Offline POMDP Algorithms
Last time: POMDP Value Iteration (horizon \(d\))
\(\Gamma^0 \gets \emptyset\)
for \(n \in 1\ldots d\)
Construct \(\Gamma^n\) by expanding with \(\Gamma^{n-1}\)
Prune \(\Gamma^n\)
Finite Horizon POMDP Value Iteration

Finite Horizon POMDP Value Iteration

Break
So far, we have only dealt with n-step value functions, if we want to deal with infinite-horizon discounted POMDPs, how can we construct an infinite-horizon \(\alpha\) vector to start with?
Infinite-Horizon POMDP Lower Bound Improvement (Value Iteration)
\(\Gamma \gets\) blind lower bound
loop
\(\Gamma \gets \Gamma \cup \text{backup}(\Gamma)\)
\(\Gamma \gets \text{prune}(\Gamma)\)
\(\Gamma' = \bigcup_{a \in A} \Gamma^a\)
\(\Gamma^a = \bigoplus_{o \in O} \Gamma^{a,o} \quad \forall\, a\)
\(\Gamma^{a,o} = \left\{ \frac{1}{|O|}\, r_a + \alpha^{a,o} \;:\; \alpha \in \Gamma \right\} \quad \forall \, a, o\)
\(\alpha^{a,o}[s] = \sum_{s'} Z(o \mid a, s')\, T(s' \mid s, a)\, \alpha[s'] \quad \forall \, a, o, s, \alpha \in \Gamma\)
\(\text{backup}(\Gamma)\)
Complexity \(O\!\left( |\Gamma|\,|A|\,|O|\,|S|^2 + |A|\,|S|\,|\Gamma|^{|O|} \right)\)
Shani G, Pineau J, Kaplow R. A survey of point-based POMDP solvers. Auton Agent Multi-Agent Syst. 2013;27(1):1-51. doi:10.1007/s10458-012-9200-2
Infinite-Horizon POMDP Lower Bound Improvement
\(\Gamma \gets\) blind lower bound
loop
\(\Gamma \gets \Gamma \cup \text{backup}(\Gamma)\)
\(\Gamma \gets \text{prune}(\Gamma)\)
Infinite-Horizon POMDP Value Iteration
\(\Gamma \gets\) blind lower bound
loop
\(\Gamma \gets \Gamma \cup \text{backup}(\Gamma)\)
\(\Gamma \gets \text{prune}(\Gamma)\)

Point-Based Value Iteration (PBVI)
point_backup\((\Gamma, b)\)
for \(a \in A\)
for \(o \in O\)
\(b' \gets \tau(b, a, o)\)
\(\alpha_{a,o} \gets \underset{\alpha \in \Gamma}{\text{argmax}} \; \alpha^\top b'\)
for \(s \in S\)
\(\alpha_a[s] = R(s, a) + \gamma \sum_{s', o} T(s'\mid s, a) \,Z(o \mid a, s') \, \alpha_{a, o}[s']\)
return \(\underset{\alpha_a}{\text{argmax}} \; \alpha_a^\top b\)
\(O\!\left( |\Gamma|\,|A|\,|O|\,|S|^2 + |A|\,|S|\,|\Gamma|\,|B| \right)\)
Maintain belief set \(B\), \(\alpha\)-vector set \(\Gamma\)
repeatedly call point_backup for each \(b \in B\)
Shani G, Pineau J, Kaplow R. A survey of point-based POMDP solvers. Auton Agent Multi-Agent Syst. 2013;27(1):1-51. doi:10.1007/s10458-012-9200-2
Point-Based Value Iteration (PBVI)
point_backup\((\Gamma, b)\)
for \(a \in A\)
for \(o \in O\)
\(b' \gets \tau(b, a, o)\)
\(\alpha_{a,o} \gets \underset{\alpha \in \Gamma}{\text{argmax}} \; \alpha^\top b'\)
for \(s \in S\)
\(\alpha_a[s] = R(s, a) + \gamma \sum_{s', o} T(s'\mid s, a) \,Z(o' \mid a, s') \, \alpha_{a, o}[s']\)
return \(\underset{\alpha_a}{\text{argmax}} \; \alpha_a^\top b\)
Original PBVI
\(B \gets {b_0}\)
loop
for \(b \in B\)
\(\Gamma \gets \Gamma \cup \{\text{point\_backup}(\Gamma, b)\}\)
\(B' \gets \empty\)
for \(b \in B\)
\(\tilde{B} \gets \{\tau(b, a, o) : a \in A, o \in O\}\)
\(B' \gets B' \cup \left\{\underset{b' \in \tilde{B}}{\text{argmax}} \; \lVert B, b' \rVert\right\}\)
\(B \gets B \cup B'\)
Original PBVI

PERSEUS: Randomly Selected Beliefs
Two Phases:
- Random Exploration
- Value Backup
Random Exploration:
\(B \gets \emptyset\)
\(b \gets b_0\)
loop until \(\lvert B \rvert = n\)
\(a \gets \text{rand}(A)\)
\(o \gets \text{rand}(P(o \mid b, a))\)
\(b \gets \tau(b, a, o)\)
\(B = B \cup \{b\}\)
Heuristic Search Value Iteration (HSVI)
while \(\overline{V}(b_0) - \underline{V}(b_0) > \epsilon \)
explore\((b_0, 0)\)
explore(b, t)
if \(\overline{V}(b) - \underline{V}(b) > \epsilon \gamma^t\)
\(a^* = \underset{a}{\text{argmax}} \; \overline{Q}(b, a)\)
\(o^* = \underset{o}{\text{argmax}} \; P(o \mid b, a) \left(\overline{V}(\tau(b, a^*, o)) - \underline{V}(\tau(b, a^*, o)) - \epsilon \gamma^t\right)\)
explore(\(\tau(b, a^*, o^*), t+1\))
\(\underline{\Gamma} \gets \underline{\Gamma} \cup \text{point\_backup}(\underline{\Gamma}, b)\)
\(\overline{V}(b) = B_b \left[ \overline{V}(b) \right]\)
Heuristic Search Value Iteration

Sawtooth Upper Bounds
Sawtooth Upper Bounds

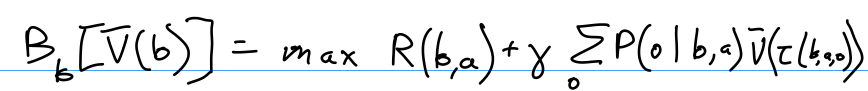
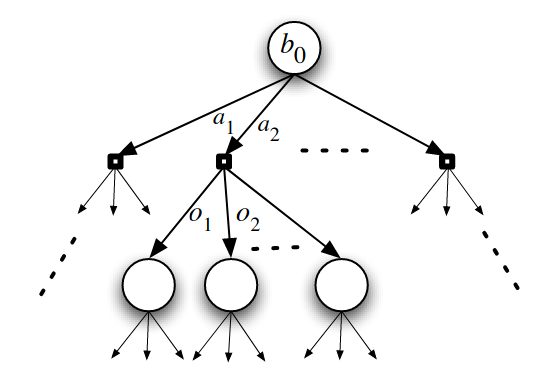
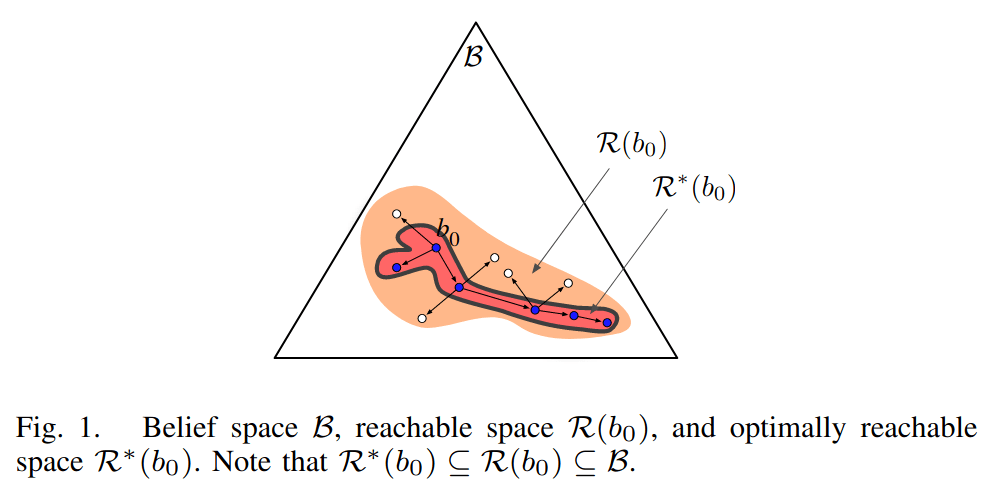
SARSOP
Successive Approximation of Reachable Space under Optimal Policies
(One instantiation of PBVI)
- Start with \(B = \{b_0\}\), \(\Gamma\) = blind lower bound
- Maintain \(B\) with a belief tree
- Maintain value bounds (\(\Gamma\): lower, "sawtooth": upper)
- At each iteration, sample new belief points to add to tree
- Choose actions with upper bound
- Choose observations with upper-lower
- Prune
- Tree and \(B\) to stay in \(\mathcal{R}^*(b_0)\)
- \(\alpha\) vectors not dominant for any \(b \in B\)
Kurniawati H, Hsu D, Lee WS. SARSOP: Efficient Point-Based POMDP Planning by Approximating Optimally Reachable Belief Spaces.
- Can solve problems with up to ~100,000 states
- Hidden implementation details :(((
- HSVI - similar algorithm, better paper
SARSOP
Successive Approximation of Reachable Space under Optimal Policies


Offline POMDP Algorithms
Offline POMDP Algorithms

Tiger POMDP Solution
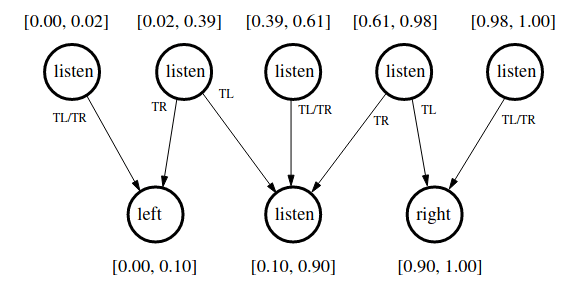
(Undiscounted) from Kaelbling, L. P., Littman, M. L., & Cassandra, A. R. (1998). Planning and acting in partially observable stochastic domains. Artificial Intelligence
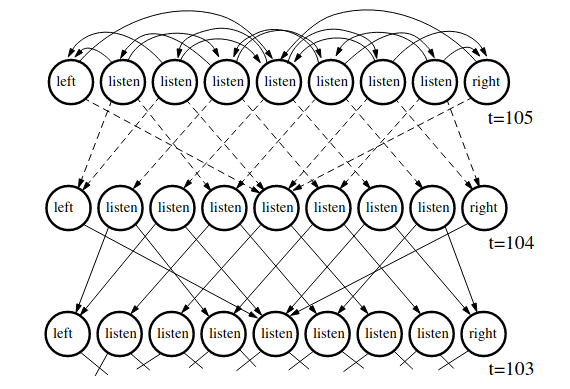
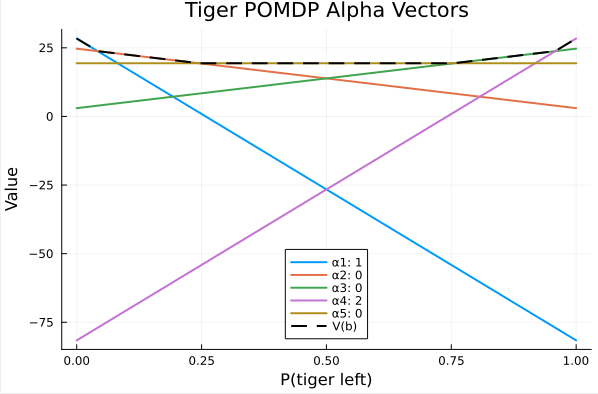
Alpha Vectors From SARSOP (discounted)
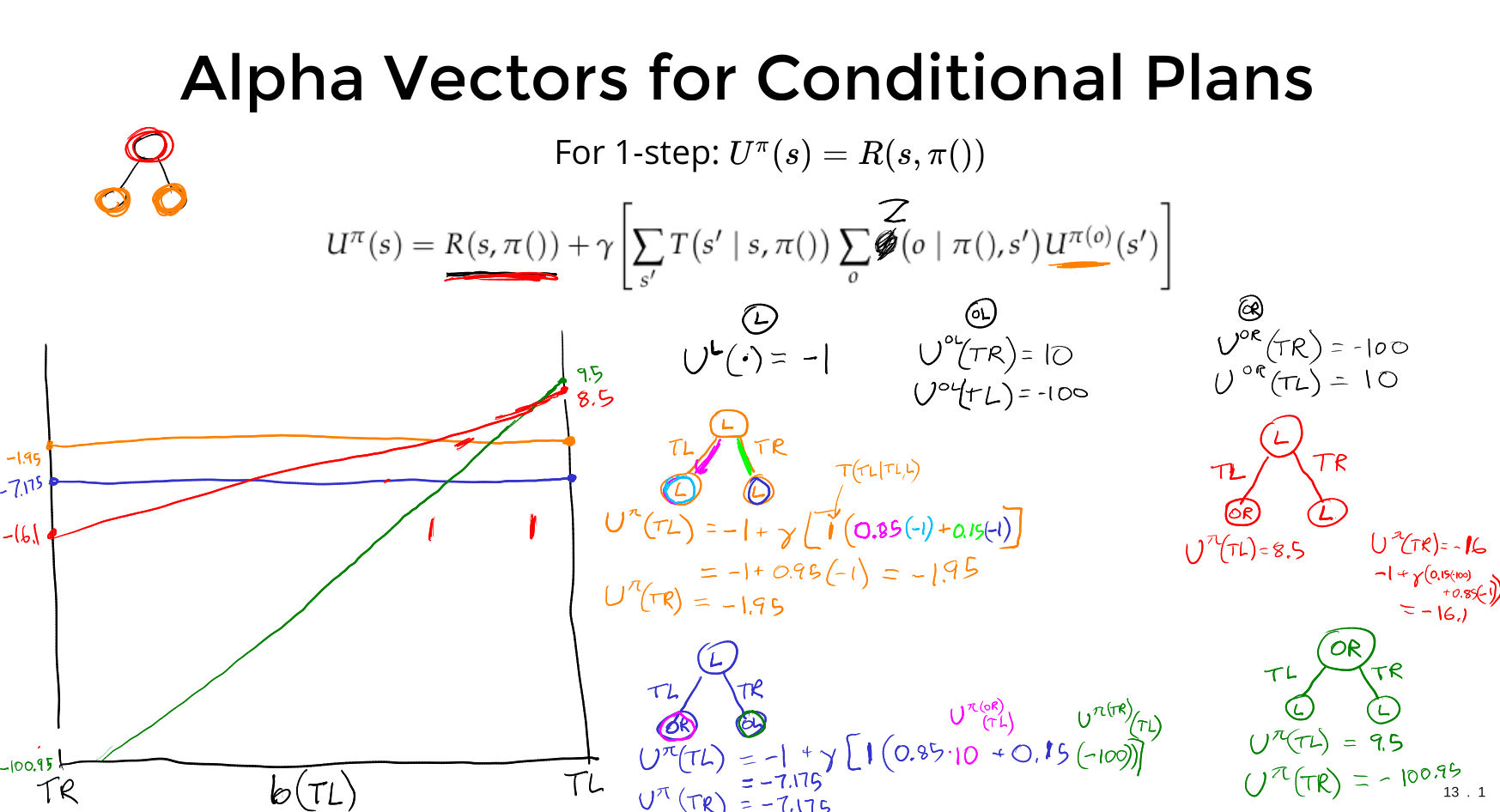
Assuming \(b_0 = \text{Bernoulli}(0.5)\)
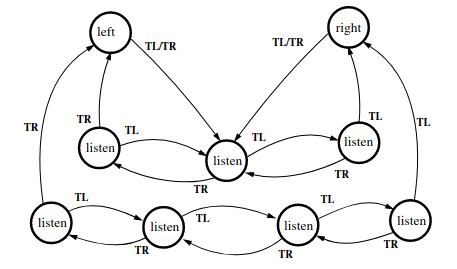
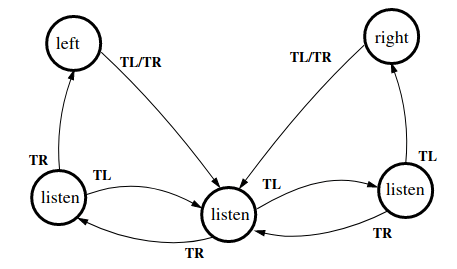
"Policy Graph" /
"Finite State Controller"
Policy Graphs

Monte Carlo Value Iteration (MCVI)

Monte Carlo Value Iteration (MCVI)


180 Offline POMDP Algorithms
By Zachary Sunberg



