Safety and Efficiency through POMDP planning
Zachary Sunberg
Assistant Professor
CU Boulder
How do we deploy autonomy with confidence?
Safety and Efficiency through Online Bayesian Learning


Waymo Image By Dllu - Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=64517567



Two Objectives for Autonomy
EFFICIENCY
SAFETY
Minimize resource use
(especially time)
Minimize the risk of harm to oneself and others


Safety often opposes Efficiency
Pareto Optimization
Safety
Better Performance
Model \(M_2\), Algorithm \(A_2\)
Model \(M_1\), Algorithm \(A_1\)
Efficiency
$$\underset{\pi}{\mathop{\text{maximize}}} \, J^\pi = J^\pi_\text{E} + \lambda J^\pi_\text{S}$$
Safety
Weight
Efficiency
Types of Uncertainty
Alleatory
Epistemic (Static)
Epistemic (Dynamic)



Markov Decision Process
$$\underset{\pi}{\mathop{\text{maximize}}} \sum_{t=0}^\infty \gamma^t R(s_t, a_t)$$
$$s_{t+1} = f(s_t, a_t, w_t)$$
Policy: \(a_t = \pi(s_t)\)
Markov Decision Process (MDP)
- \(\mathcal{S}\) - State space
- \(T:\mathcal{S}\times \mathcal{A} \times\mathcal{S} \to \mathbb{R}\) - Transition probability distribution
- \(\mathcal{A}\) - Action space
- \(R:\mathcal{S}\times \mathcal{A} \to \mathbb{R}\) - Reward

Partially Observable MDP (POMDP)
$$\underset{\pi}{\mathop{\text{maximize}}} \sum_{t=0}^\infty \gamma R(s_t, a_t)$$
$$s_{t+1} = f(s_t, a_t, w_t)$$
Policy: \(a_t = \pi(a_0, o_0, a_1, o_1, ... o_{t-1})\)
$$o_{t} = h(s_t, a_t, s_{t+1}, v_t)$$
Partially Observable Markov Decision Process (POMDP)

- \(\mathcal{S}\) - State space
- \(T:\mathcal{S}\times \mathcal{A} \times\mathcal{S} \to \mathbb{R}\) - Transition probability distribution
- \(\mathcal{A}\) - Action space
- \(R:\mathcal{S}\times \mathcal{A} \to \mathbb{R}\) - Reward
- \(\mathcal{O}\) - Observation space
- \(Z:\mathcal{S} \times \mathcal{A}\times \mathcal{S} \times \mathcal{O} \to \mathbb{R}\) - Observation probability distribution
\begin{aligned}
& \mathcal{S} = \mathbb{Z} \quad \quad \quad ~~ \mathcal{O} = \mathbb{R} \\
& s' = s+a \quad \quad o \sim \mathcal{N}(s, s-10) \\
& \mathcal{A} = \{-10, -1, 0, 1, 10\} \\
& R(s, a) = \begin{cases}
100 & \text{ if } a = 0, s = 0 \\
-100 & \text{ if } a = 0, s \neq 0 \\
-1 & \text{ otherwise}
\end{cases} & \\
\end{aligned}

State
Timestep
Accurate Observations
Goal: \(a=0\) at \(s=0\)
Optimal Policy
Localize
\(a=0\)
POMDP Example: Light-Dark
POMDP Sense-Plan-Act Loop
Environment
Belief Updater
Policy
\(b\)
\(a\)
\[b_t(s) = P\left(s_t = s \mid a_1, o_1 \ldots a_{t-1}, o_{t}\right) \\ \quad\quad\quad\propto Z(o_{t} \mid a_t, s_t) \sum_s T(s_t \mid a_{t-1}, s) b_{t-1}(s)\]

True State
\(s = 7\)
Observation \(o = -0.21\)
Tiger POMDP
- Two doors, tiger is behind one, freedom is behind other
- At each time step, you can either open one or listen
- If you listen, you will hear the tiger behind one of the doors with 85% accuracy
- Write down \((S,A,O,T,Z,R)\)
- Propose a heuristic policy
Practice Problem (in Groups)
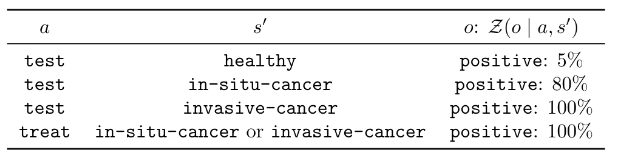
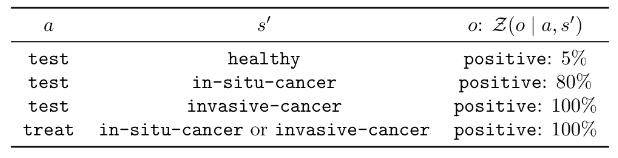
Cancer Screening and Treatment
- In the absence of treatment: Each year a patient has a 2% chance of developing in-situ cancer. Each year that they have in-situ cancer, they have a 10% chance of developing invasive cancer. Each year they have invasive cancer, they have a 60% chance of death.
- Doctors can choose to wait, test, or treat a patient. Testing has a true positive rate of 80% and a false positive rate of 5%. Treatment has a success rate of 60% for in-situ cancer and 20% for invasive cancer. Treatment also reduces the death rate for invasive cancer to 20%.
Your Task:
- Write down \((S, A, O, T, Z, R)\)
- Propose a heuristic policy

Practice Problem Solution


Solving MDPs - The Value Function
$$V^*(s) = \underset{a\in\mathcal{A}}{\max} \left\{R(s, a) + \gamma E\Big[V^*\left(s_{t+1}\right) \mid s_t=s, a_t=a\Big]\right\}$$
Involves all future time
Involves only \(t\) and \(t+1\)
$$\underset{\pi:\, \mathcal{S}\to\mathcal{A}}{\mathop{\text{maximize}}} \, V^\pi(s) = E\left[\sum_{t=0}^{\infty} \gamma^t R(s_t, \pi(s_t)) \bigm| s_0 = s \right]$$
$$Q(s,a) = R(s, a) + \gamma E\Big[V^* (s_{t+1}) \mid s_t = s, a_t=a\Big]$$
Value = expected sum of future rewards
Go-to Tools for Solving MDPs
- Offline: Value Iteration
- Online: Monte Carlo Tree Search
Value Iteration

Repeatedly Apply Bellman Equation
Value Iteration
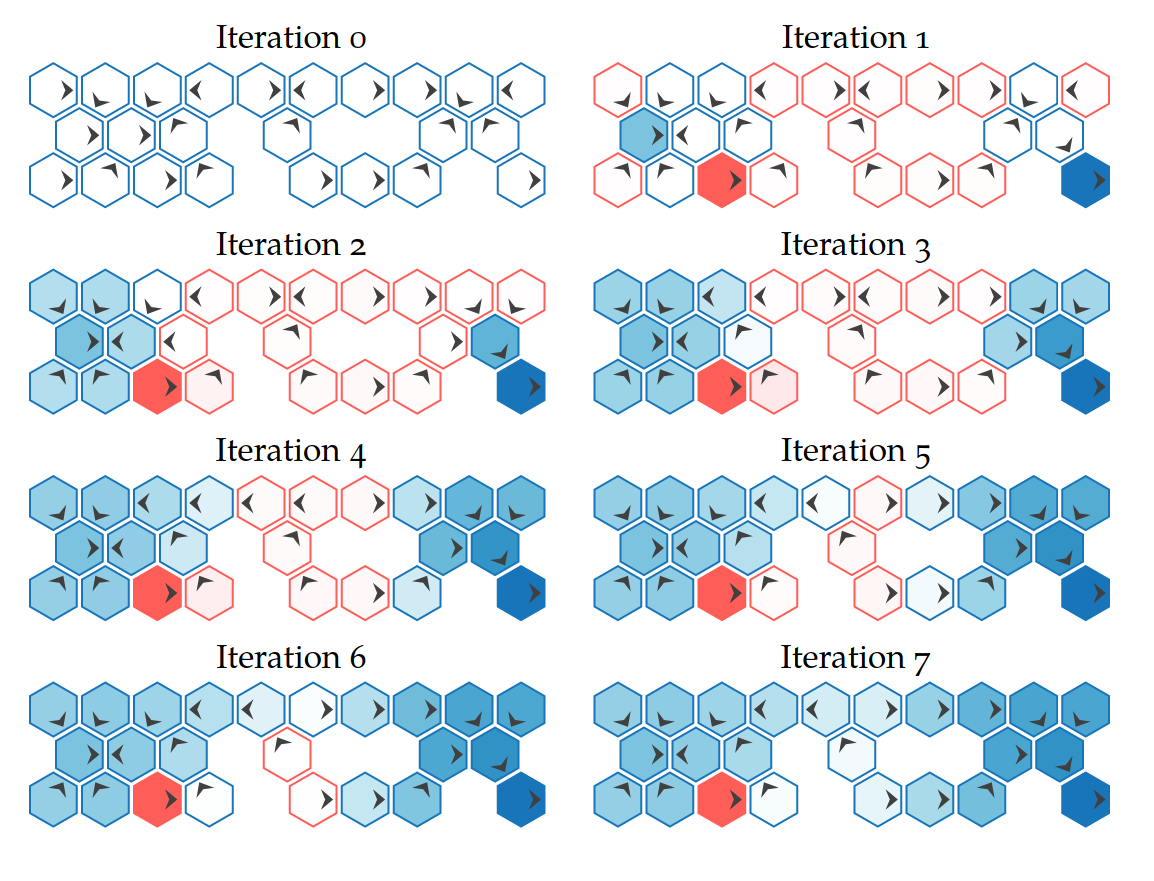
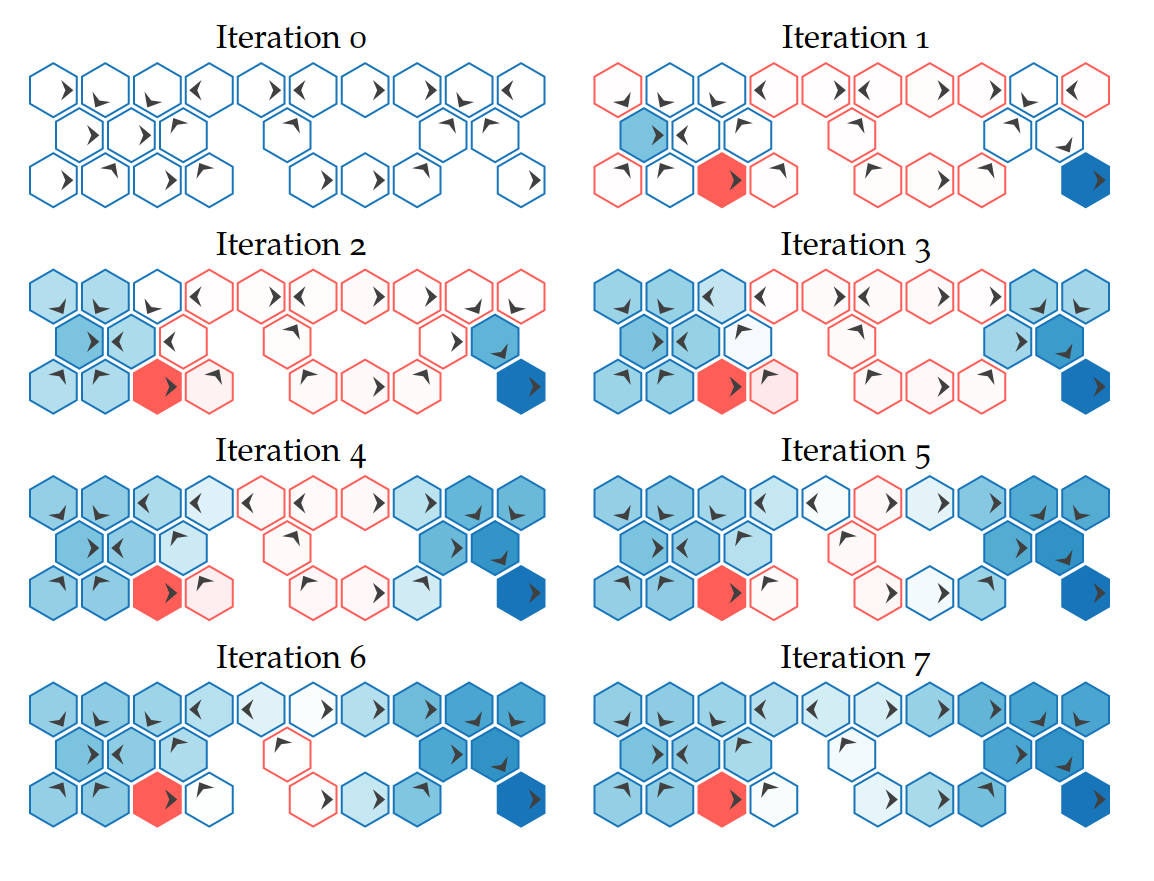
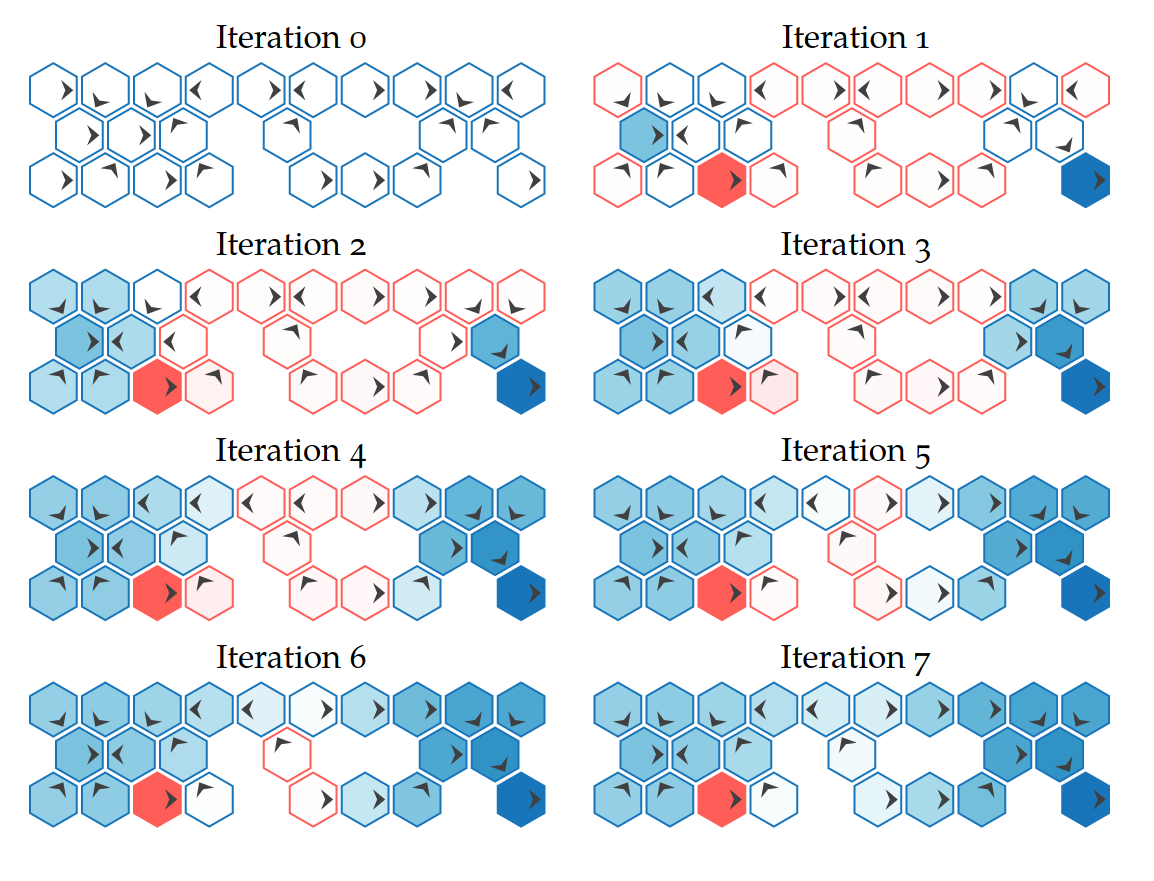
Online: Tree Search

Time
Estimate \(Q(s, a)\) based on children
$$Q(s,a) = R(s, a) + \gamma E\Big[V^* (s_{t+1}) \mid s_t = s, a_t=a\Big]$$
\[V(s) = \max_a Q(s,a)\]

Monte Carlo Tree Search
Image by Dicksonlaw583 (CC 4.0)
Go-to Tools for Solving POMDPs
- Offline: Point-Based Value Iteration (SARSOP)
- Online: Monte Carlo Tree Search
POMDP Sense-Plan-Act Loop
Environment
Belief Updater
Policy

\(o\)
\(b\)
\(a\)
- A POMDP is an MDP on the Belief Space but belief updates are expensive
- POMCP* uses simulations of histories instead of full belief updates
- Each belief is implicitly represented by a collection of unweighted particles

[Ross, 2008] [Silver, 2010]
*(Partially Observable Monte Carlo Planning)
Autonomous Driving Example
Tweet by Nitin Gupta
29 April 2018
https://twitter.com/nitguptaa/status/990683818825736192

Intelligent Driver Model (IDM)
\ddot{x}_\text{IDM} = a \left[ 1 - \left( \frac{\dot{x}}{\dot{x}_0} \right)^{\delta} - \left(\frac{g^*(\dot{x}, \Delta \dot{x})}{g}\right)^2 \right]
g^*(\dot{x}, \Delta \dot{x}) = g_0 + T \dot{x} + \frac{\dot{x}\Delta \dot{x}}{2 \sqrt{a b}}

[Treiber, et al., 2000] [Kesting, et al., 2007] [Kesting, et al., 2009]
Internal States
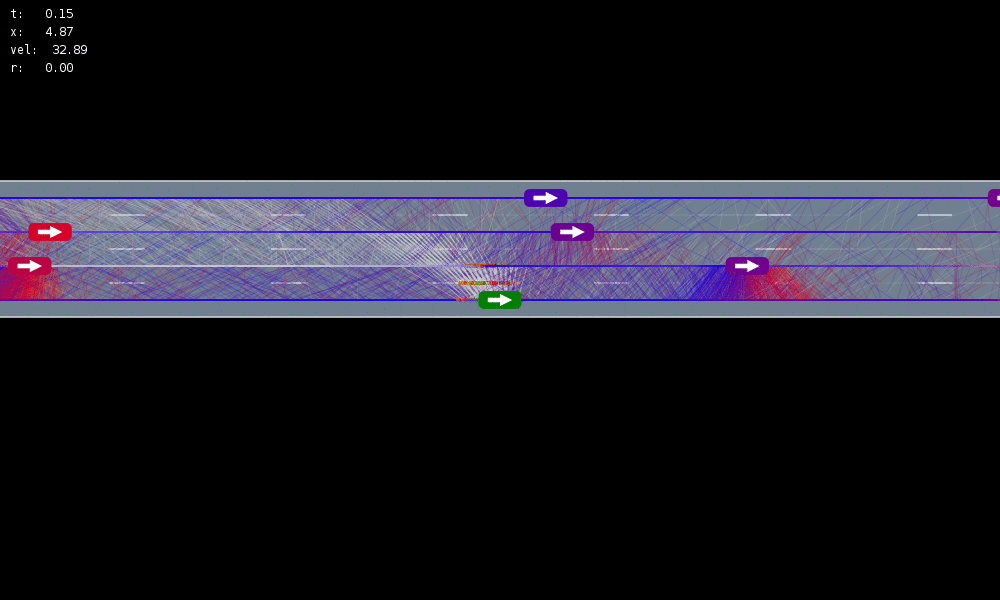






All drivers normal



No learning (MDP)
Omniscient
POMCPOW (Ours)
Simulation results
[Sunberg, 2017]



Marginal Distribution: Uniform
\(\rho=0\)
\(\rho=1\)
\(\rho=0.75\)
Internal parameter distributions
Conditional Distribution: Copula
Assume normal


No Learning (MDP)
Omniscient
Mean MPC
QMDP
POMCPOW (Ours)






[Sunberg, 2017]
Actions
Observations
States
POMDPs with Continuous...
- PO-UCT (POMCP)
- DESPOT
Actions
Observations
States
POMDPs with Continuous...
- PO-UCT (POMCP)
- DESPOT
Actions
Observations
States
POMDPs with Continuous...
- PO-UCT (POMCP)
- DESPOT
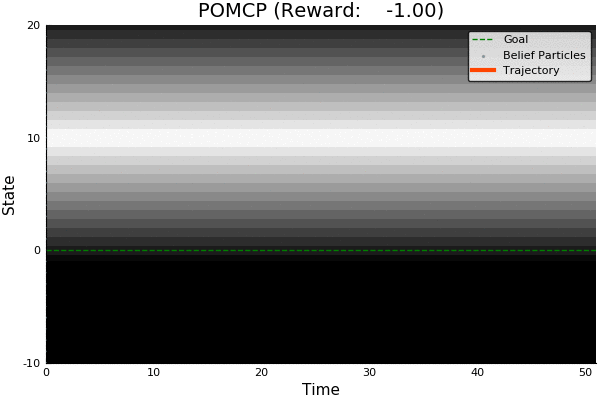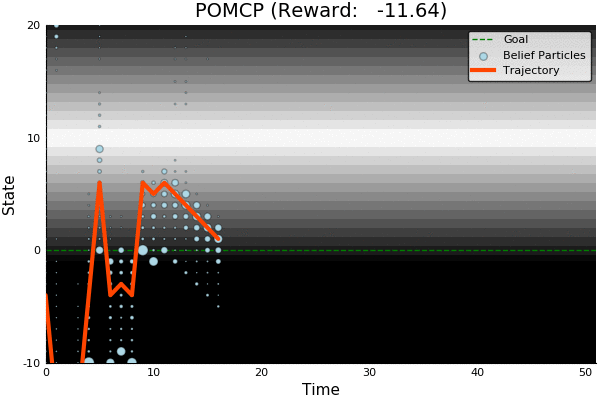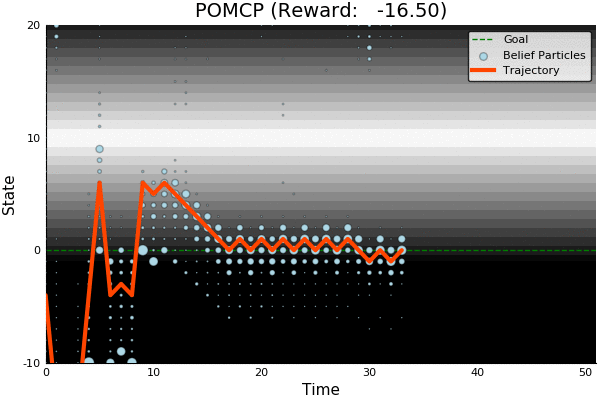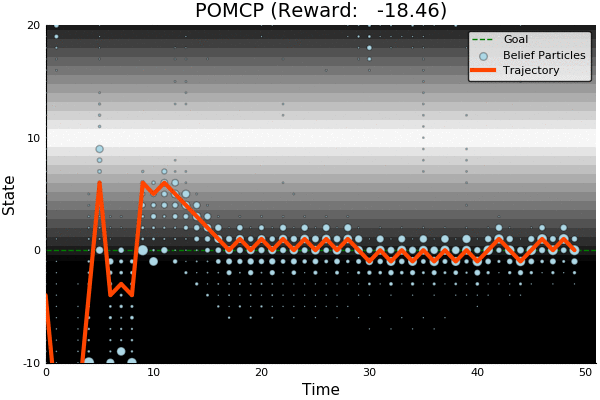

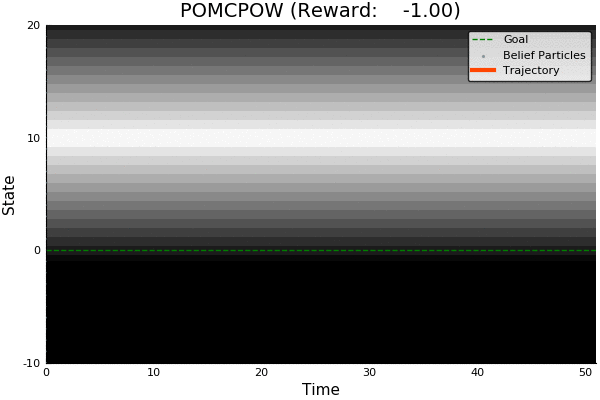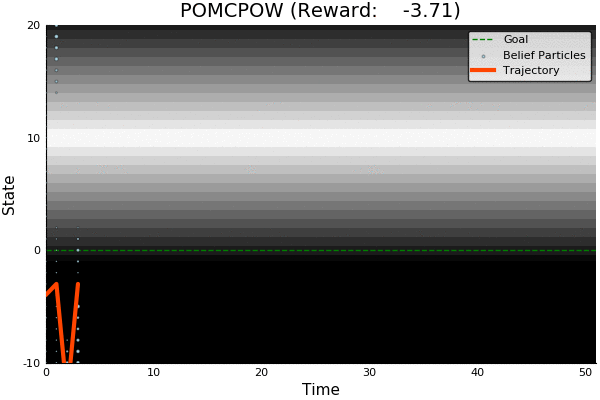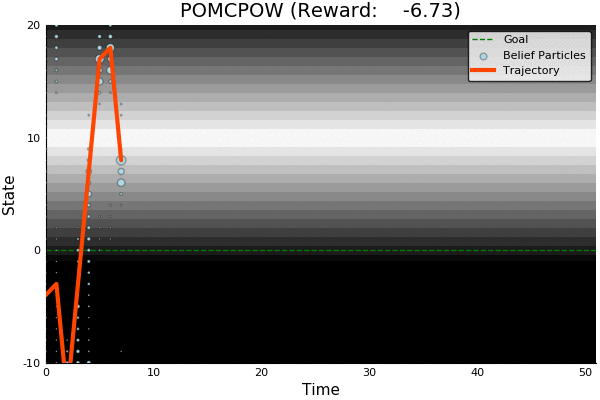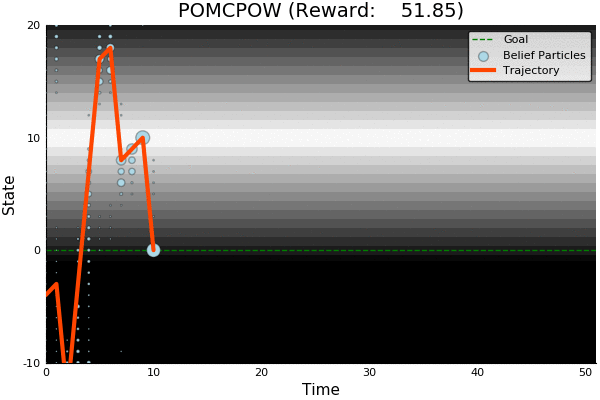



POMCP
POMCP-DPW
POMCPOW
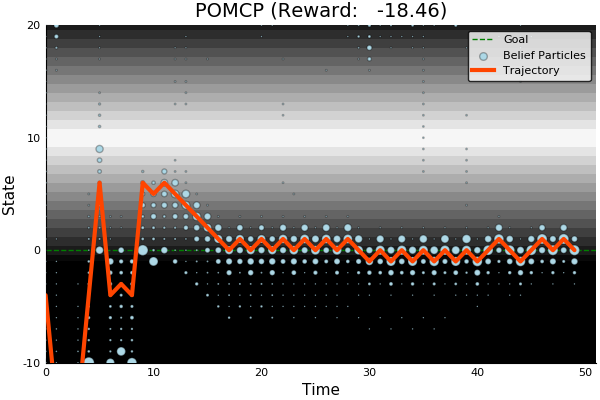
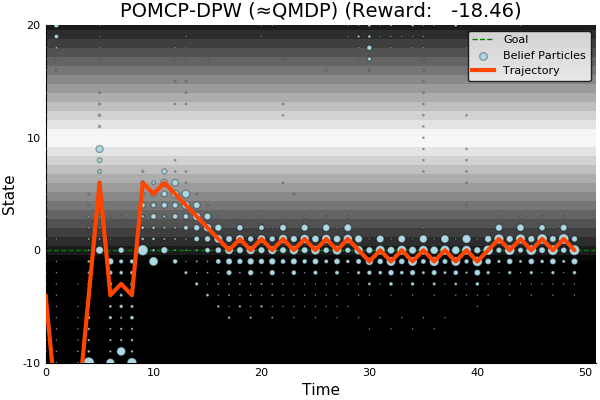
-18.46
-18.46
51.85
POMDP Planning with Image Observations
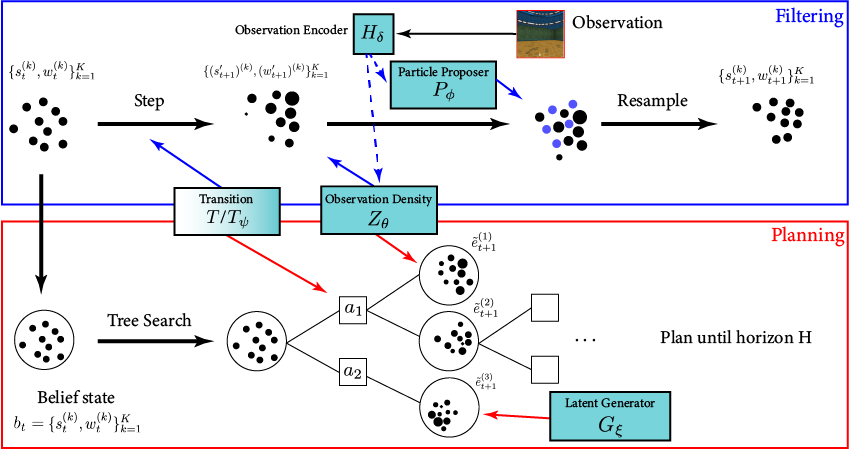



Actions
Observations
States
POMDPs with Continuous...
- PO-UCT (POMCP)
- DESPOT
- POMCPOW
- DESPOT-α
- LABECOP
- GPS-ABT
- VG-MCTS
- BOMCP
- VOMCPOW
Value Gradient MCTS

$$a' = a + \eta \nabla_a Q(s, a)$$

Voronoi Progressive Widening
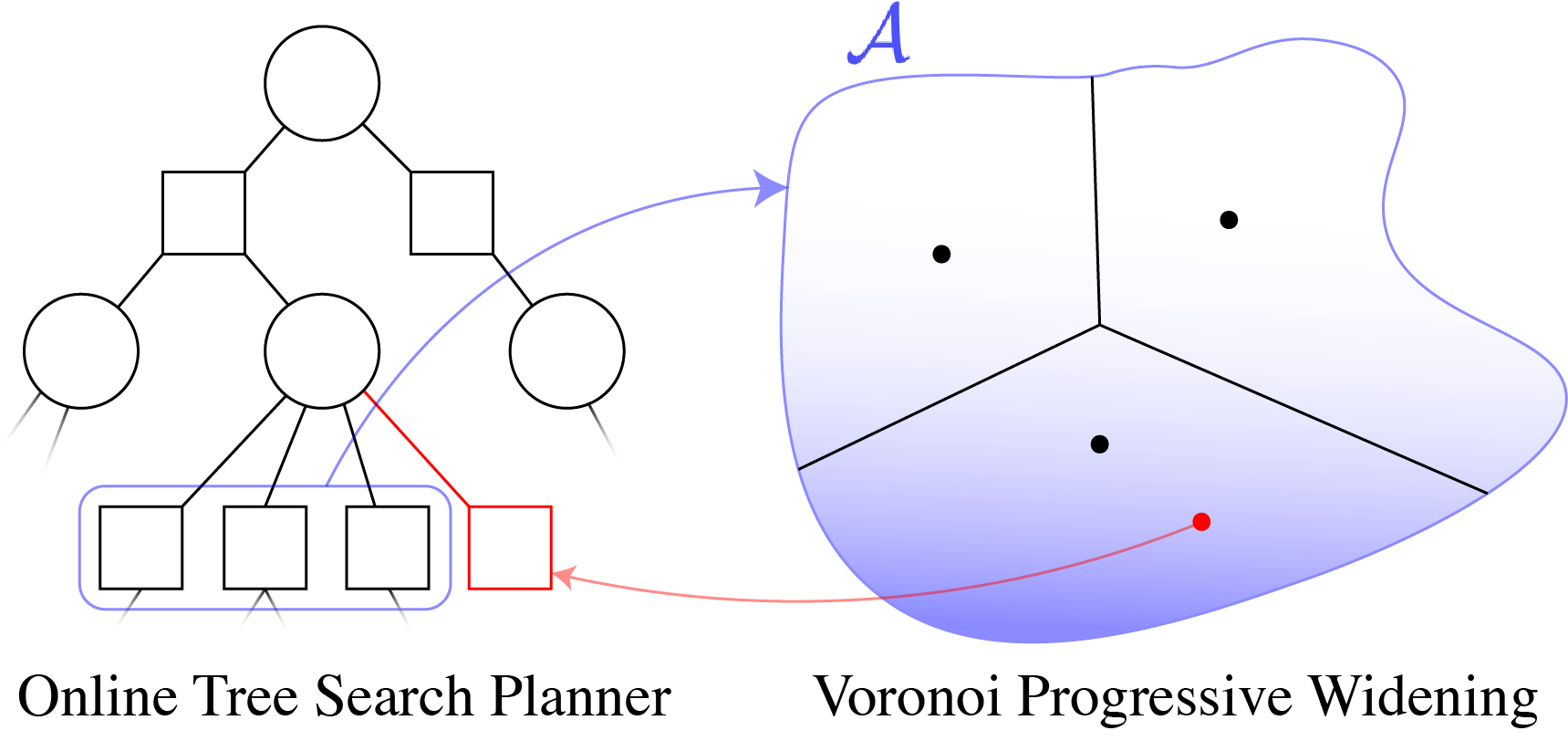
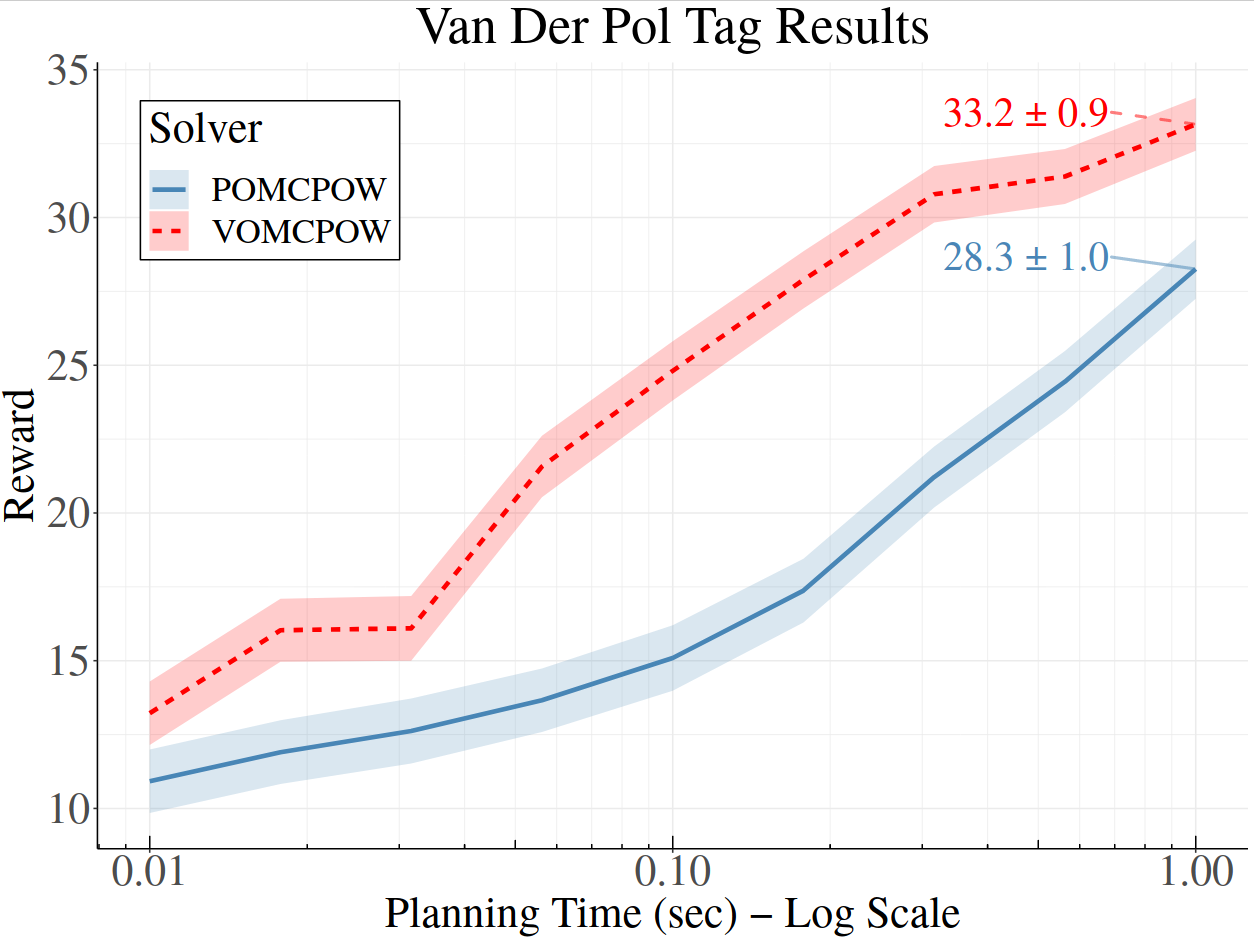

[Lim, Tomlin, & Sunberg CDC 2021]
BOMCP


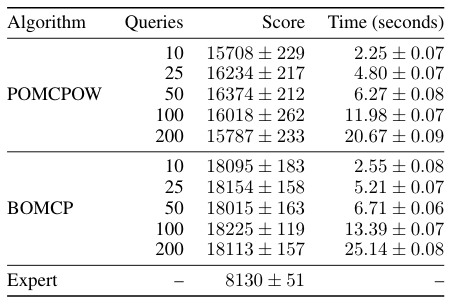
[Mern, Sunberg, et al. AAAI 2021]

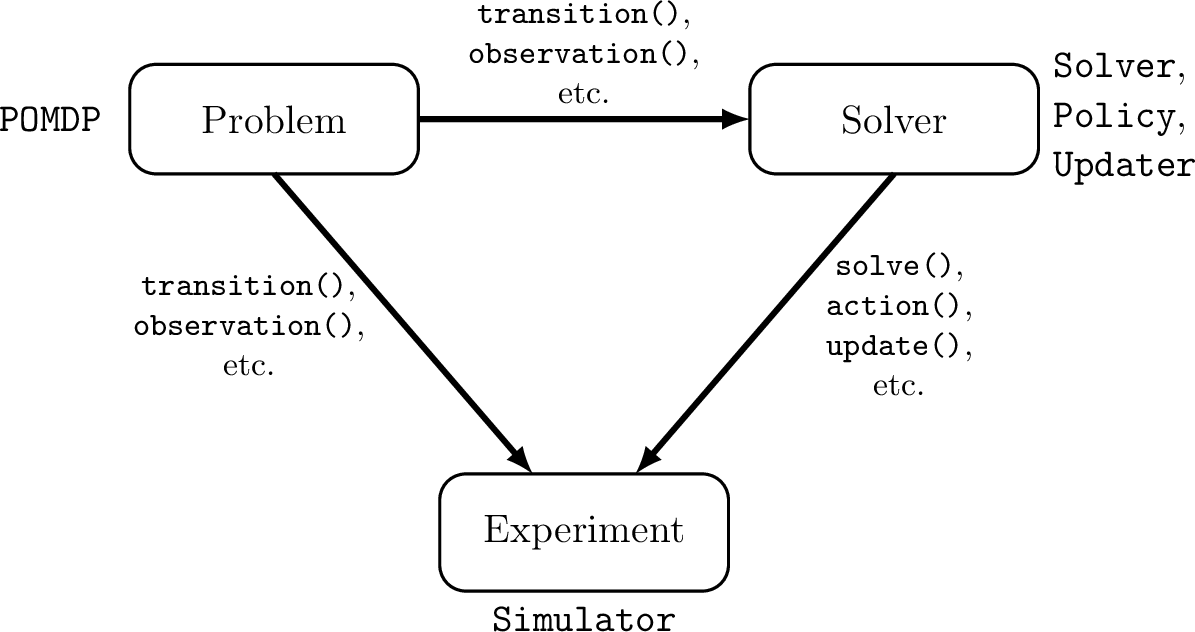
POMDPs.jl - An interface for defining and solving MDPs and POMDPs in Julia
[Egorov, Sunberg, et al., 2017]
Julia - Speed

Celeste Project
1.54 Petaflops

Previous C++ framework: APPL
"At the moment, the three packages are independent. Maybe one day they will be merged in a single coherent framework."
[Egorov, Sunberg, et al., 2017]



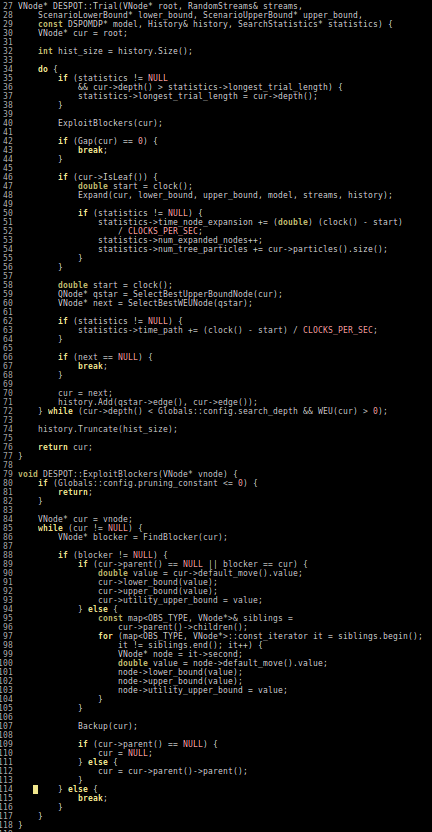
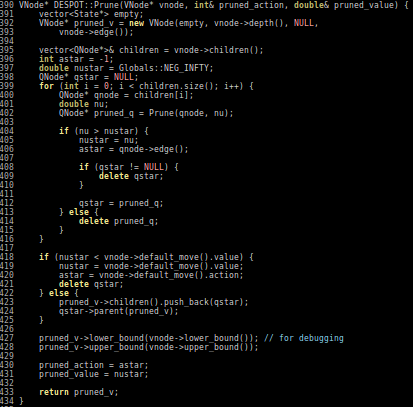
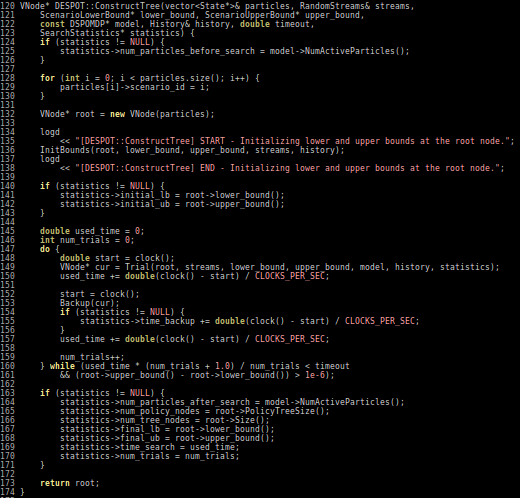
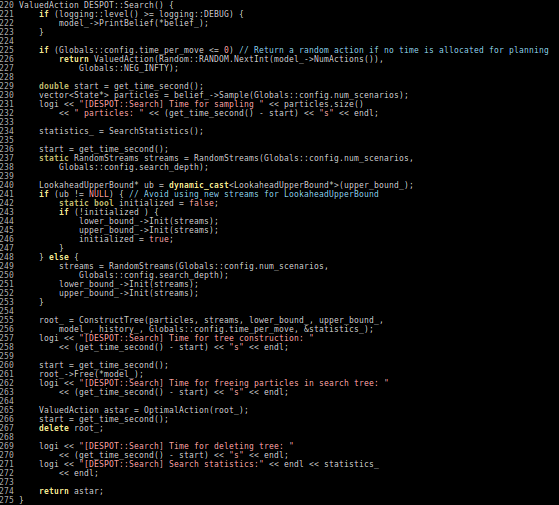
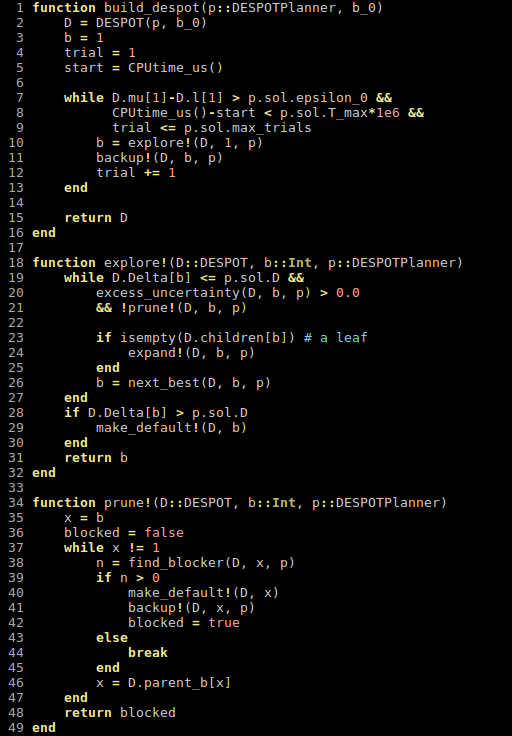
Cheat Sheet Questions (For Online POMDP Planning)
- When is this a good method to use?
- When reducing epistemic uncertainty can improve safety without sacrificing efficiency
- When is this not a good method to use?
- It is not suitable for use as the only system to guarantee safety
Cheat Sheet Questions (For Online POMDP Planning)
- What resources would you recommend to learn the theory behind this method?
- "Decision Making under Uncertainty", "Algorithms for Decision Making" (algorithmsbook.com) by Kochenderfer
- What resources would you recommend to learn the tools and implementation for this method?
- algorithmsbook.com, POMDPs.jl, implement your own!
Cheat Sheet Questions (For Online POMDP Planning)
- What are the major future research challenges for this method and safety for autonomous systems in general?
- Specifying Reward Functions (alignment problem)
- Tractable Guarantees for Uncertain Systems
- Handling Situations outside the Training Data
Thank You!

Acknowledgements
The content of my research reflects my opinions and conclusions, and is not necessarily endorsed by my funding organizations.















Guest Lecture
By Zachary Sunberg



