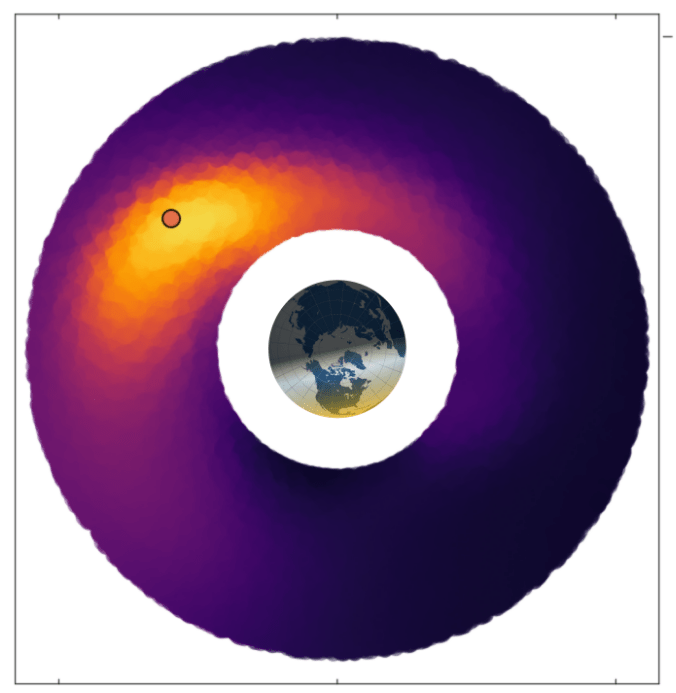
[Becker & Sunberg, AMOS 2025]
What about state uncertainty?
Conditional Distribution Info-Set Trees
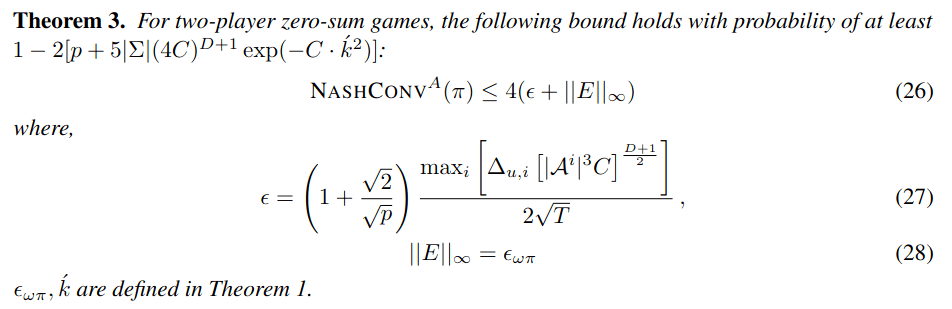
[Becker & Sunberg, AAMAS 2025 Short Paper]
Open Source Software!
[Krusniak et al. AAMAS 2026]
Decisions.jl
Arbitrary Dynamic Decision Networks

POMDPs.jl
using POMDPs, QuickPOMDPs, POMDPTools, QMDP
m = QuickPOMDP(
states = ["left", "right"],
actions = ["left", "right", "listen"],
observations = ["left", "right"],
initialstate = Uniform(["left", "right"]),
discount = 0.95,
transition = function (s, a)
if a == "listen"
return Deterministic(s)
else # a door is opened
return Uniform(["left", "right"]) # reset
end
end,
observation = function (s, a, sp)
if a == "listen"
if sp == "left"
return SparseCat(["left", "right"], [0.85, 0.15])
else
return SparseCat(["right", "left"], [0.85, 0.15])
end
else
return Uniform(["left", "right"])
end
end,
reward = function (s, a)
if a == "listen"
return -1.0
elseif s == a # the tiger was found
return -100.0
else # the tiger was escaped
return 10.0
end
end
)
solver = QMDPSolver()
policy = solve(solver, m)Thank You!







Funding orgs: (all opinions are my own)



Part V: Open Source Research Software
Good Examples
- Open AI Gym interface
- OMPL
- ROS
Challenges for POMDP Software
- There is a huge variety of
- Problems
- Continuous/Discrete
- Fully/Partially Observable
- Generative/Explicit
- Simple/Complex
- Solvers
- Online/Offline
- Alpha Vector/Graph/Tree
- Exact/Approximate
- Domain-specific heuristics
- Problems
- POMDPs are computationally difficult.
Explicit
Black Box
("Generative" in POMDP lit.)

\(s,a\)
\(s', o, r\)
Previous C++ framework: APPL
"At the moment, the three packages are independent. Maybe one day they will be merged in a single coherent framework."
Open Source Research Software
- Performant
- Flexible and Composable
- Free and Open
- Easy for a wide range of people to use (for homework)
- Easy for a wide range of people to understand
C++
Python, C++
Python, Matlab
Python, Matlab
Python, C++
2013
We love [Matlab, Lisp, Python, Ruby, Perl, Mathematica, and C]; they are wonderful and powerful. For the work we do — scientific computing, machine learning, data mining, large-scale linear algebra, distributed and parallel computing — each one is perfect for some aspects of the work and terrible for others. Each one is a trade-off.
We are greedy: we want more.
2012
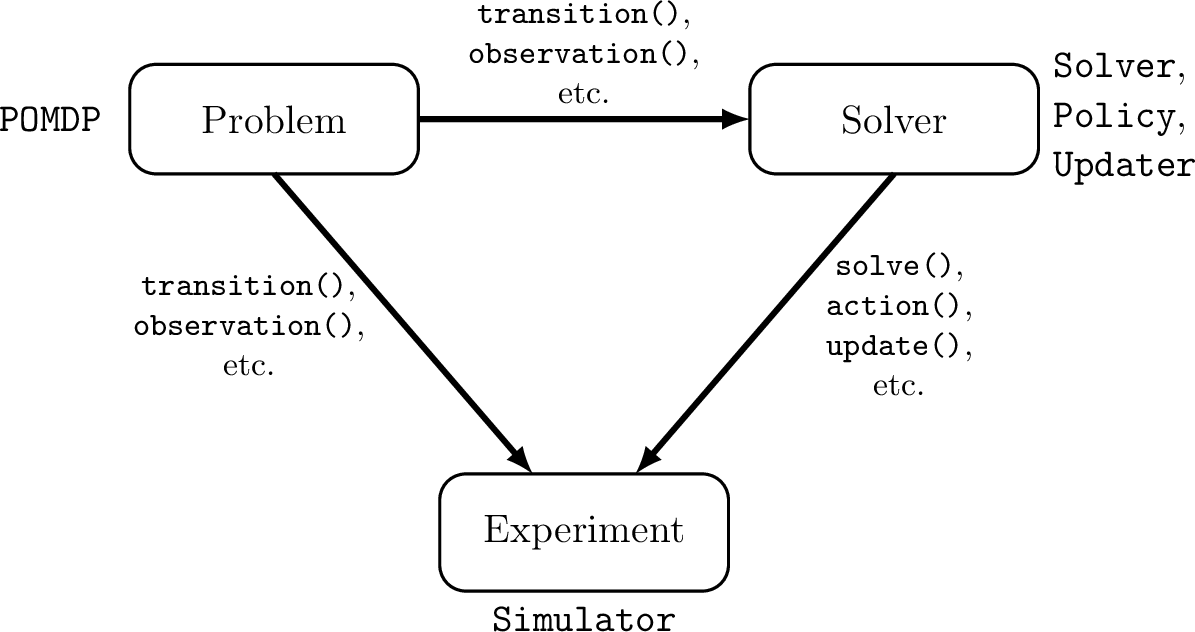
POMDPs.jl - An interface for defining and solving MDPs and POMDPs in Julia

Mountain Car
partially_observable_mountaincar = QuickPOMDP(
actions = [-1., 0., 1.],
obstype = Float64,
discount = 0.95,
initialstate = ImplicitDistribution(rng -> (-0.2*rand(rng), 0.0)),
isterminal = s -> s[1] > 0.5,
gen = function (s, a, rng)
x, v = s
vp = clamp(v + a*0.001 + cos(3*x)*-0.0025, -0.07, 0.07)
xp = x + vp
if xp > 0.5
r = 100.0
else
r = -1.0
end
return (sp=(xp, vp), r=r)
end,
observation = (a, sp) -> Normal(sp[1], 0.15)
)using POMDPs
using QuickPOMDPs
using POMDPPolicies
using Compose
import Cairo
using POMDPGifs
import POMDPModelTools: Deterministic
mountaincar = QuickMDP(
function (s, a, rng)
x, v = s
vp = clamp(v + a*0.001 + cos(3*x)*-0.0025, -0.07, 0.07)
xp = x + vp
if xp > 0.5
r = 100.0
else
r = -1.0
end
return (sp=(xp, vp), r=r)
end,
actions = [-1., 0., 1.],
initialstate = Deterministic((-0.5, 0.0)),
discount = 0.95,
isterminal = s -> s[1] > 0.5,
render = function (step)
cx = step.s[1]
cy = 0.45*sin(3*cx)+0.5
car = (context(), circle(cx, cy+0.035, 0.035), fill("blue"))
track = (context(), line([(x, 0.45*sin(3*x)+0.5) for x in -1.2:0.01:0.6]), stroke("black"))
goal = (context(), star(0.5, 1.0, -0.035, 5), fill("gold"), stroke("black"))
bg = (context(), rectangle(), fill("white"))
ctx = context(0.7, 0.05, 0.6, 0.9, mirror=Mirror(0, 0, 0.5))
return compose(context(), (ctx, car, track, goal), bg)
end
)
energize = FunctionPolicy(s->s[2] < 0.0 ? -1.0 : 1.0)
makegif(mountaincar, energize; filename="out.gif", fps=20)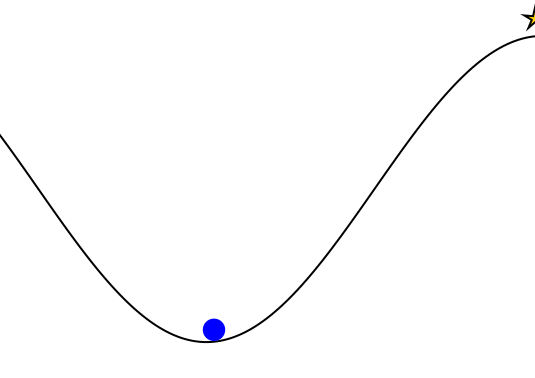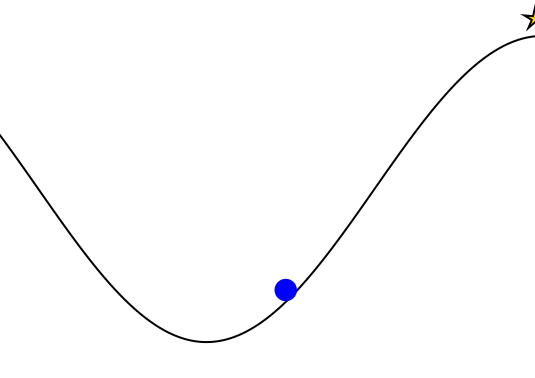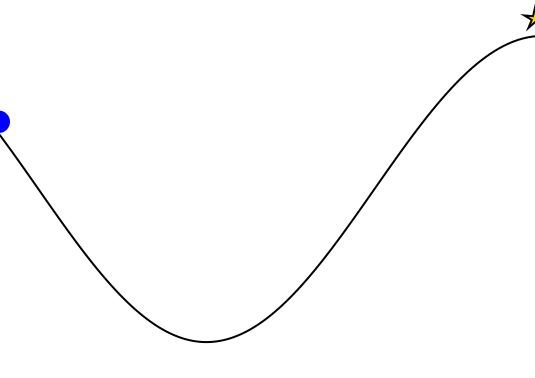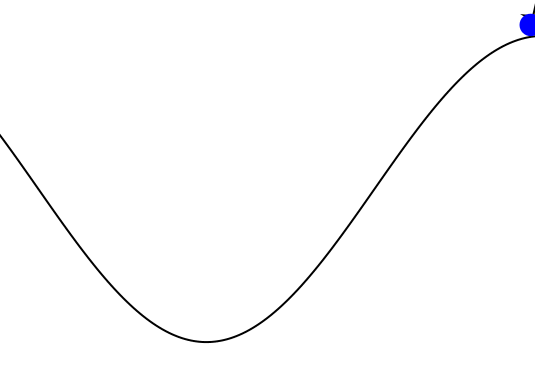


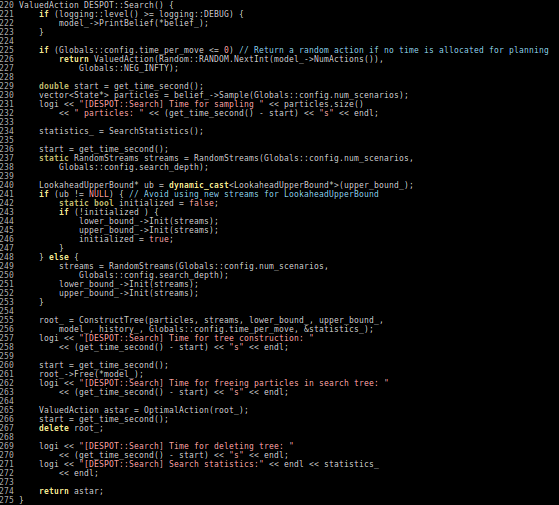
POMDP Planning with Learned Components
[Deglurkar, Lim, Sunberg, & Tomlin, 2023]
Continuous \(A\): BOMCP


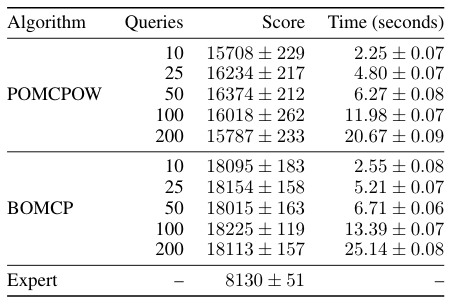
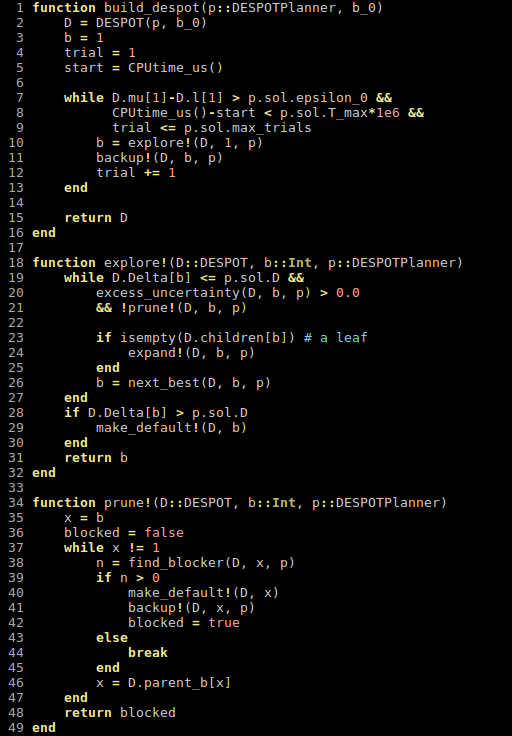
[Mern, Sunberg, et al. AAAI 2021]
Continuous \(A\): Voronoi Progressive Widening
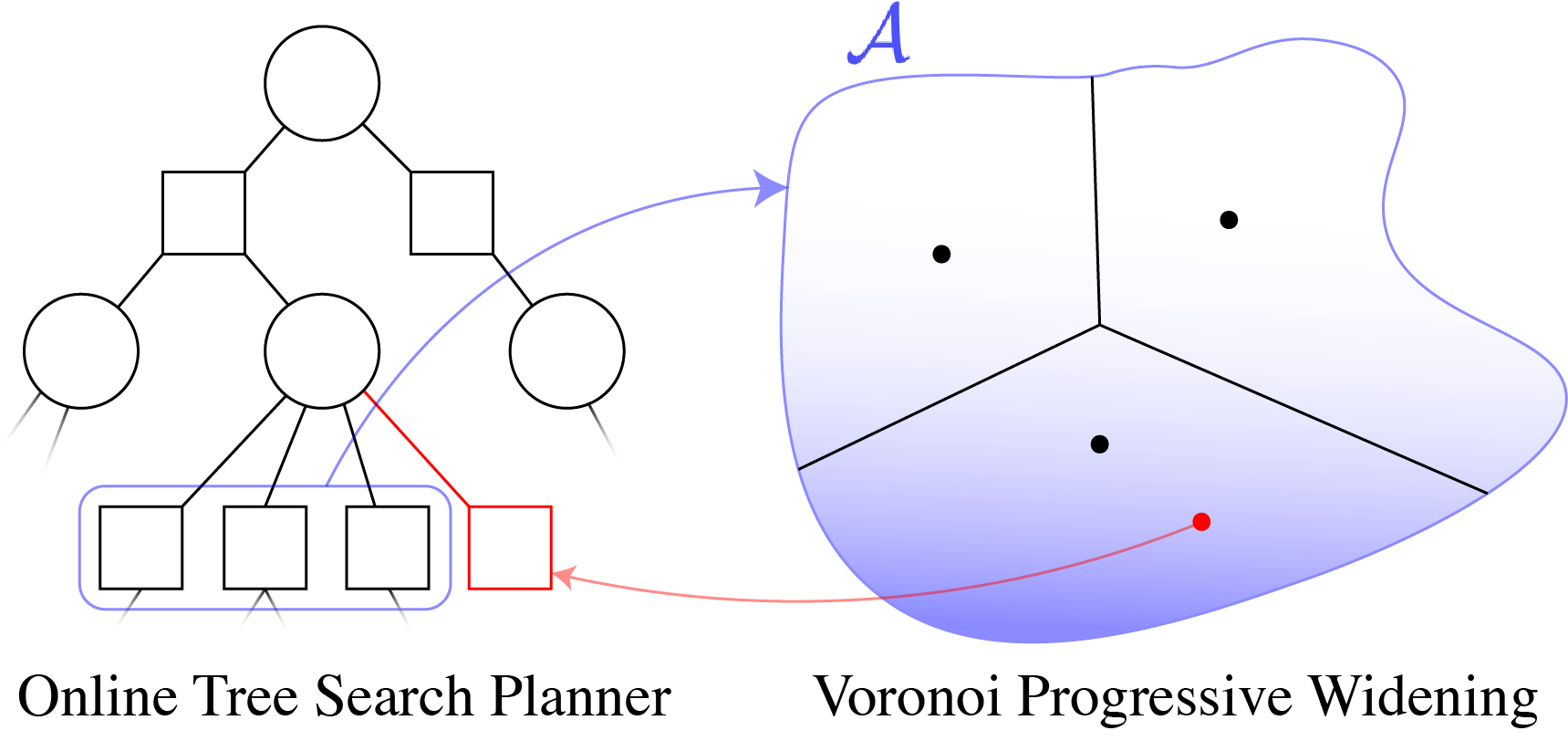
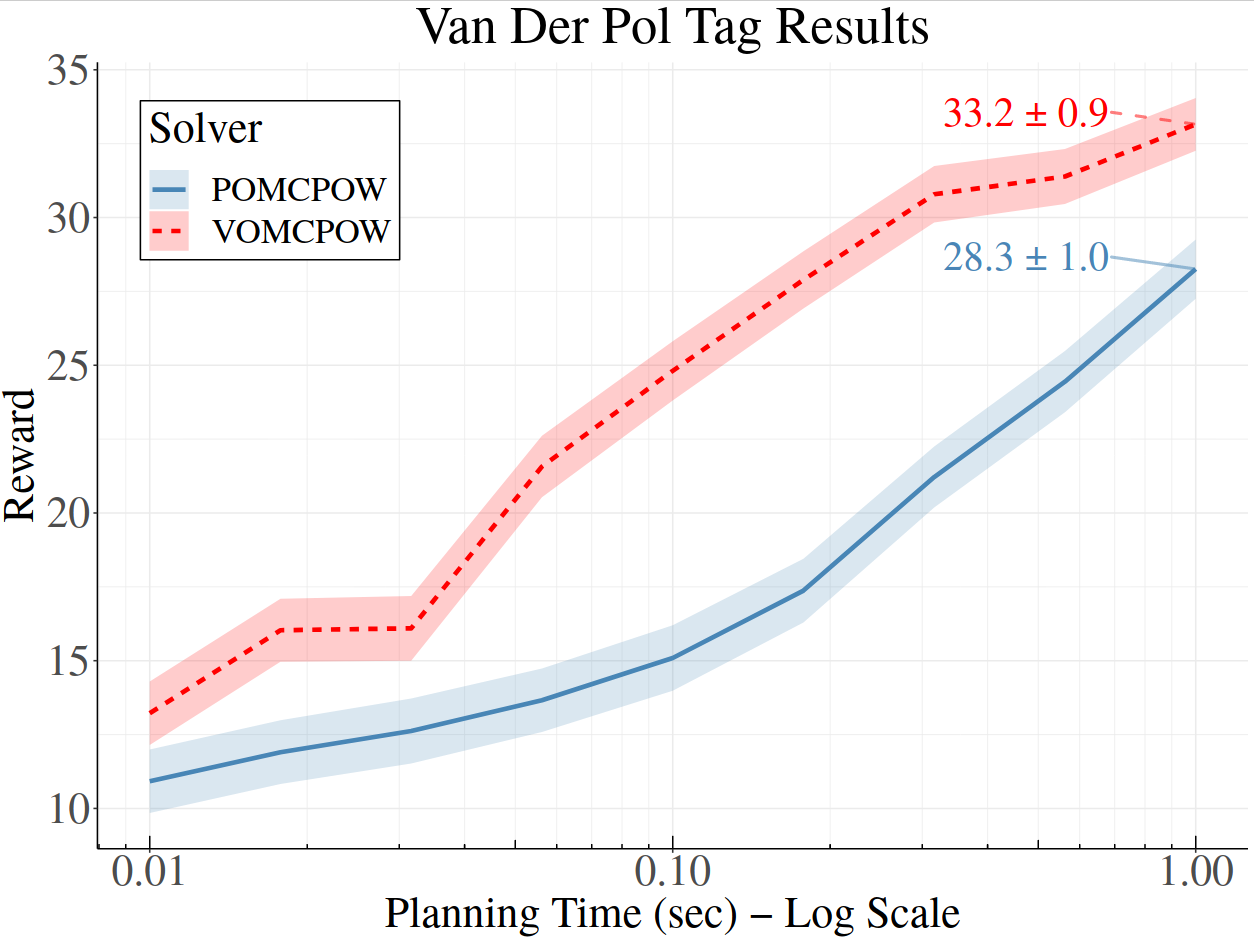

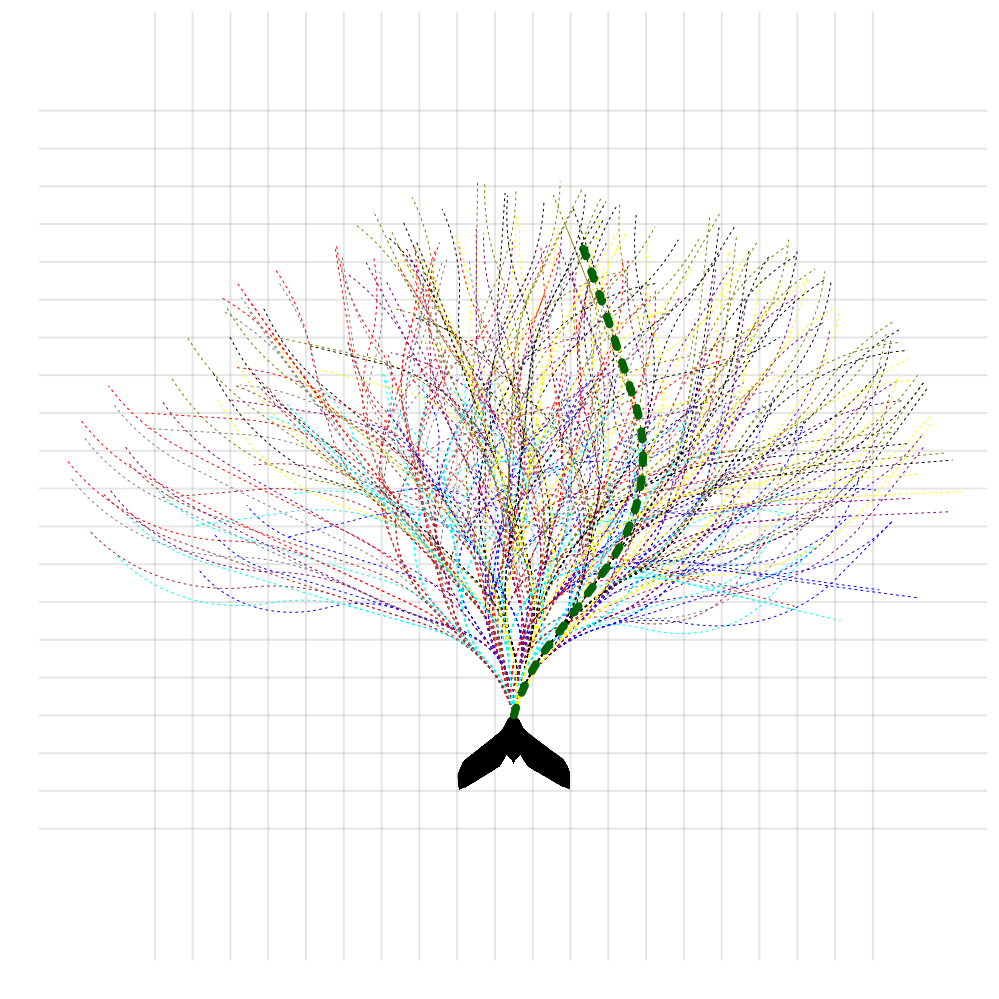
[Lim, Tomlin, & Sunberg CDC 2021]
Storm Science
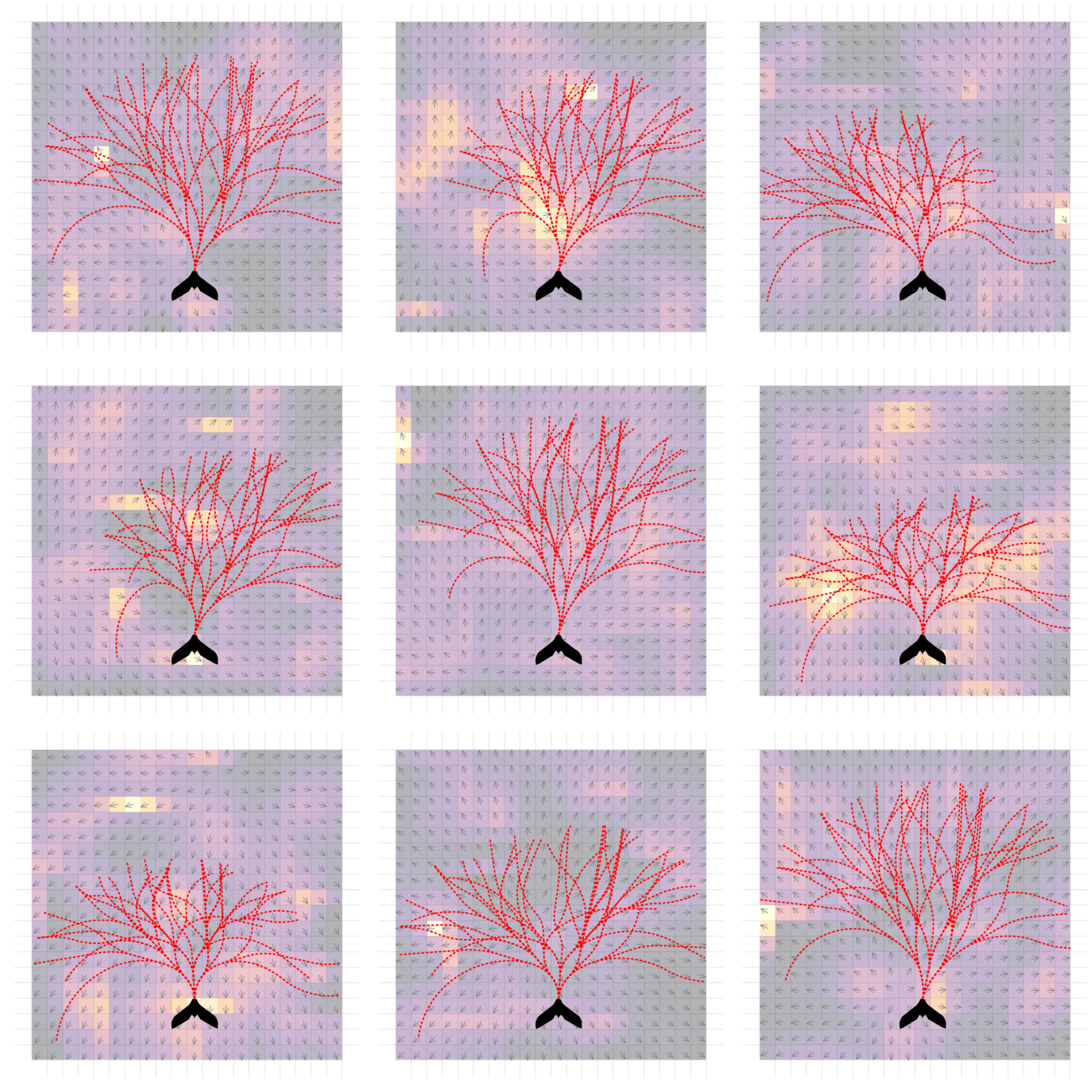
Human Behavior Model: IDM and MOBIL
\ddot{x}_\text{IDM} = a \left[ 1 - \left( \frac{\dot{x}}{\dot{x}_0} \right)^{\delta} - \left(\frac{g^*(\dot{x}, \Delta \dot{x})}{g}\right)^2 \right]
g^*(\dot{x}, \Delta \dot{x}) = g_0 + T \dot{x} + \frac{\dot{x}\Delta \dot{x}}{2 \sqrt{a b}}

M. Treiber, et al., “Congested traffic states in empirical observations and microscopic simulations,” Physical Review E, vol. 62, no. 2 (2000).
A. Kesting, et al., “General lane-changing model MOBIL for car-following models,” Transportation Research Record, vol. 1999 (2007).
A. Kesting, et al., "Agents for Traffic Simulation." Multi-Agent Systems: Simulation and Applications. CRC Press (2009).





All drivers normal




Omniscient
Mean MPC
QMDP
POMCPOW
RSS Short Talk
By Zachary Sunberg




