DQN and Advanced Policy Gradient
Map
Map
Challenges:
- Exploration vs Exploitation
- Credit Assignment
- Generalization
Part I
DQN
Q-Learning with Neural Networks
Q-Learning:
\(Q(s, a) \gets Q(s, a) + \alpha\, \left(r + \gamma \max_{a'} Q(s', a') - Q(s, a)\right)\)
Neural Networks
\[\theta^* = \argmin_\theta \sum_{(x,y) \in \mathcal{D}} l(f_\theta(x), y)\]
\[\theta \gets \theta - \alpha \, \nabla_\theta\, l (f_\theta(x), y)\]
Deep Q learning:
- Approximate \(Q\) with \(Q_\theta\)
- What should \((x, y)\) be?
- What should \(l\) be?
Candidate Algorithm:
loop
\(a \gets \text{argmax} \, Q(s, a) \, \text{w.p.} \, 1-\epsilon, \quad \text{rand}(A) \, \text{o.w.}\)
\(r \gets \text{act!}(\text{env}, a)\)
\(s' \gets \text{observe}(\text{env})\)
\(\theta \gets \theta - \alpha\, \nabla_\theta \left( r + \gamma \max_{a'} Q_\theta (s', a') - Q_\theta (s, a)\right)^2\)
\(s \gets s'\)
DQN: The Atari Benchmark




DQN: Problems with Naive Approach
Candidate Algorithm:
loop
\(a \gets \text{argmax} \, Q(s, a) \, \text{w.p.} \, 1-\epsilon, \quad \text{rand}(A) \, \text{o.w.}\)
\(r \gets \text{act!}(\text{env}, a)\)
\(s' \gets \text{observe}(\text{env})\)
\(\theta \gets \theta - \alpha\, \nabla_\theta \left( r + \gamma \max_{a'} Q_\theta (s', a') - Q_\theta (s, a)\right)^2\)
\(s \gets s'\)
Problems:
- Samples Highly Correlated
- Size-1 batches
- Moving target
DQN
Q Network Structure:
Experience Tuple: \((s, a, r, s')\)
Loss:
\[l(s, a, r, s') = \left(r+\gamma \max_{a'} Q_{\theta'}(s', a') - Q_\theta (s, a)\right)^2\]
DQN
Q Network Structure:
Experience Tuple: \((s, a, r, s')\)
Loss:
\[l(s, a, r, s') = \left(r+\gamma \max_{a'} Q_{\theta'}(s', a') - Q_\theta (s, a)\right)^2\]






Rainbow
- Double Q Learning
- Prioritized Replay
(priority proportional to last TD error) - Dueling networks
Value network + advantage network
\(Q(s, a) = V(s) + A(s, a)\) - Multi-step learning
\((r_t + \gamma r_{t+1} + \ldots + \gamma^{n-1} r_{t+n-1} + \gamma \max Q_\theta(s_{t+n}, a') - Q_\theta(s_t, a_t))^2\) - Distributional RL
predict an entire distribution of values instead of just Q - Noisy Nets

Actual Learning Curves

Part II
Improved Policy Gradients
Policy Gradient
\[\widehat{\nabla_\theta U(\theta)} = \sum_{k=0}^d \nabla_\theta \log \pi_\theta (a_k \mid s_k) \gamma^{k} (r_{k,\text{to-go}}-r_\text{base}(s_k)) \]


\(\hat{Q}^\pi (s_k, a_k)\)
\(\hat{U}^\pi (s_k)\)
Advantage Function:
\(A(s, a) \equiv Q(s, a) - U(s)\)
loop:
\(\tau \gets \text{simulate\_episode}(\pi_\theta)\)
\(\widehat{\nabla_\theta U(\theta)} \gets \sum_{k=0}^d \nabla_\theta \log \pi_\theta (a_k \mid s_k) \gamma^{k}\,\hat{A}_k\)
\(\theta \gets \theta + \alpha \widehat{\nabla_\theta U(\theta)}\)
Some problems:
- \(\widehat{\nabla_\theta U(\theta)}\) has high variance
- The gradient is not a good step direction
- Fixed \(\alpha\) steps are too big or small
Restricted Gradient Update
\[\widehat{\nabla U}(\theta) = \sum_{k=0}^d \nabla_\theta \log \pi_\theta (a_k \mid s_k) \gamma^{k} (r_{k,\text{to-go}}-r_\text{base}(s_k)) \]
\[\theta' = \theta + \alpha \widehat{\nabla U}(\theta)\]
Trust Region Optimization
\[\widehat{\nabla U}(\theta) = \sum_{k=0}^d \nabla_\theta \log \pi_\theta (a_k \mid s_k) \gamma^{k} \, \hat{A}_k \]
Example:
\[g(\theta, \theta') = \lVert\theta-\theta'\rVert^2_2 = \frac{1}{2}(\theta' - \theta)^\top (\theta' - \theta)\]

\(\mathbf{u} = \nabla U(\theta)\)
\[\theta' = \theta + \alpha \widehat{\nabla U}(\theta)\]
\[U(\theta') \approx U(\theta) + \nabla U(\theta)^\top (\theta' - \theta)\]
\(\underset{\theta'}{\text{maximize}}\)
\(\text{subject to}\)
\[g(\theta, \theta') \leq \epsilon\]
Natural Gradient







Natural Gradient
Natural Gradient
Conservative Policy Iteration Objective
Policy Advantage
"Approximately Optimal Approximate RL" Kakade & Langford
\[\underset{\tau \sim \pi_\theta}{E}\left[\sum_{t=0}^\infty \gamma^t R(s_t, a_t)\right] \]
\[= \underset{\substack{s\sim b_{\gamma, \theta}\\ a \sim \pi_\theta(\cdot \mid s)}}{E}\left[R(s, a)\right] \]
Discounted Visitation Distribution
\[b_{\gamma, \theta}(s) \propto P(s_1 = s) + \gamma P(s_2 = s) + \gamma^2 P(s_3 = s) + \ldots\]
Trust Region Policy Optimization (TRPO)

Natural Gradient Approximation + Conservative Policy Iteration Objective
Update Step:
\[f(\theta, \theta') = \underset{\substack{s\sim b_{\gamma, \theta}\\ a \sim \pi_\theta(\cdot \mid s)}}{E} \left[\frac{\pi_{\theta'}(a \mid s)}{\pi_\theta (a \mid s)} A^{\pi_\theta}(s, a)\right]\]
\(\underset{\theta'}{\text{maximize}}\)
\(\text{subject to}\)
\[g(\theta, \theta') = \underset{s \sim b_{\gamma, \theta}}{\mathbb{E}} \left[ D_{\mathrm{KL}}(\pi_{\theta}(\cdot \mid s) \parallel \pi_{\theta'}(\cdot \mid s)) \right] \leq \epsilon\]
TRPO and PPO

TRPO = Trust Region Policy Optimization
(Natural gradient + line search)
PPO = Proximal Policy Optimization
(Use clamped surrogate objective to remove the need for line search)
Proximal Policy Optimization (PPO)
\[\underset{\substack{s\sim b_{\gamma, \theta}\\ a \sim \pi_\theta(\cdot \mid s)}}{E} \left[ \min \left( \frac{\pi_{\theta'}(a \mid s)}{\pi_{\theta}(a \mid s)} A_{\phi}(s, a), \operatorname{clamp}\left( \frac{\pi_{\theta'}(a \mid s)}{\pi_{\theta}(a \mid s)}, 1 - \epsilon, 1 + \epsilon \right) A_{\phi}(s, a) \right) \right]\]
Clipped Surrogate Objective:
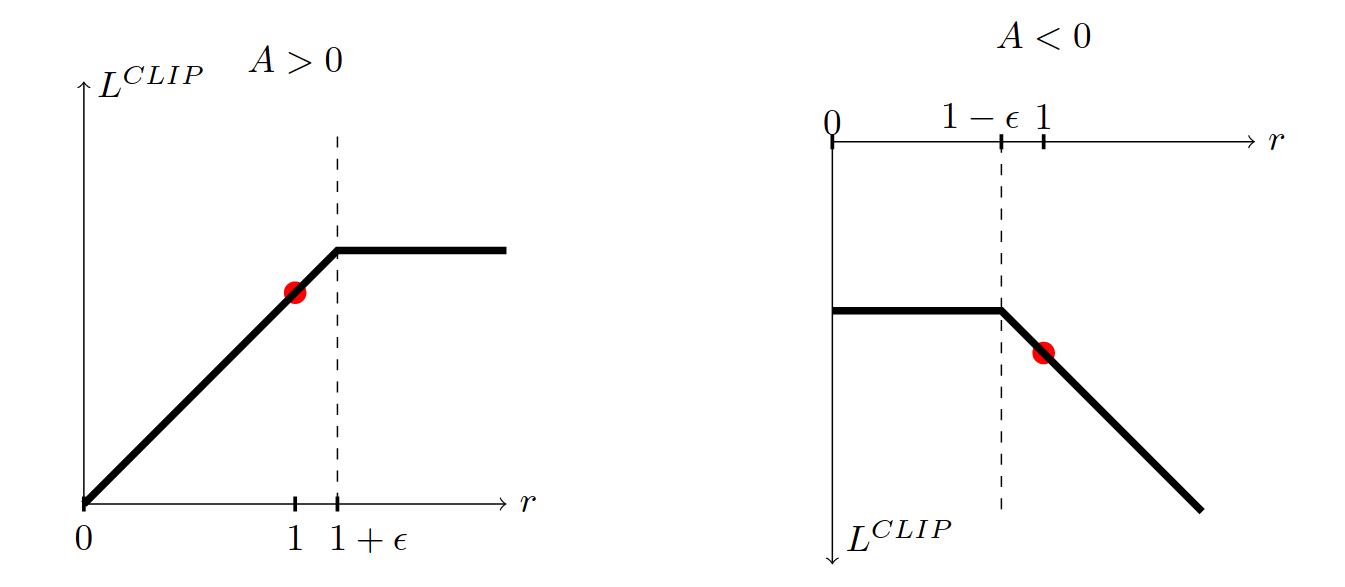
\[r = \frac{\pi_{\theta'}(a \mid s)}{\pi_{\theta}(a \mid s)}\]
Each step: take several gradient steps with trajectories from \(\pi_\theta\)
(No need for constraint because it will stop when it hits the clip)
PPO Impact
Cited 29262 times (as Gall 2025)

- John Schulman was a co-founder of OpenAI
- InstructGPT (first large-scale RLHF) used PPO to get a GPT model to obey human intent (crucial to get a language model to act as a chatbot)
- ChatGPT is a successor to InstructGPT
(avg ~10x per day)
But...
Implementation Matters
Implementation Matters in Deep Policy Gradients: A Case Study on PPO and TRPO
Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Firdaus Janoos, Larry Rudolph, and Aleksander Madry; ICLR 2020
Implementation Details
- Value function clipping
- Reward scaling
- Orthogonal initialization and layer scaling
- Adam learning rate annealing
- Reward clipping
- Observation normalization
- Observation clipping
- Hyperbolic tan activations
- Global gradient clipping
"PPO’s marked improvement over TRPO (and even stochastic gradient descent) can be largely attributed to these optimizations."
Andrychowicz M, Raichuk A, Stańczyk P, et al. What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study. arXiv. Preprint posted online June 10, 2020:arXiv:2006.05990. doi:10.48550/arXiv.2006.05990
Part III
Actor-Critic
Actor-Critic
Actor-Critic
\[\nabla U(\theta) = E_\tau \left[\sum_{k=0}^d \nabla_\theta \log \pi_\theta (a_k \mid s_k) \gamma^{k} (r_{k,\text{to-go}}-r_\text{base}(s_k)) \right]\]
Advantage Function: \(A(s, a) = Q(s, a) - V(s)\)
- Actor: \(\pi_\theta\)
- Critic: \(Q_\phi\) and/or \(A_\phi\) and/or \(V_\phi\)
Can we combine value-based and policy-based methods?
Alternate between training Actor and Critic
Problem: Instability
Actor-Critic
Which should we learn? \(A\), \(Q\), or \(V\)?
\[\nabla U(\theta) = E_\tau \left[\sum_{k=0}^d \nabla_\theta \log \pi_\theta (a_k \mid s_k) \gamma^{k} (r_k + \gamma V_\phi (s_{k+1}) - V_\phi (s_k))) \right]\]
\(l(\phi) = E\left[\left(V_\phi(s) - V^{\pi_\theta}(s)\right)^2\right]\)
Generalized Advantage Estimation
Generalized Advantage Estimation
\(A(s_k, a_k) \approx r_k + \gamma V_\phi (s_{k+1}) - V_\phi (s_k)\)
\(A(s_k, a_k) \approx \sum_{t=k}^\infty \gamma^{t-k} r_t - V_\phi (s_k) \)
\(A(s_k, a_k) \approx r_k + \gamma r_{k+1} + \ldots + \gamma^d r_{k+d} + \gamma^{d+1} V_\phi (s_{k+d+1}) - V_\phi (s_k)\)
let \(\delta_t = r_t + \gamma V_\phi (s_{t+1}) - V_\phi (s_t)\)
\[A_\text{GAE}(s_k, a_k) \approx \sum_{t=k}^\infty (\gamma \lambda)^{t-k} \delta_t\]
let \(\delta_t = r_t + \gamma V_\phi (s_{t+1}) - V_\phi (s_t)\)
Recap
Alpha Zero: Actor Critic with MCTS
- Use \(\pi_\theta\) and \(U_\phi\) in MCTS
- Learn \(\pi_\theta\) and \(U_\phi\) from tree

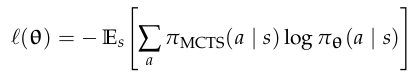



140 DQN and Advanced Policy Gradient
By Zachary Sunberg



