RL for POMDPs
4 Approaches
Approach 1: k-Markov




Approach 2: Recurrent Neural Network
e.g. Alpha Star
Images: Pascanu 2013
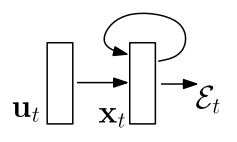
Input: \(u_t\)
State/Output: \(x_t\)
Cost: \(\mathcal{E}_t\)
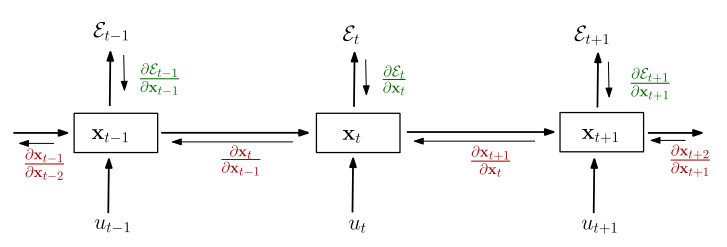
Training: Unrolling through time
Problem: Exploding/Vanishing Gradients
Approach 2: Recurrent Neural Network
e.g. Alpha Star
Images: Pascanu 2013
Input: \(u_t\)
State/Output: \(x_t\)
Cost: \(\mathcal{E}_t\)
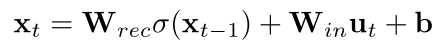
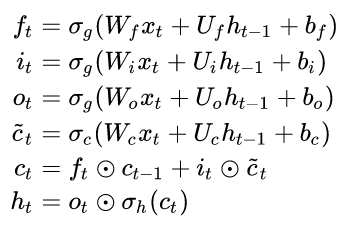
Input: \(x_t\)
Output: \(h_t\)
Cell state: \(c_t\)
Forget gate
Input Gate
Output Gate
Hochreiter, S. and Schmidhuber, J. (1997). Long Short-Term Memory. 1780, 1735–1780.
By Guillaume Chevalier - File:The_LSTM_Cell.svg, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=109362147

\(f_t\)
\(i_t\)
\(o_t\)
\(\tilde{c}_t\)
Approach 2: Recurrent Neural Network
Long Short-Term Memory (LSTM)
Approach 3: Particle Filters and MGF Features

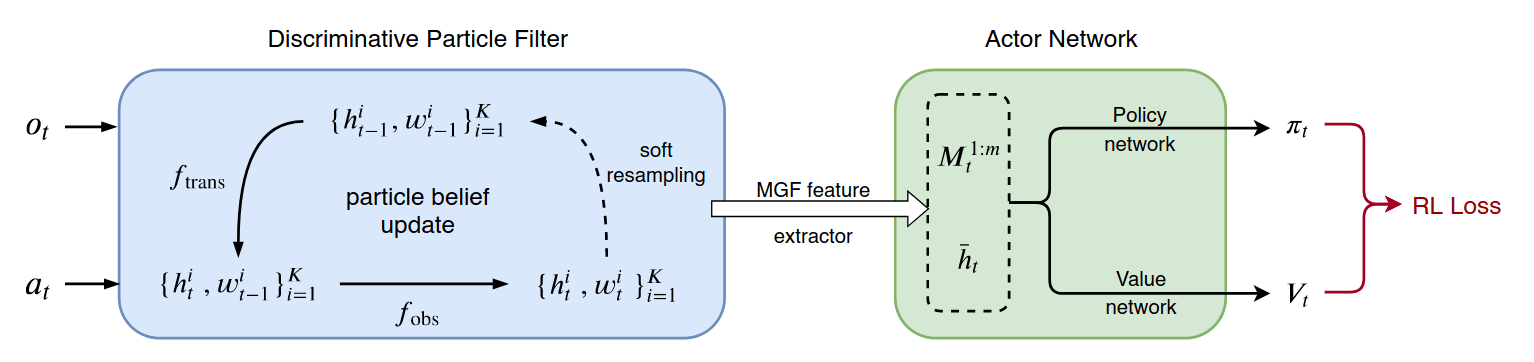
Approach 3: Particle Filters and MGF Features
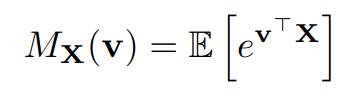
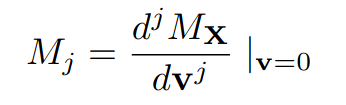
Approach 4: Latent Representations (e.g. World Models)
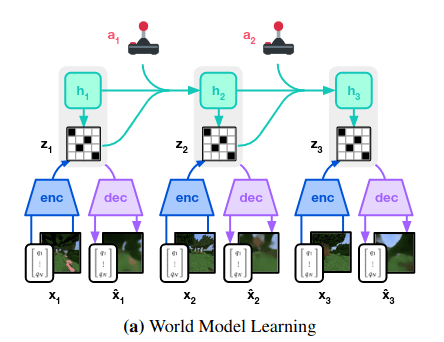

Approach 4: Latent Representations (e.g. World Models)
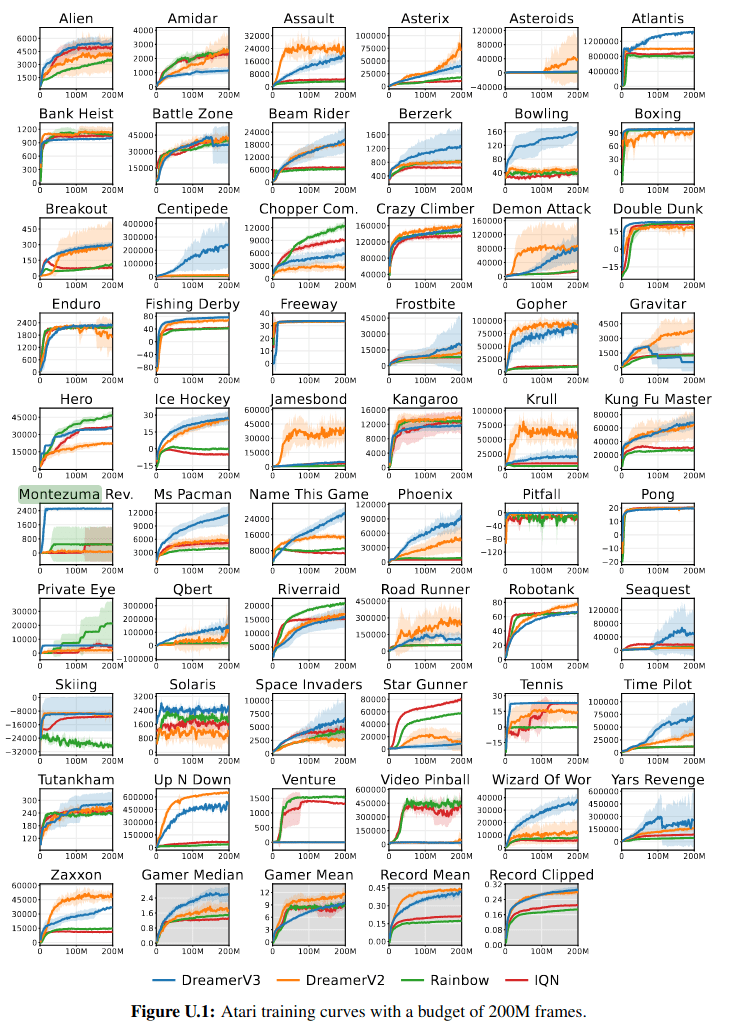
214 RL for POMDPs
By Zachary Sunberg



