
Online POMDP and POSG Planning for Deception and Counter-Deception
Professor Zachary Sunberg
University of Colorado Boulder
DECODE-AI Project Kickoff Meeting
February 26, 2025
Autonomous Decision and Control Laboratory

-
Algorithmic Contributions
- Scalable algorithms for partially observable Markov decision processes (POMDPs)
- Motion planning with safety guarantees
- Game theoretic algorithms
-
Theoretical Contributions
- Particle POMDP approximation bounds
-
Applications
- Space Domain Awareness
- Autonomous Driving
- Autonomous Aerial Scientific Missions
- Search and Rescue
- Space Exploration
- Ecology
-
Open Source Software
- POMDPs.jl Julia ecosystem

PI: Prof. Zachary Sunberg

PhD Students








Postdoc


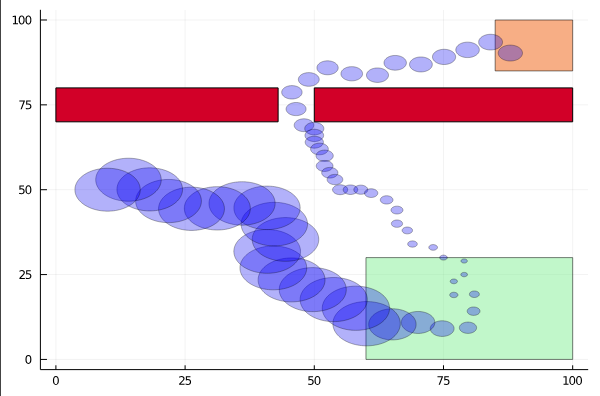
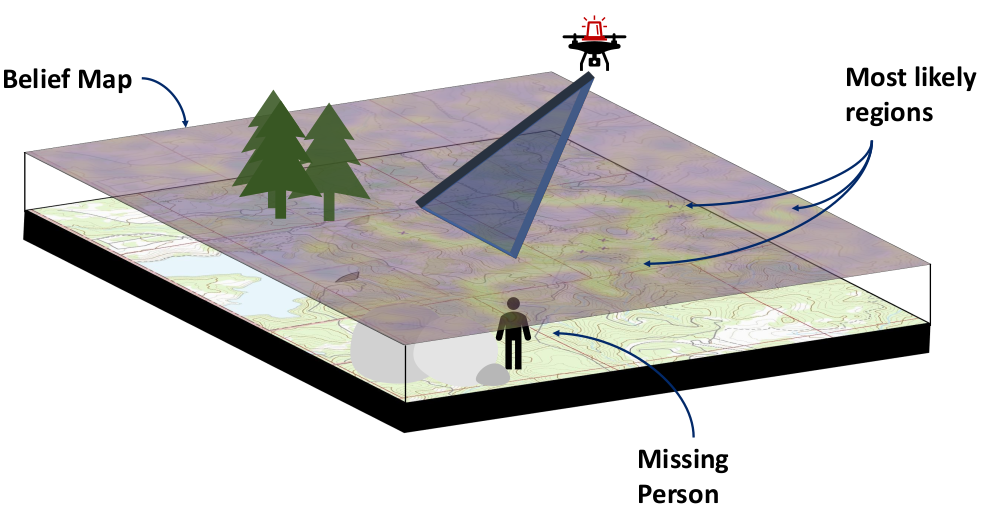
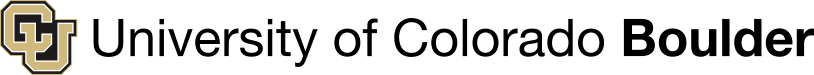


Most Significant Previous Contributions: Online POMDP Planning
POMDP = Partially Observable Markov Decision Process
For DECODE-AI:
- Hidden POMDP states are the goals and intentions of the red team
- POMDP policies can accomplish blue team tasks and reveal red team intentions


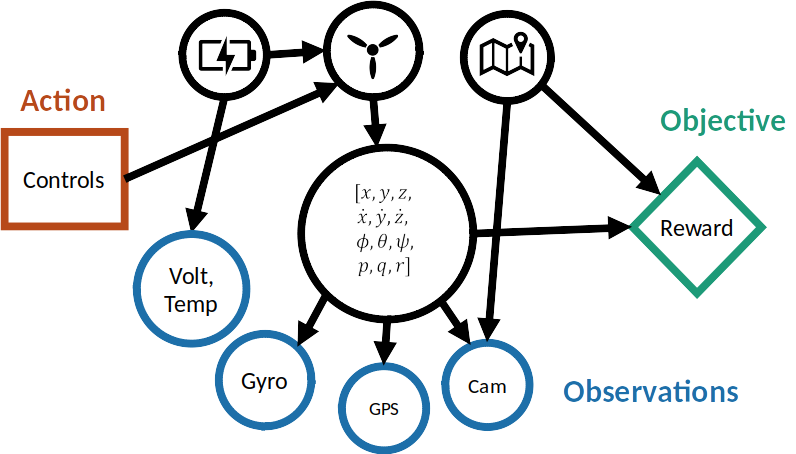
\([x, y, z,\;\; \phi, \theta, \psi,\;\; u, v, w,\;\; p,q,r]\)
\(\mathcal{S} = \mathbb{R}^{12}\)

\(\mathcal{S} = \mathbb{R}^{12} \times \mathbb{R}^\infty\)
Very large continuous state and observation spaces
State Space:
Online: Computing as you are interacting (Kahneman Thinking Fast and Slow System 2)
Markov Decision Process (MDP)
- \(\mathcal{S}\) - State space
- \(T:\mathcal{S}\times \mathcal{A} \times\mathcal{S} \to \mathbb{R}\) - Transition probability distribution
- \(\mathcal{A}\) - Action space
- \(R:\mathcal{S}\times \mathcal{A} \to \mathbb{R}\) - Reward

Aleatory
\([x, y, z,\;\; \phi, \theta, \psi,\;\; u, v, w,\;\; p,q,r]\)
\(\mathcal{S} = \mathbb{R}^{12}\)
\(\mathcal{S} = \mathbb{R}^{12} \times \mathbb{R}^\infty\)
\[\underset{\pi:\, \mathcal{S} \to \mathcal{A}}{\text{maximize}} \quad \text{E}\left[ \sum_{t=0}^\infty R(s_t, a_t) \right]\]
Partially Observable Markov Decision Process (POMDP)

- \(\mathcal{S}\) - State space
- \(T:\mathcal{S}\times \mathcal{A} \times\mathcal{S} \to \mathbb{R}\) - Transition probability distribution
- \(\mathcal{A}\) - Action space
- \(R:\mathcal{S}\times \mathcal{A} \to \mathbb{R}\) - Reward
- \(\mathcal{O}\) - Observation space
- \(Z:\mathcal{S} \times \mathcal{A}\times \mathcal{S} \times \mathcal{O} \to \mathbb{R}\) - Observation probability distribution
Aleatory
Epistemic (Static)
Epistemic (Dynamic)
\([x, y, z,\;\; \phi, \theta, \psi,\;\; u, v, w,\;\; p,q,r]\)
\(\mathcal{S} = \mathbb{R}^{12}\)
\(\mathcal{S} = \mathbb{R}^{12} \times \mathbb{R}^\infty\)
Key Theoretical Breakthrough
- Solving POMDPs exactly is intractable (PSPACE-Complete / NP-hard) [Papadimitriou, 1987]
- However, our online algorithms can find \(\epsilon\)-suboptimal policies with no dependence on the size of the state or observation spaces.
[Lim, Becker, Kochenderfer, Tomlin, & Sunberg, JAIR 2023]
\[|Q_{\mathbf{P}}^*(b,a) - Q_{\mathbf{M}_{\mathbf{P}}}^*(\bar{b},a)| \leq \epsilon \quad \text{w.p. } 1-\delta\]
For any \(\epsilon>0\) and \(\delta>0\), if \(C\) (number of particles) is high enough,
No direct relationship between \(C\) and \(|\mathcal{S}|\) or \(|\mathcal{O}|\)
How Our POMDP Algorithms Work
1. Low-sample particle filtering
2. Sparse Sampling


[Lim, Becker, Kochenderfer, Tomlin, & Sunberg, JAIR 2023; Sunberg & Kochenderfer, ICAPS 2018; Others]
DECODE-AI Task 3.3:
Planning / ML Integration

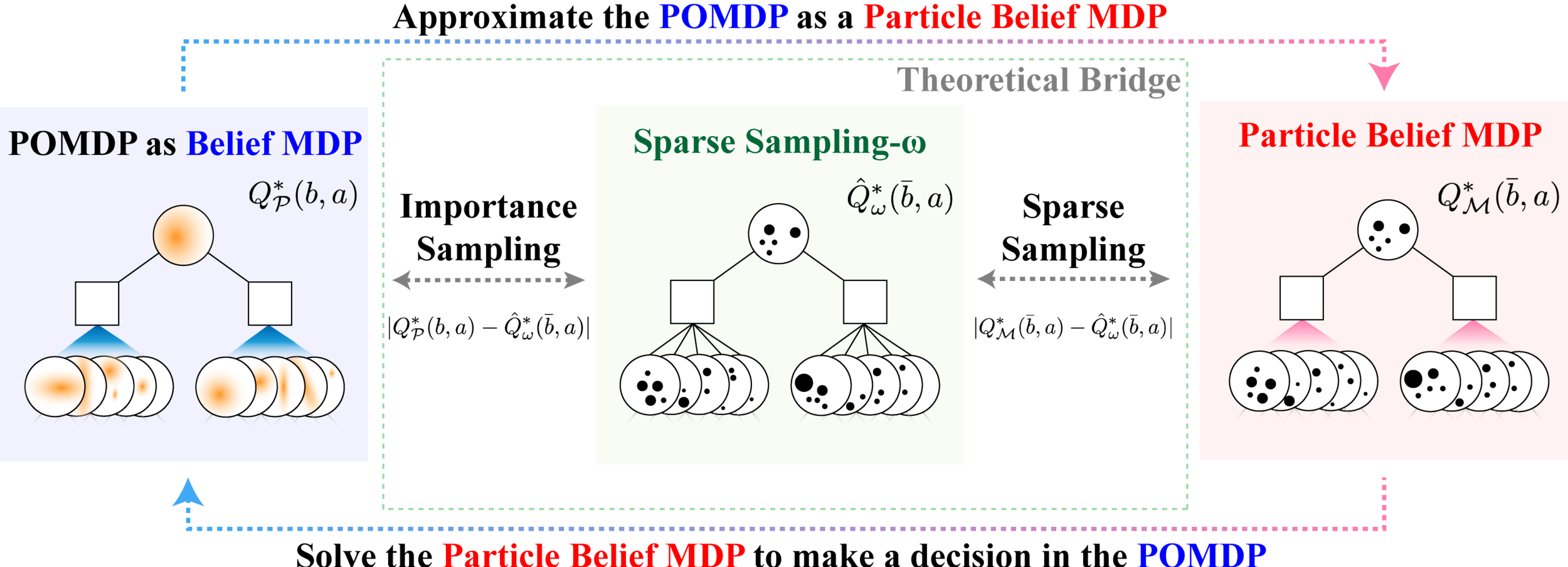
- Our previous work showed promising performance (training time reduced by half)
- Only used mean and variance of particle distributions
[Deglurkar, Lim, Sunberg, & Tomlin, 2023]
Task 3.3 Goal: Use more than variance in learned components
Kahneman System 1
Kahneman System 2
(Ours)

- Idea 1: Moment Generating Function
- Idea 2: Set Transformer
Progress so far:
- Basic implementations of MGF, Set Transformer
- Results comparable to baselines in simple problems
[Lee et al., ICML 2019]

[Ma et al., ICLR 2020]
DECODE-AI Task 3.3:
Planning / ML Integration


Query
Key
Value
Key Challenge: Interpreting particle beliefs in an order-invariant way
The POMDP is a good model for information gathering, but it is incomplete:
- Cannot reason about an adversary that can change their policy in response
- Cannot synthesize deceptive policies
Partially Observable Stochastic Game (POSG)

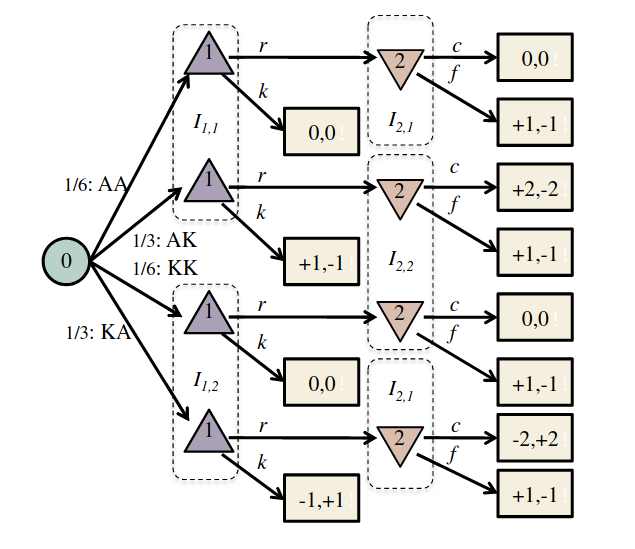
Image: Russel & Norvig, AI, a modern approach
P1: A
P1: K
P2: A
P2: A
P2: K
DECODE-AI Task 4.1: Online POSG Planning
Task 4.1 Goal: Create online POSG planning algorithms for real-world problems
Partially Observable Markov Decision Process (POMDP)
- \(\mathcal{S}\) - State space
- \(T:\mathcal{S}\times \mathcal{A} \times\mathcal{S} \to \mathbb{R}\) - Transition probability distribution
- \(\mathcal{A}\) - Action space
- \(R:\mathcal{S}\times \mathcal{A} \to \mathbb{R}\) - Reward
- \(\mathcal{O}\) - Observation space
- \(Z:\mathcal{S} \times \mathcal{A}\times \mathcal{S} \times \mathcal{O} \to \mathbb{R}\) - Observation probability distribution
Aleatory
Epistemic (Static)
Epistemic (Dynamic)
Partially Observable Stochastic Game (POSG)
Aleatory
Epistemic (Static)
Epistemic (Dynamic)
Interaction
- \(\mathcal{S}\) - State space
- \(T(s' \mid s, \bm{a})\) - Transition probability distribution
- \(\mathcal{A}^i, \, i \in 1..k\) - Action spaces
- \(R^i(s, \bm{a})\) - Reward function (cooperative, opposing, or somewhere in between)
- \(\mathcal{O}^i, \, i \in 1..k\) - Observation spaces
- \(Z(o^i \mid \bm{a}, s')\) - Observation probability distributions

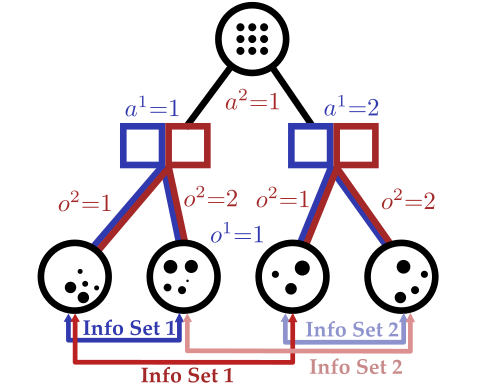
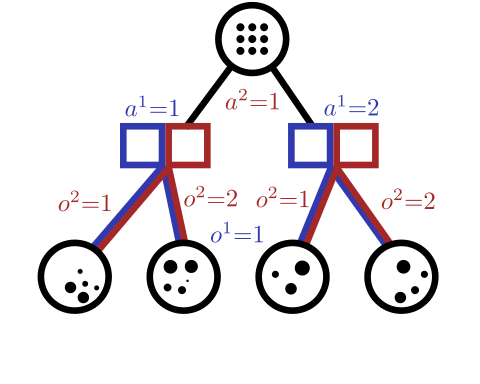
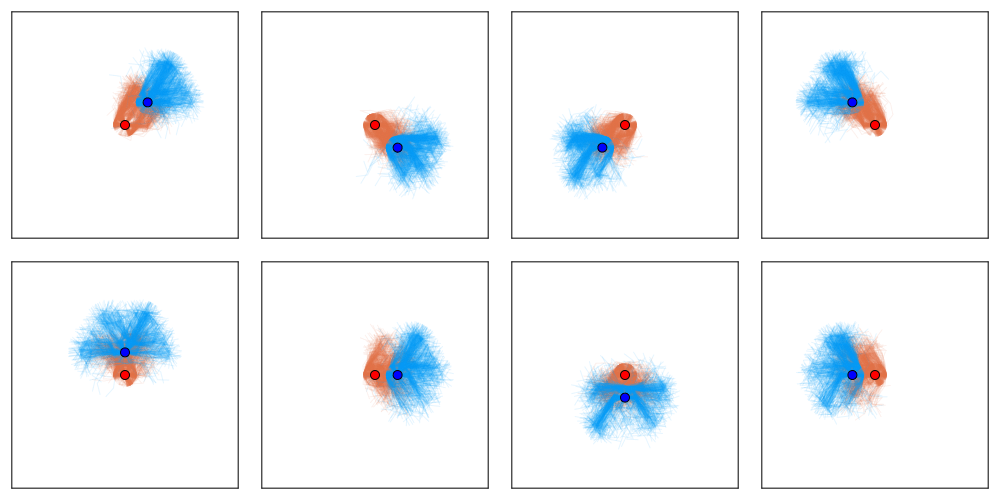
[Becker & Sunberg, AAMAS 2025]
DECODE-AI Task 4.1: Online POSG Planning
Our approach: combine particle filtering and information sets
Joint Belief
Joint Action
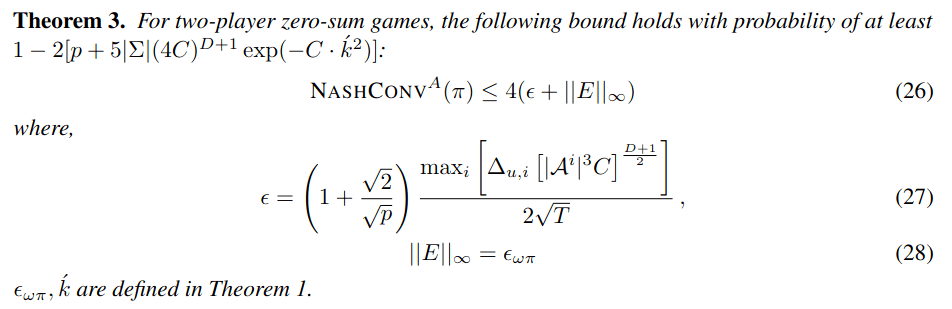
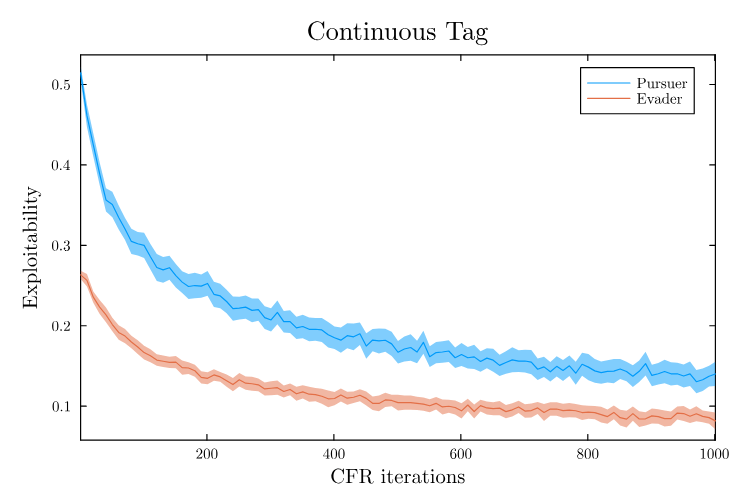
[Becker & Sunberg, AAMAS 2025]
Open (related) questions:
- Is this useful for continuous observations?
- What information needs to be carried step to step?
- Is this useful for games where both players know a partition of the state space exactly?
DECODE-AI Task 4.1: Online POSG Planning
Thank You!
Prof. Zachary Sunberg
PhD Student: Tyler Becker
PhD Student: Himanshu Gupta
PhD Student: Jackson Wagner
DECODE-AI Task 3.3: Integrating online POMDP planning with learned components
DECODE-AI Task 4.1: Online planning in POSGs
Interaction Uncertainty

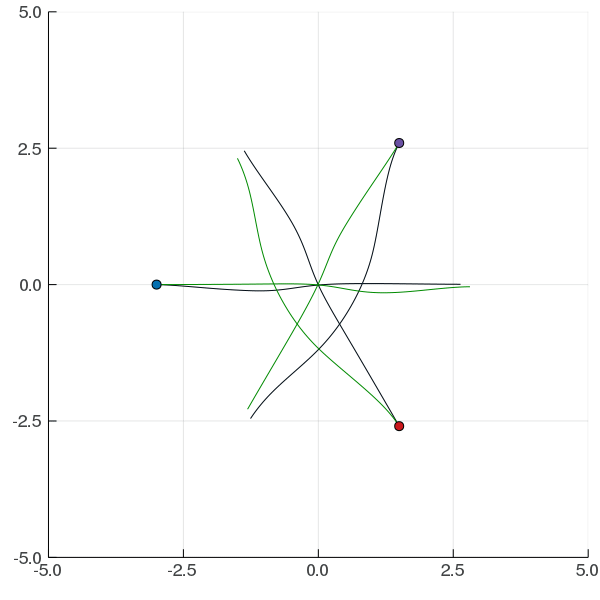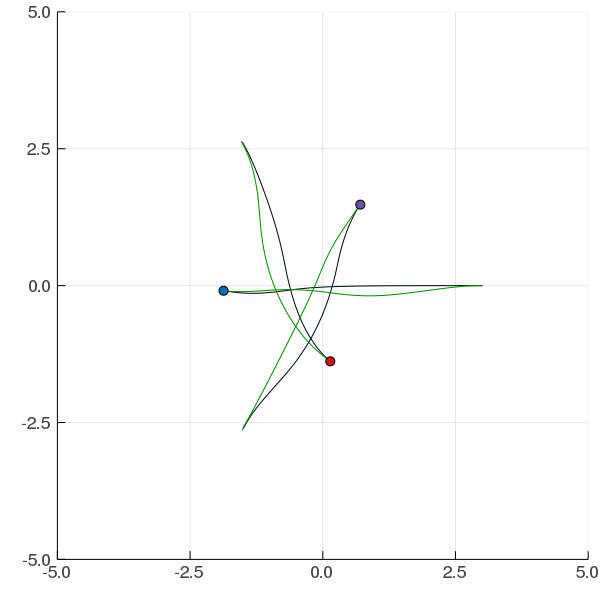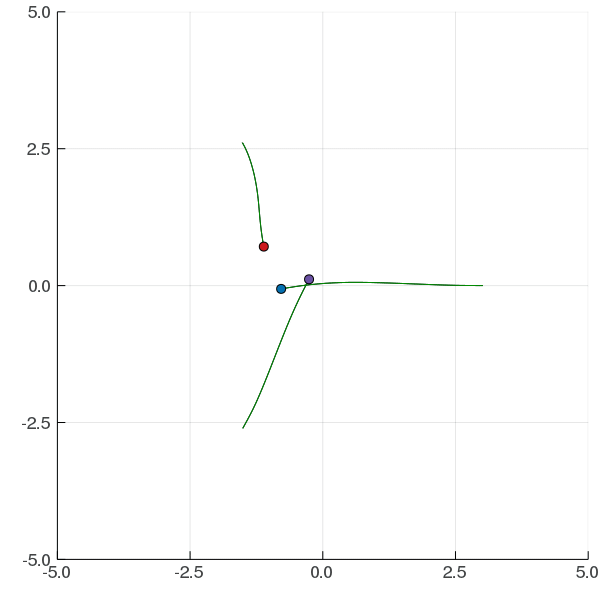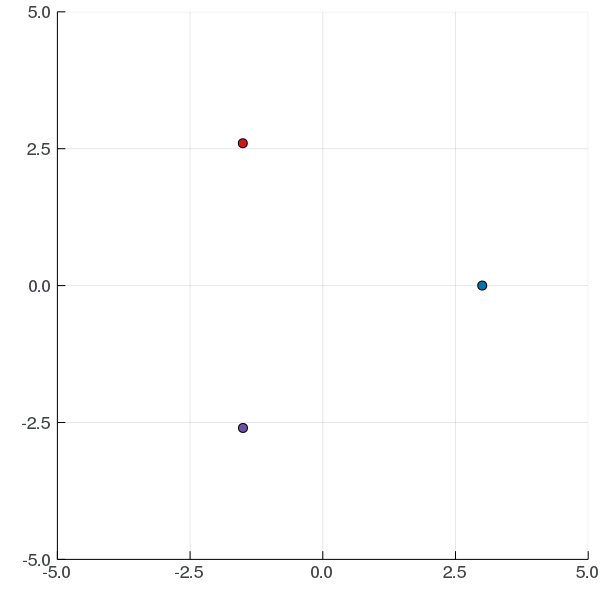
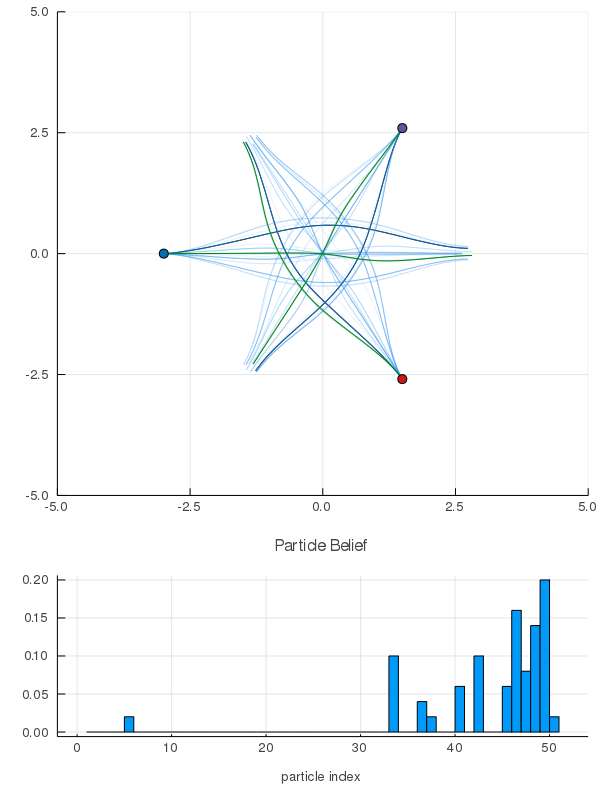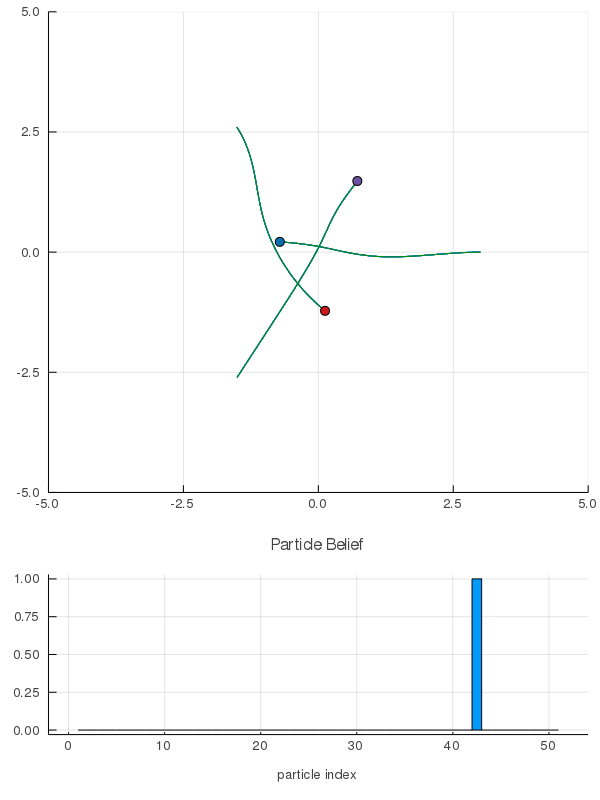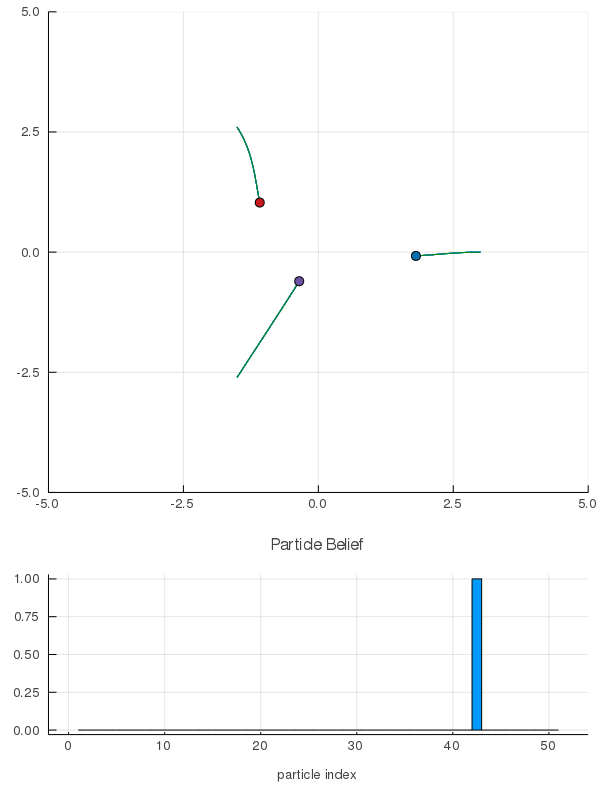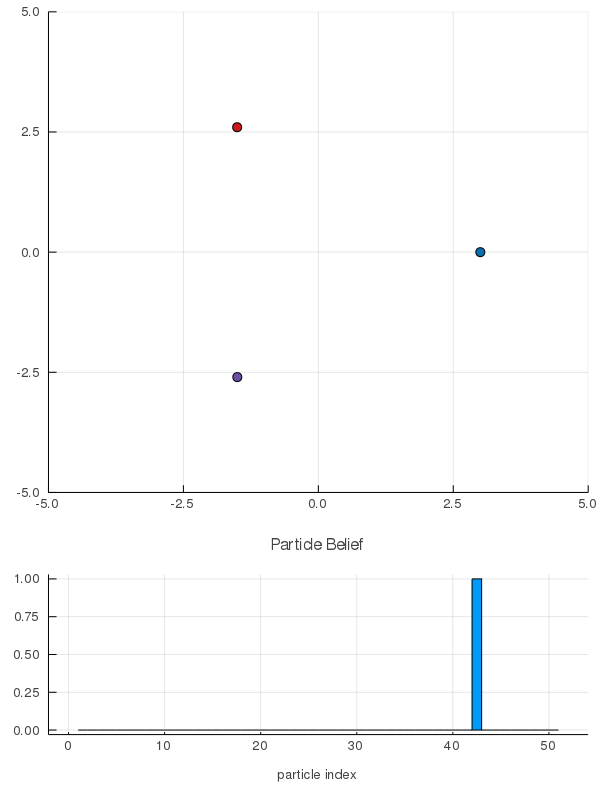

[Peters, Tomlin, and Sunberg 2020]
Space Domain Awareness Games
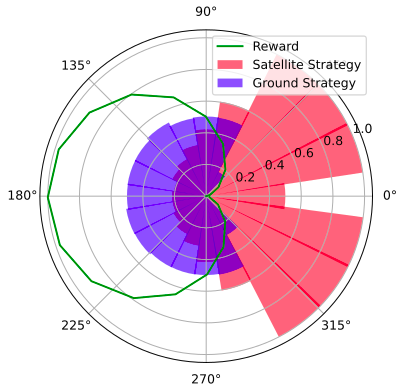
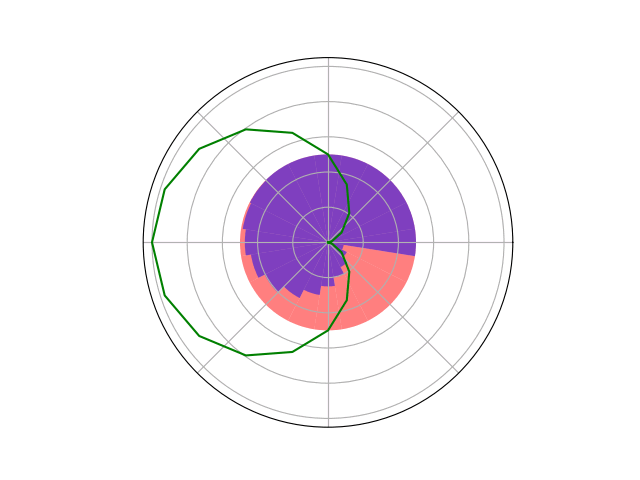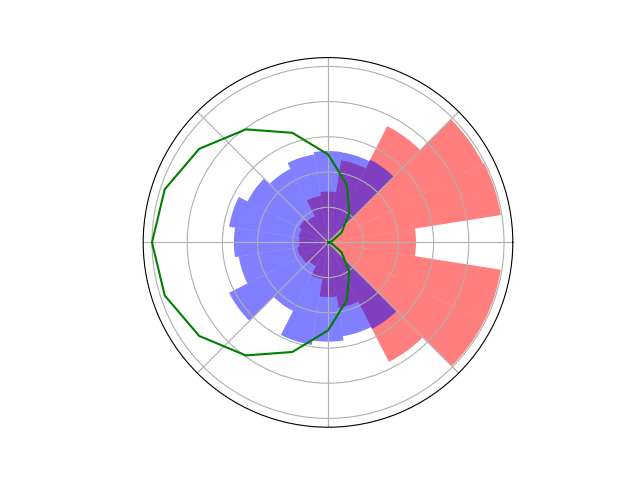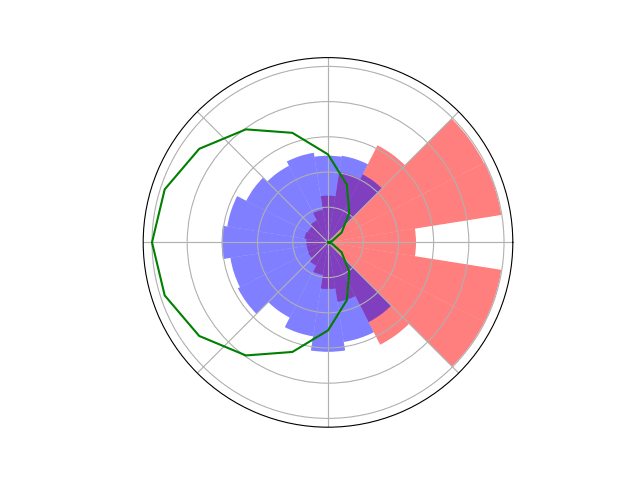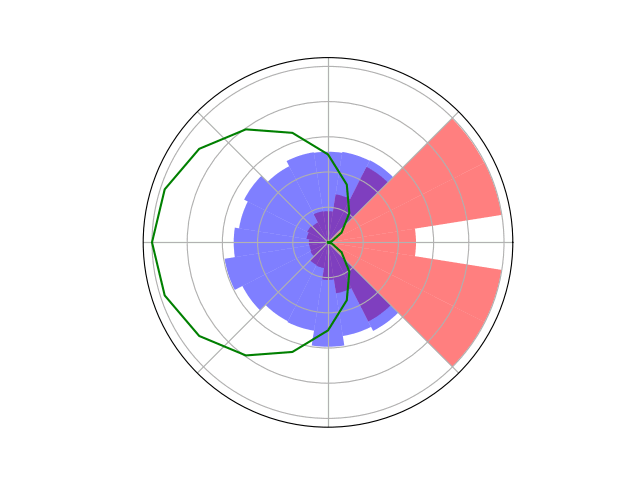
Open question: are there \(\mathcal{S}\)- and \(\mathcal{O}\)-independent algorithms for POMGs?
Incomplete Information Extensive form Game
Our new algorithm for POMGs
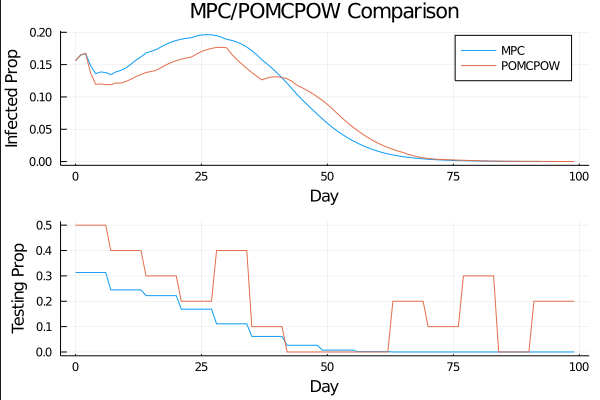
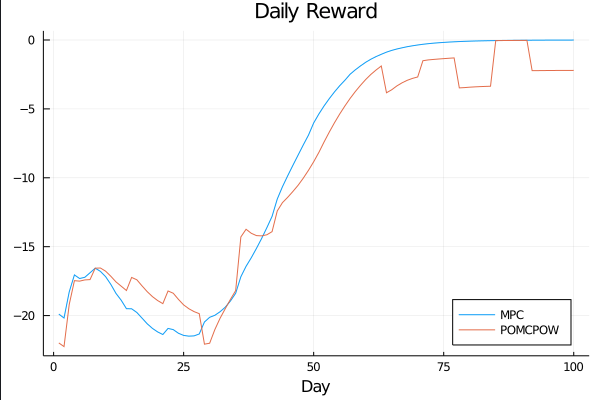
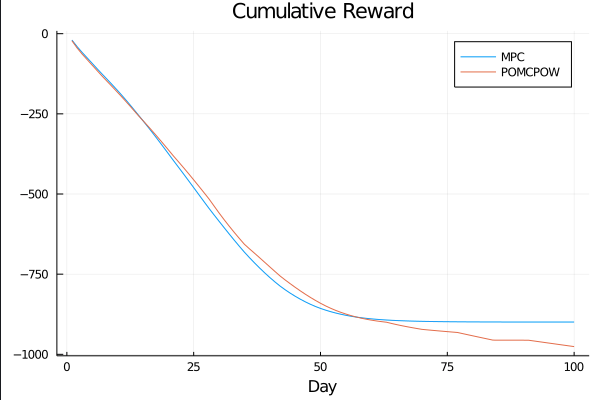
c_I = 100.0 \\
c_T = 1.0 \\
c_{TR} = 10.0
COVID POMDPs
Planning Rebuilding Ecosystems


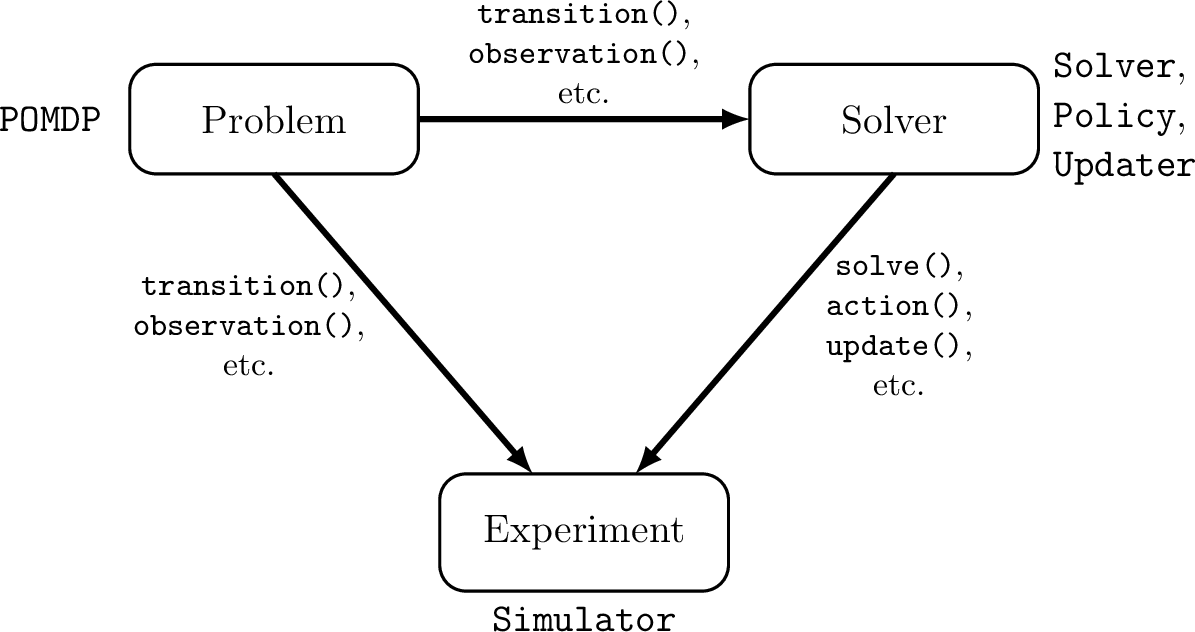
POMDPs.jl - An interface for defining and solving MDPs and POMDPs in Julia
Open Source Software


Autonomous Decision and Control Laboratory
-
Algorithmic Contributions
- Scalable algorithms for partially observable Markov decision processes (POMDPs)
- Motion planning with safety guarantees
- Game theoretic algorithms
-
Theoretical Contributions
- Particle POMDP approximation bounds
-
Applications
- Space Domain Awareness
- Autonomous Driving
- Autonomous Aerial Scientific Missions
- Search and Rescue
- Space Exploration
- Ecology
-
Open Source Software
- POMDPs.jl Julia ecosystem
PI: Prof. Zachary Sunberg
PhD Students
Postdoc
Thank You!
ADCL Students


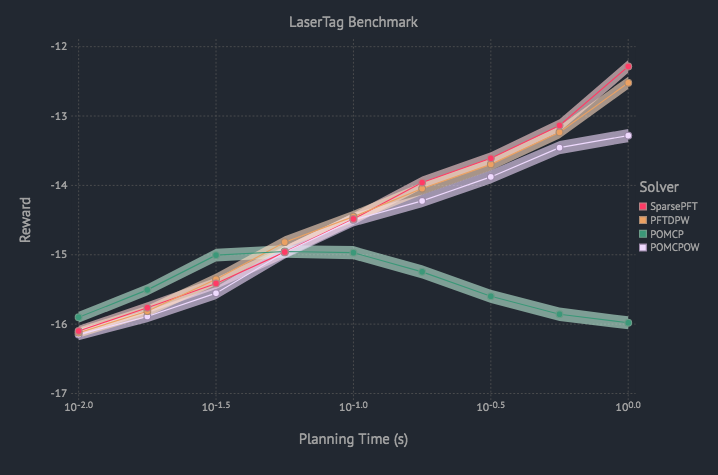
BOMCP


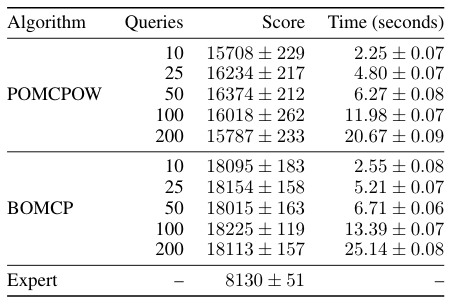
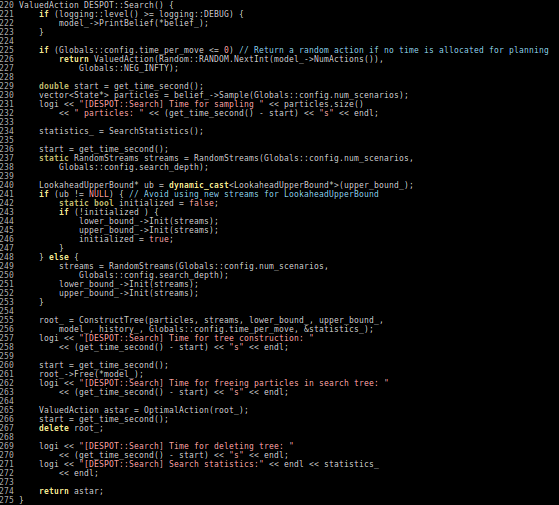
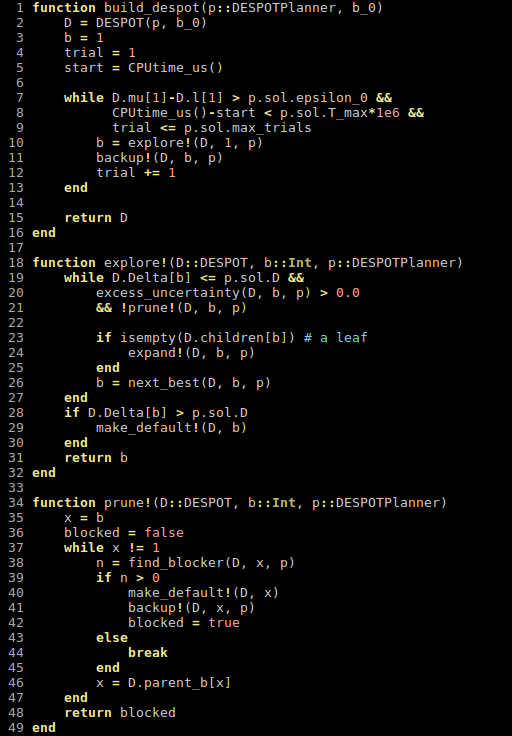
[Mern, Sunberg, et al. AAAI 2021]
MPC for Intermittent Rotor Failures
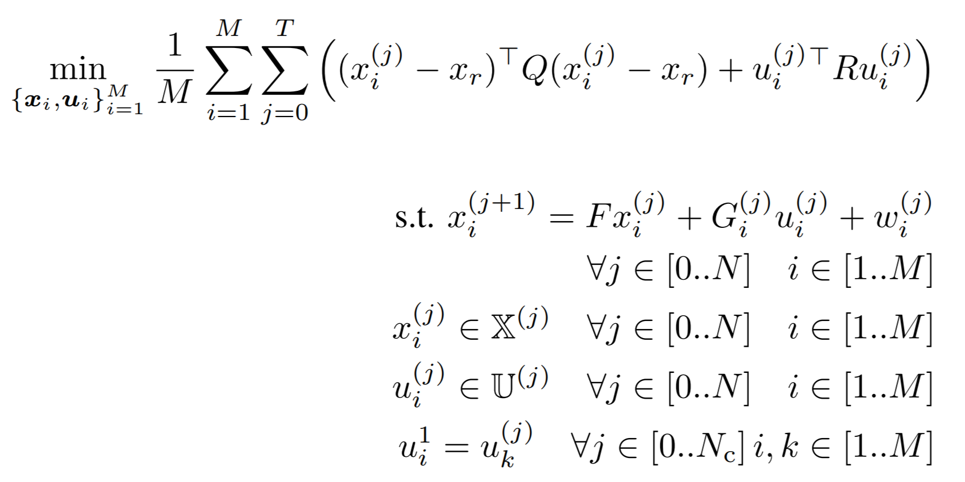
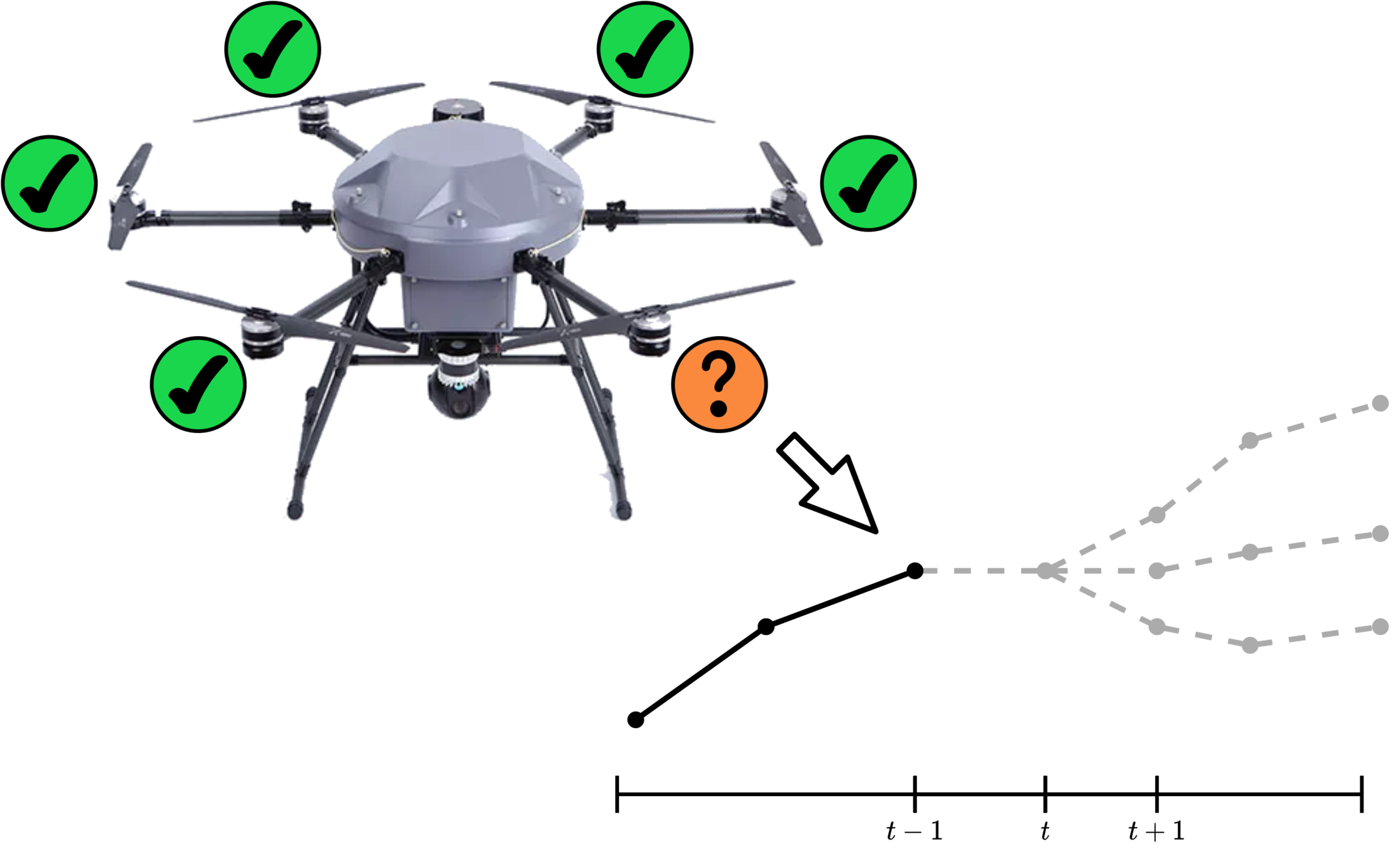
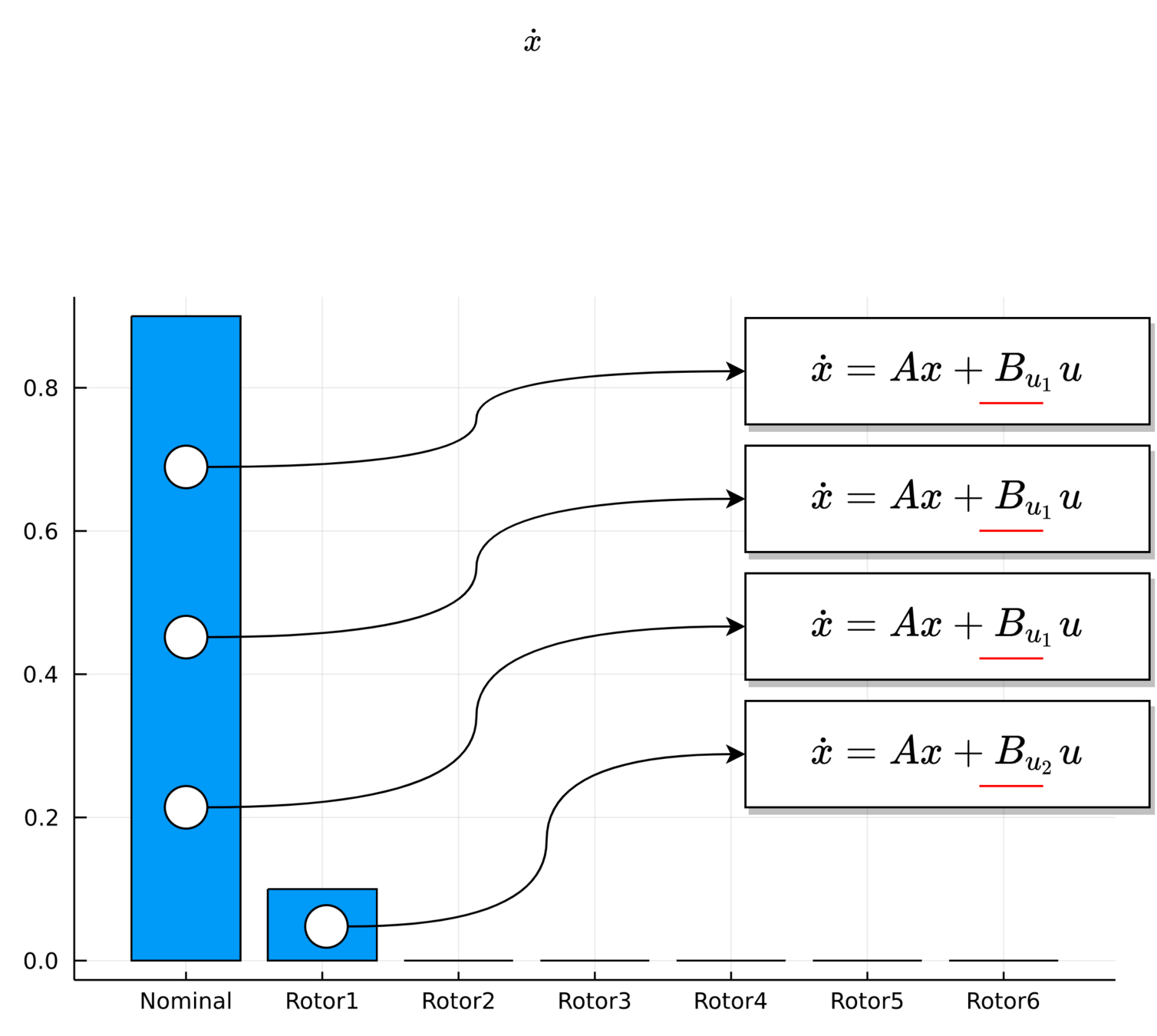
UAV Component Failures
Reward Decomposition for Adaptive Stress Testing
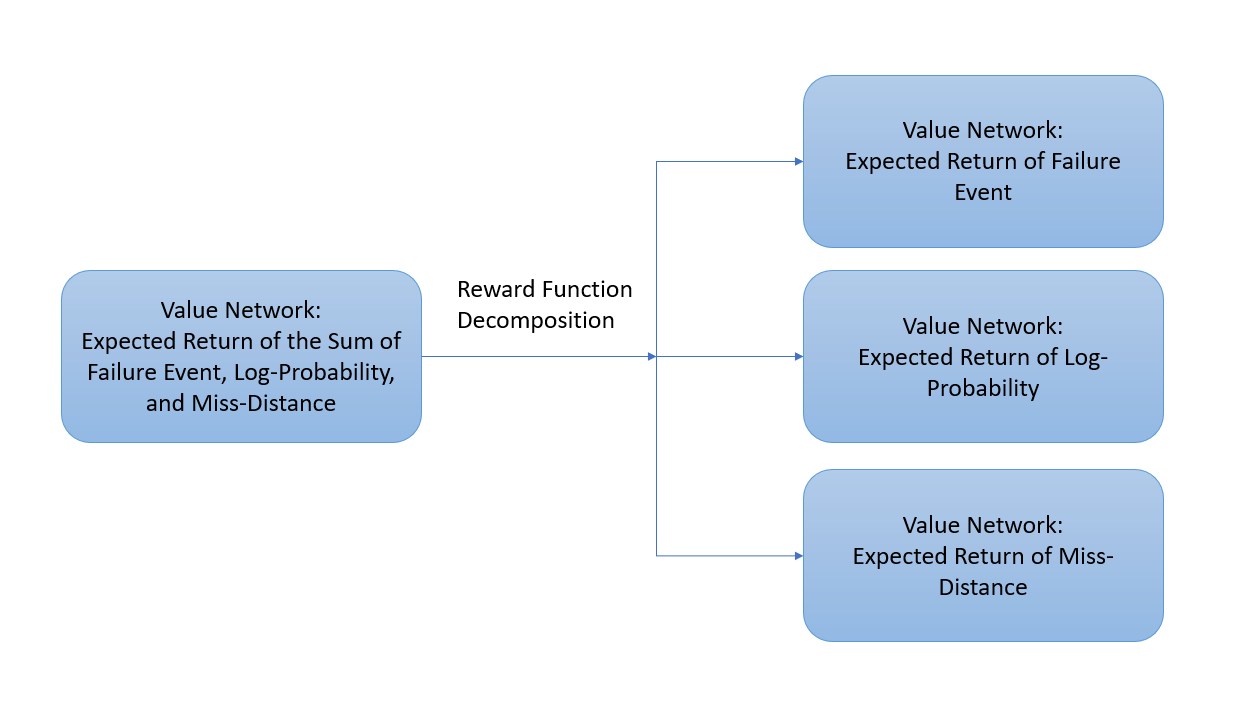

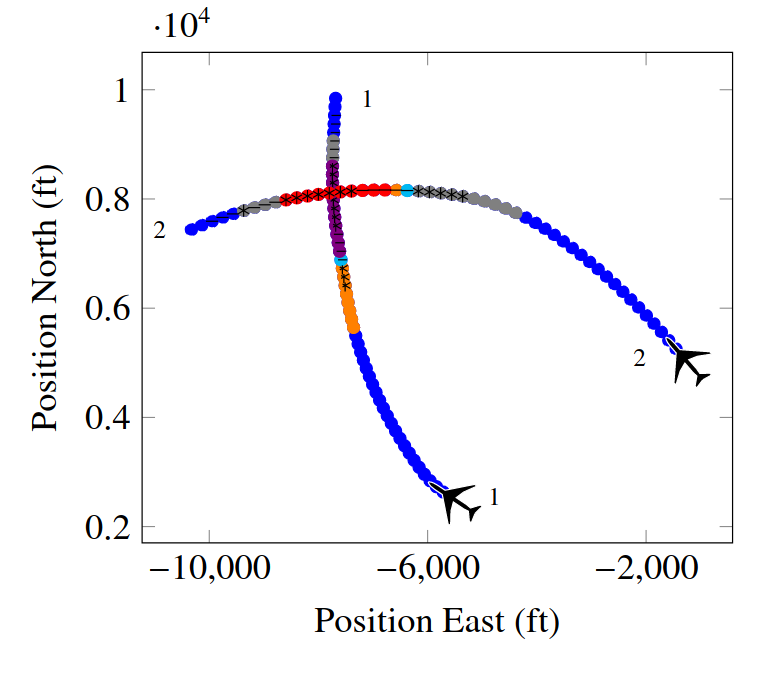


Voronoi Progressive Widening
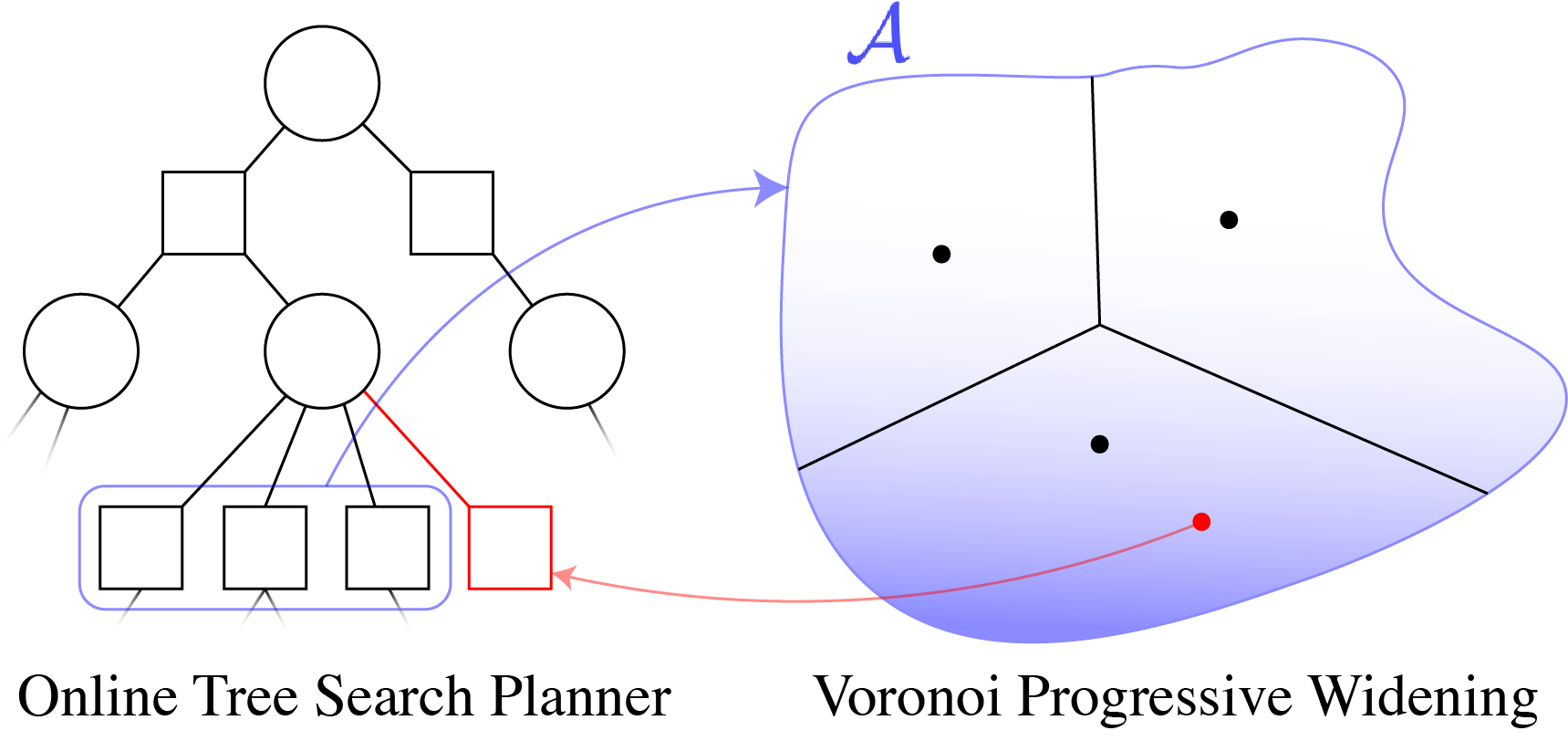
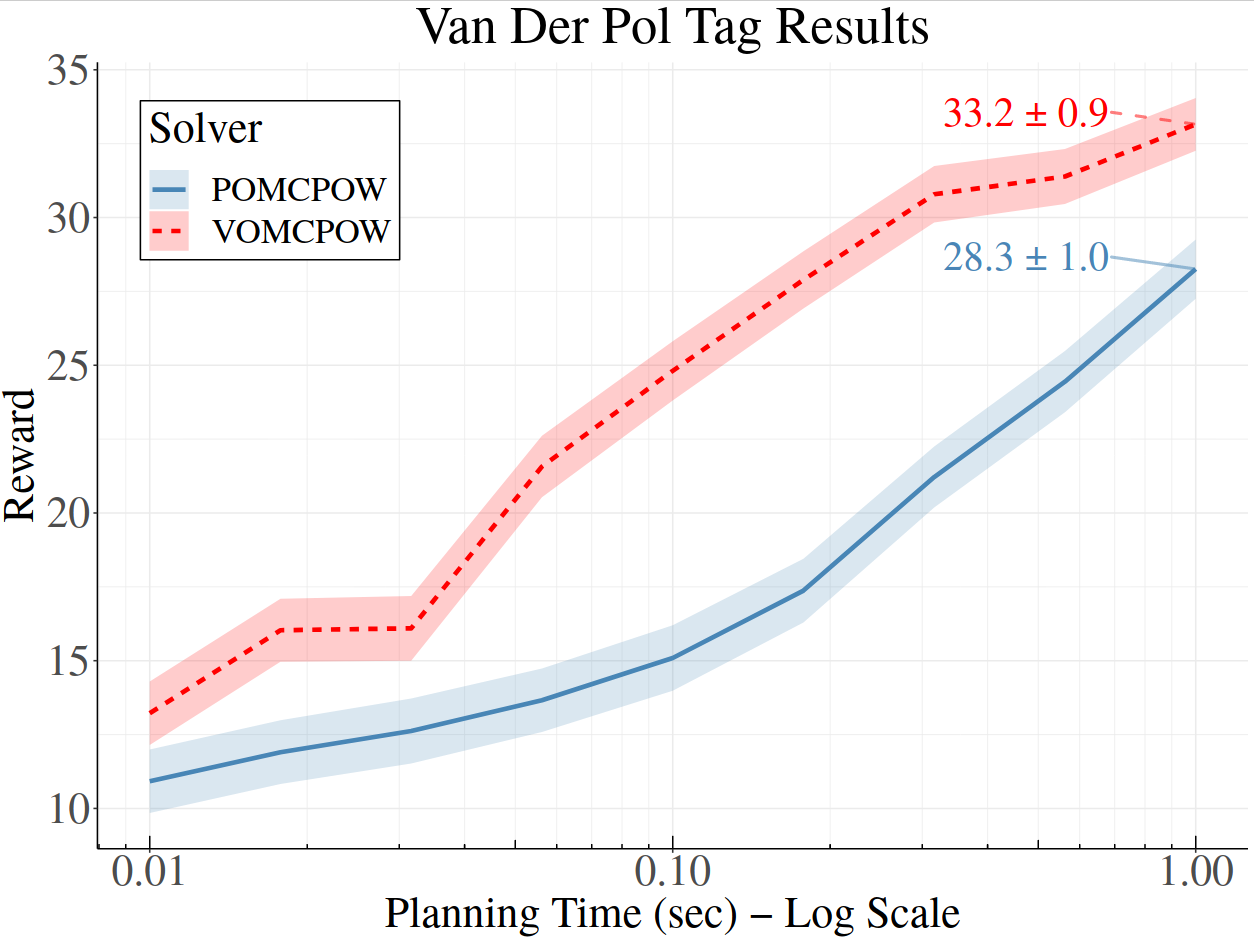

[Lim, Tomlin, & Sunberg CDC 2021]
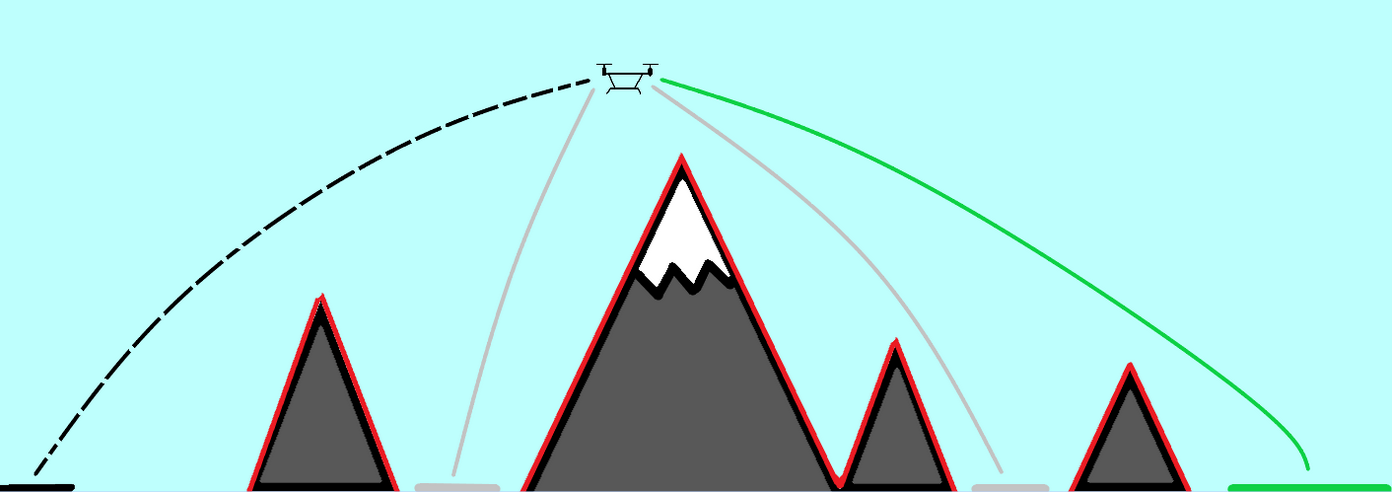
Active Information Gathering for Safety

Sparse PFT

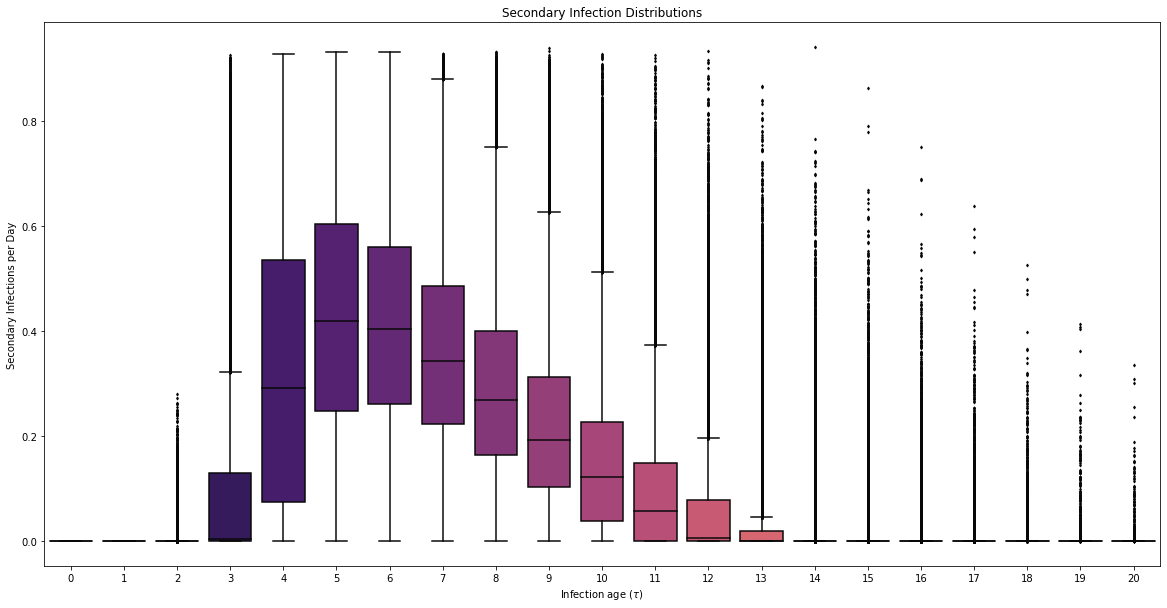
I(t) = \int_0^\infty I(t-\tau)\beta(\tau)d\tau
COVID POMDP
Individual Infectiousness
Infection Age
Incident Infections
\beta(\tau)
\tau
I
I(t) = \int_0^\infty I(t-\tau)\beta(\tau)d\tau
\beta(\tau)
Need
Test sensitivity is secondary to frequency and turnaround time for COVID-19 surveillance
Larremore et al.
\beta(\tau) \propto \log_{10}(\text{viral load})
Viral load represented by piecewise-linear hinge function
(t_0, 3)
(t_{\text{peak}}, V_{\text{peak}})
(t_f,6)
t_0 \sim \mathcal{U}[2.5,3.5]
t_\text{peak} - t_0 \sim 0.2 + \text{Gamma}(1.8)
V_\text{peak} \sim \mathcal{U}[7,11]
t_f - t_\text{peak} \sim \mathcal{U}[5,10]
DECODE-AI Kickoff
By Zachary Sunberg




