Deep Reinforcement Learning that Matters
Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, David Meger
(Microsoft, McGill University)
AAAI 2018
Presented by Zachary Sunberg, August 26, 2021
Motivation
- Some interesting problem (smallsat swarm)
- Spend weeks theorizing about the exact-right cost function and dynamics
- Decide RL can solve all of your problems
- Fire up open-ai baselines
- Does it work??



Why not?
- Hyperparameters?
- Reward scaling?
- Not enough training time????
Motivation: The Dream

Motivation
- When we read the RL literature how do we know what algorithm is best for our appliction?
- How do we credit people for doing good research work in RL?
Contributions
- Provide an unbiased perspective on popular policy gradient algorithms
- Investigate effects of various factors on reproducibility
- Algorithm - environment matching
- Hyperparameters (reward scale)
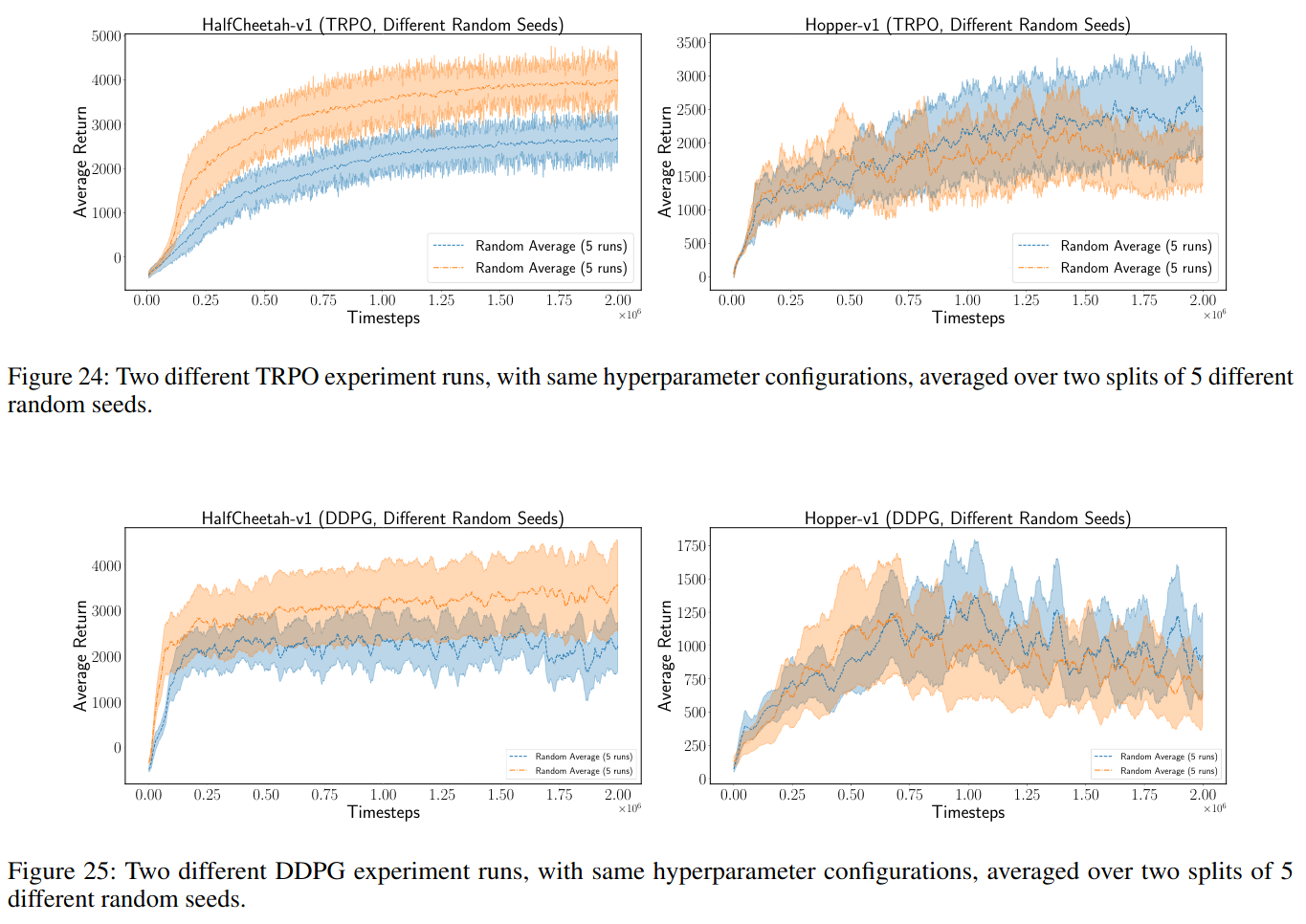
- Random Seeds
- Codebases
- Provide a rallying point for discussions on reproducibility
Background: Policy Gradient
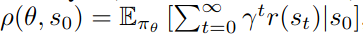
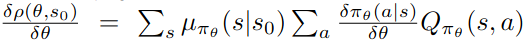
Context in Literature
Note: would expect more in a normal presentation
Computation Experiments


Half Cheetah
Hopper
Algorithms:
- ACKTR (Wu et al. 2017, Toronto)
- DDPG (Lillicrap et al. 2015, DeepMind)
- TRPO, PPO (Schulman et al. 2015,2017, Berkeley)
- 5 random seeds
- Mean and Standard Error
Computational Resources
Not reported, 2 million timesteps in learning curves
Numerical Results: Algorithms

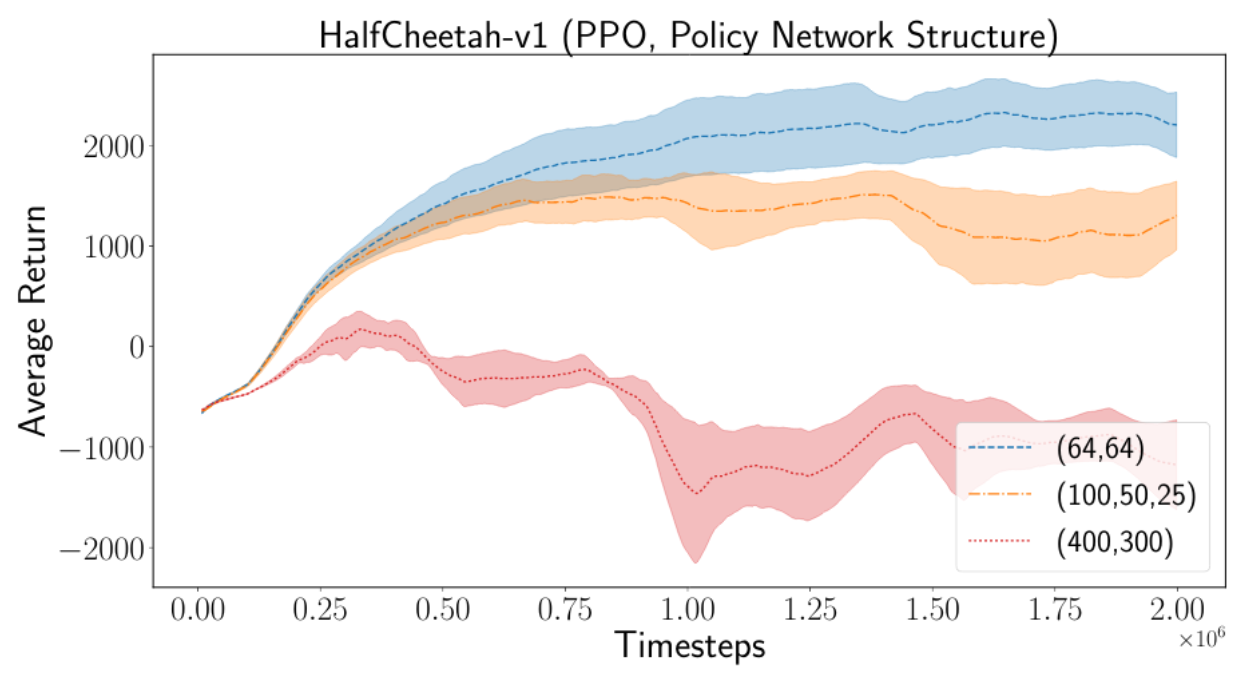
Numerical Results: Policy Network Architecture
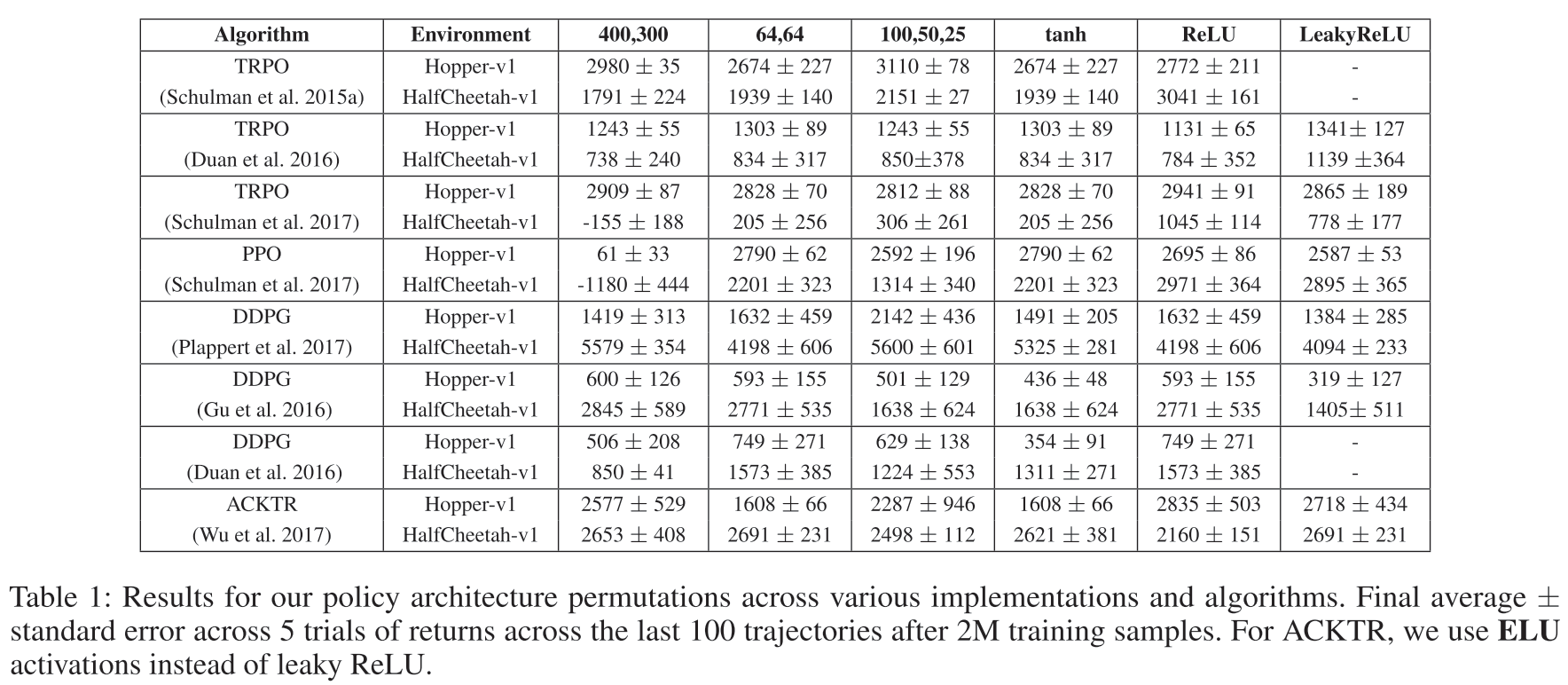
Numerical Results: Policy Network Architecture

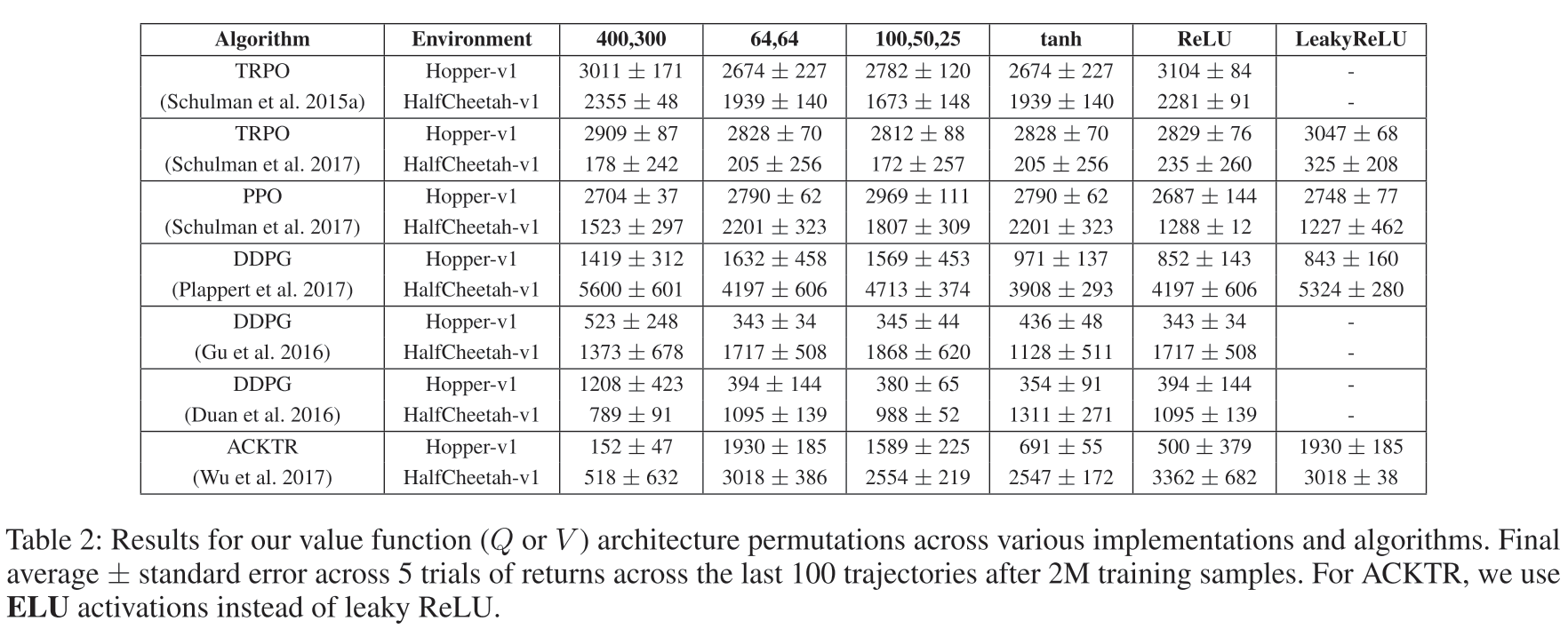
Numerical Results: Value Network Architecture
Numerical Results: Reward Rescaling

"simply multiplying the rewards generated from an environment by some scalar"
Numerical Results: Statistical Significance

"Unfortunately, in recent reported results, it is not uncommon for the top-N trials to be selected from among several trials (Wu et al. 2017; Mnih et al. 2016)"
Numerical Results: Codebases

Numerical Results: Bootstrap Confidence Intervals

Recommendations
- If you are comparing against a baseline, results should match performance reported in original
- Use many random seeds
- Report all details ("the most important step")
Without the publication of implementations and related details, wasted effort on reproducing state-of-the-art works will plague the community and slow down progress.
Critique
Positive:
- Challenging the community in a helpful way
- Experiments effectively demonstrate their points
Negative:
- Some results actually seem a bit cherry-picked
Impact and Legacy
Over 1000 citations, including
- Soft Actor-Critic
- CARLA
- TD3

Future Work for Paper/Reading
- "Hyperparameter agnostic algorithms"
- "Safe RL evaluation methods"
Contributions (Recap)
- Provide an unbiased perspective on popular policy gradient algorithms
- Investigate effects of various factors on reproducibility
- Algorithm - environment matching
- Hyperparameters (reward scale)
- Random Seeds
- Codebases
- Provide a rallying point for discussions on reproducibility
Deep RL that matters
By Zachary Sunberg




