Value-Based Model Free RL
Last Time
- Policy Optimization
- Policy Gradient
- Tricks for Policy Gradient
Map
Today
- Basic On- and Off-Policy value based model free RL algorithms
- Tricks for tabular value based RL algorithms
- Understanding of On- vs Off-Policy
Why learn Q?
Incremental Mean Estimation
\[\hat{x}_m = \frac{1}{m} \sum_{i=1}^m x^{(i)}\]
\[= \frac{1}{m} \left( x^{(m)} + \sum_{i=1}^{m-1} x^{(i)} \right)\]
\[= \frac{1}{m} \left( x^{(m)} + (m-1) \, \hat{x}_{m-1} \right)\]
\[= \hat{x}_{m-1} + \frac{1}{m} \left( x^{(m)} - \hat{x}_{m-1} \right)\]
loop
\[\hat{x} \gets \hat{x} + \alpha \left( x - \hat{x} \right)\]

"Temporal Difference (TD) Error"
Q Learning
Q Learning
Want: \(Q(s, a) \gets Q(s, a) + \alpha \left(\hat{q} - Q(s, a)\right)\)
Want: \(Q(s, a) \gets Q(s, a) + \alpha \left(\hat{q}(s, a, r, s') - Q(s, a)\right)\)
\[Q(s, a) = R(s, a) + \gamma E[V(s')]\]
\[= R(s, a) + \gamma E\left[\max_{a'} Q(s', a')\right]\]
\[= E\left[r + \gamma \max_{a'} Q(s', a')\right]\]
Q learning and SARSA
\(Q(s, a) \gets 0\)
\(s \gets s_0\)
loop
\(a \gets \text{argmax} \, Q(s, a) \, \text{w.p.} \, 1-\epsilon, \quad \text{rand}(A) \, \text{o.w.}\)
\(r \gets \text{act!}(\text{env}, a)\)
\(s' \gets \text{observe}(\text{env})\)
\(Q(s, a) \gets Q(s, a) + \alpha\, \left(r + \gamma \max_{a'} Q(s', a') - Q(s, a)\right)\)
\(s \gets s'\)
Q-Learning
SARSA
Q-learning: \(Q(s, a) \gets Q(s, a) + \alpha\, \left(r + \gamma \max_{a'} Q(s', a') - Q(s, a)\right)\)
SARSA: \(Q(s, a) \gets Q(s, a) + \alpha\, \left(r + \gamma Q(s', a') - Q(s, a)\right)\)
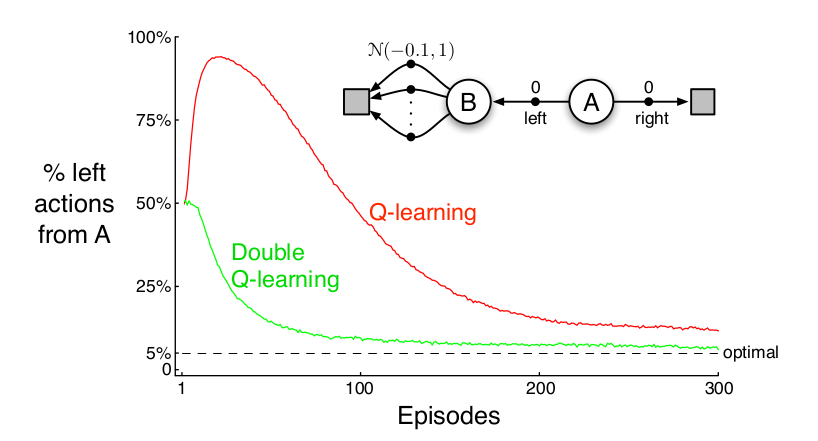
Illustrative Problem
- After a few episodes, what is Q(3, a) for a in 1-4?
- After a few episodes, what is Q(1, L)?
- Why is this a problem and what are some possible solutions?
Big Problem: Maximization Bias
Even if all \(Q(s', a')\) unbiased, \(\max_{a'} Q(s', a')\) is biased!
Solution: Double Q Learning
\(Q_1\), \(Q_2\)
\[Q_1(s, a) \gets Q_1(s, a) + \alpha\, \left(r + \gamma \, Q_2\left(s', \underset{a'}{\text{argmax}} Q_1(s', a')\right) - Q_1(s, a)\right)\]
Eligibility Traces
SARSA-λ
\(Q(s, a), N(s, a) \gets 0\)
\(\text{initialize}\, s, a, r, s'\)
loop
\(a' \gets \text{argmax} \, Q(s', a) \, \text{w.p.} \, 1-\epsilon, \quad \text{rand}(A) \, \text{o.w.}\)
\(N(s, a) \gets N(s, a) + 1\)
\(\delta \gets r + \gamma Q(s', a') - Q(s, a)\)
\(Q(s, a) \gets Q(s, a) + \alpha\delta \, N(s, a) \quad \forall s, a\)
\(N(s, a) \gets \gamma \lambda N(s, a)\)
\(s \gets s'\), \(a \gets a'\)
\(r \gets \text{act!}(\text{env}, a)\)
\(s' \gets \text{observe}(\text{env})\)
SARSA-λ

\(Q(s, a), N(s, a) \gets 0\)
\(\text{initialize}\, s, a, r, s'\)
loop
\(a' \gets \text{argmax} \, Q(s', a) \, \text{w.p.} \, 1-\epsilon, \quad \text{rand}(A) \, \text{o.w.}\)
\(N(s, a) \gets N(s, a) + 1\)
\(\delta \gets r + \gamma Q(s', a') - Q(s, a)\)
\(Q(s, a) \gets Q(s, a) + \alpha\delta \, N(s, a) \quad \forall s, a\)
\(N(s, a) \gets \gamma \lambda N(s, a)\)
\(s \gets s'\), \(a \gets a'\)
\(r \gets \text{act!}(\text{env}, a)\)
\(s' \gets \text{observe}(\text{env})\)
Convergence
- Q learning converges to optimal Q-values w.p. 1
(Sutton and Barto, p. 131) - SARSA converges to optimal Q-values w.p. 1 provided that \(\pi \to \text{greedy}\)
(Sutton and Barto, p. 129)
On vs Off-Policy
On Policy
Off Policy
Q-learning:
\(Q(s, a) \gets Q(s, a) + \alpha\, \left(r + \gamma \max_{a'} Q(s', a') - Q(s, a)\right)\)
SARSA:
\(Q(s, a) \gets Q(s, a) + \alpha\, \left(r + \gamma Q(s', a') - Q(s, a)\right)\)
Will eligibility traces work with Q-learning?
Not easily
Policy Gradient:
\(\theta \gets \theta + \alpha \sum_{k=0}^d \nabla_\theta \log \pi_\theta(a_k \mid s_k) R(\tau) \)
Today
- Basic On- and Off-Policy value based model free RL algorithms
- Tricks for tabular value based RL algorithms
- Understanding of On- vs Off-Policy
120 Value Based Model Free RL
By Zachary Sunberg



