Online Methods
Last Time
-
Does value iteration always converge?
-
Is the value function unique?
Last Time
- Policy Iteration
- Value Iteration
- Does Value Iteration always converge?
- Is the optimal value function unique?
Guiding Questions
-
What are the differences between online and offline solutions?
-
Are there solution techniques that require computation time independent of the state space size?
Why Do We Need Something Else?
-
Problems Policy and Value Iteration may struggle with?
-
Path planning across the country, or interplanetary
-
More realistic car dynamics (continuous states)
-
- Why are these problems hard?
- State Space is massive (or infinite)
Curse of Dimensionality
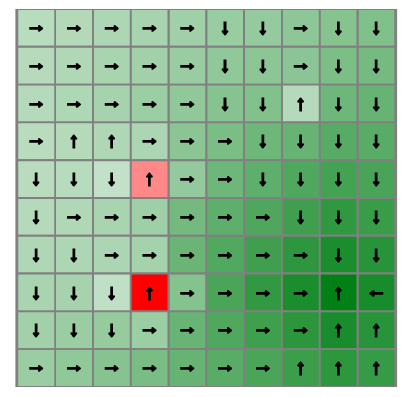
\(d\) dimensions, \(k\) segments \(\,\rightarrow \, |S| = k^d\)



1 dimension
e.g. \(s = x \in S = \{1,2,3,4,5\}\)
\(|S| = 5\)
2 dimensions
e.g. \(s = (x,y) \in S = \{1,2,3,4,5\}^2\)
\(|S| = 25\)
3 dimensions
e.g. \(s = (x,y,x_h) \in S = \{1,2,3,4,5\}^3\)
\(|S| = 125\)
(Discretize each dimension into 5 segments)

\(x\)
\(y\)
\(x_h\)

Offline vs Online Solutions
Offline
- Before Execution: find \(V^*\)/\(Q^*\)
- During Execution: \(\pi^*(s) = \text{argmax} \, Q^*(s, a)\)
Online
- Before Execution: <nothing>
- During Execution: Consider actions and their consequences (everything)
- Why?
- Online methods are insensitive to the size of \(S\) !
Rollout Lookahead




Forward Search
\((|S|\times|A|)^d\)

Forward Search
\((|S|\times|A|)^d\)

Forward Search depth
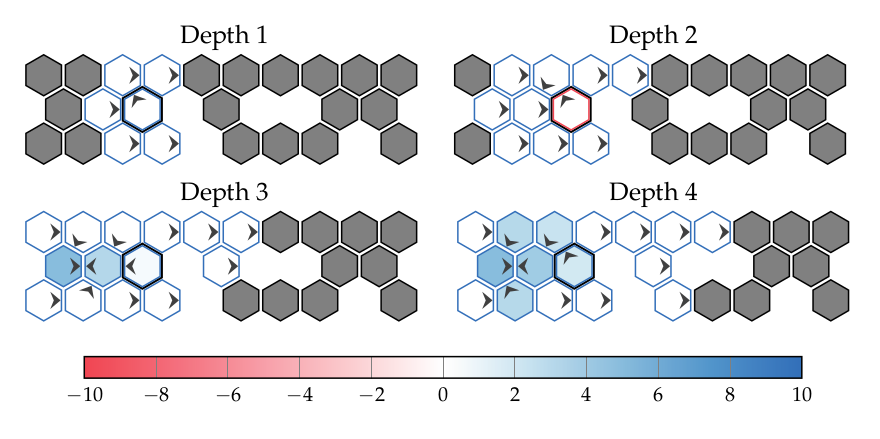
Sparse Sampling
\((n|A|)^d\)
\[|V^{\text{SS}}(s) - V^*(s)| \leq \epsilon\]
\(n\), \(\epsilon\), and \(d\) related, but independent of \(|S|\)

Sparse Sampling

\((m|A|)^d\)
\[|V^{\text{SS}}(s) - V^*(s)| \leq \epsilon\]
\(m\), \(\epsilon\), and \(d\) related, but independent of \(|S|\)
Break
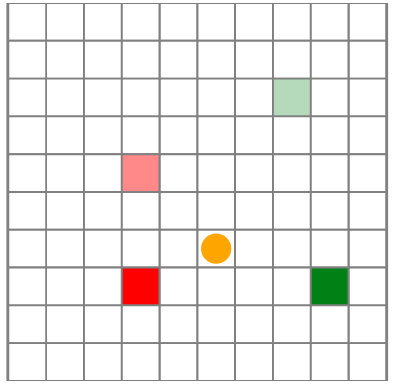
Draw the trees produced by the following algorithms for a problem with 2 actions and 3 states:
- One-step lookahead with rollout
- Forward search (d=2)
- Sparse sampling (d=2, n=2)
Branch and Bound

Assume you have \(\underline{V}(s)\) and \(\bar{Q}(s, a)\)
Monte Carlo Tree Search (MCTS/UCT)
Keep track of:
\(Q(s,a)\): Value estimate of that state and action combo
\(N(s,a)\): Number of times we visit a state and action combo
\[Q(s, a) + c \sqrt{\frac{\log N(s)}{N(s,a)}}\]
low \(N(s, a)/N(s)\) = high bonus
start with \(c = 2(\bar{V} - \underline{V})\), \(\beta = 1/4\)
\[Q(s, a) + c \frac{N(s)^\beta}{\sqrt{N(s, a)}}\]
Full story can be found in https://arxiv.org/pdf/1902.05213.pdf
Monte Carlo Tree Search (MCTS/UCT)

Monte Carlo Tree Search (MCTS/UCT)


Monte Carlo Tree Search (MCTS/UCT)
Search
Expansion
Rollout
Backup
\[Q(s, a) + c \sqrt{\frac{\log N(s)}{N(s,a)}}\]
low \(N(s, a)/N(s)\) = high bonus
start with \(c = 2(\bar{V} - \underline{V})\), \(\beta = 1/4\)
\[Q(s, a) + c \frac{N(s)^\beta}{\sqrt{N(s, a)}}\]
or
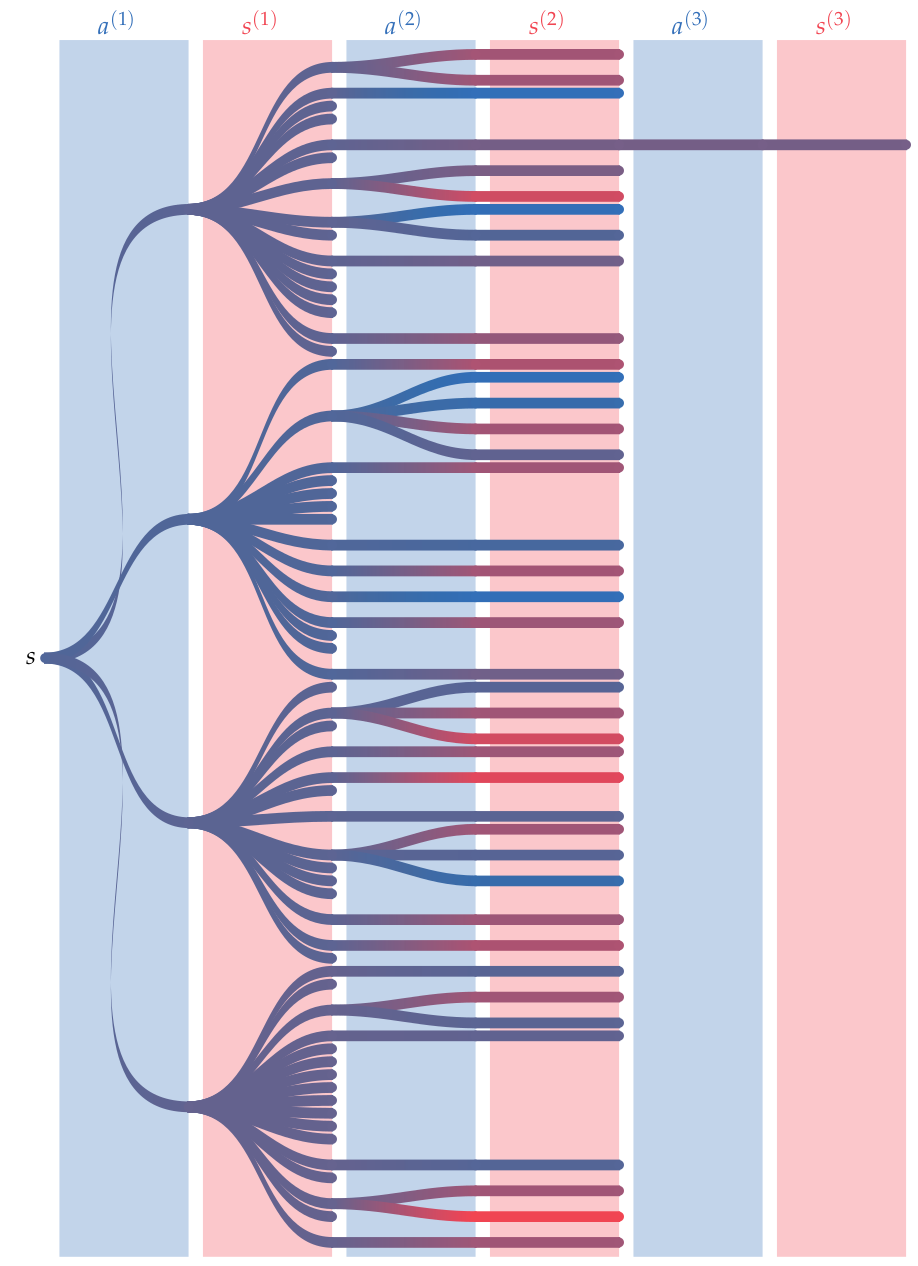
Using Online Methods in a Simulation
Algorithm: Rollout Simulation
Given: MDP \((S, A, R, T, \gamma, b)\)
\(s \gets \text{sample}(b)\)
\(\hat{u} \gets 0\)
for \(t\) in \(0 \ldots T-1\)
\(a \gets \pi(s)\)
\(s', r \gets G(s, a)\)
\(\hat{u} \gets \hat{u} + \gamma^t r\)
\(s \gets s'\)
return \(\hat{u}\)
Guiding Questions
What are the differences between online and offline solutions?
Are there solution techniques that are independent of the state space size?
Forward Search Sparse Sampling
(FSSS)
Paper: https://cdn.aaai.org/ojs/7689/7689-13-11219-1-2-20201228.pdf
- Sparse Sampling, but only look at potentially valuable states
Things it keeps track of:
\(Q(s,a)\): Estimate of the value for the state action pair
\(U(s)\): Upper bound for value of state s
\(L(s)\): Lower bound for value of state s
\(U(s,a)\): Upper bound for value of state-action
\(L(s,a)\): Lower bound for value of state-action
Forward Search Sparse Sampling
If \(L(s,a*)\geq \max_{a\neq a^*} U(s,a)\) for best action (\(a^*=\arg\max_a U(s,a)\)):
then, the node is closed because the best action is found.

070-Online-Methods
By Zachary Sunberg



