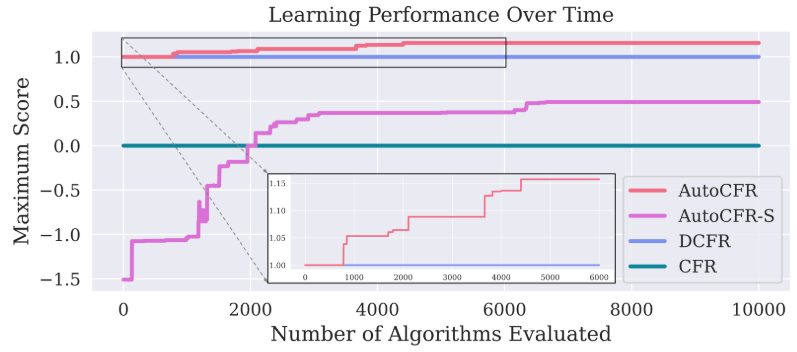
AutoCFR
Xu et al. 2022
- Review of Imperfect Information Games
- Review of CFR
- Non Monte Carlo CFR variants
- Regularized Evolution
- AutoCFR
Imperfect Information Extensive Game Formalism
Extensive Form Games
- Reasoning about action histories
R
P
S
Player 1
Player 2
\sigma : H \rightarrow \mathcal{A}
R
P
S
R
P
S
R
P
S
R
P
S
Player 1
Player 2
(0,0)
(0,0)
(0,0)
(-1,1)
(-1,1)
(-1,1)
(1,-1)
(1,-1)
(1,-1)
\sigma : H \rightarrow \mathcal{A}
Extensive Form Games
- Reasoning about action histories
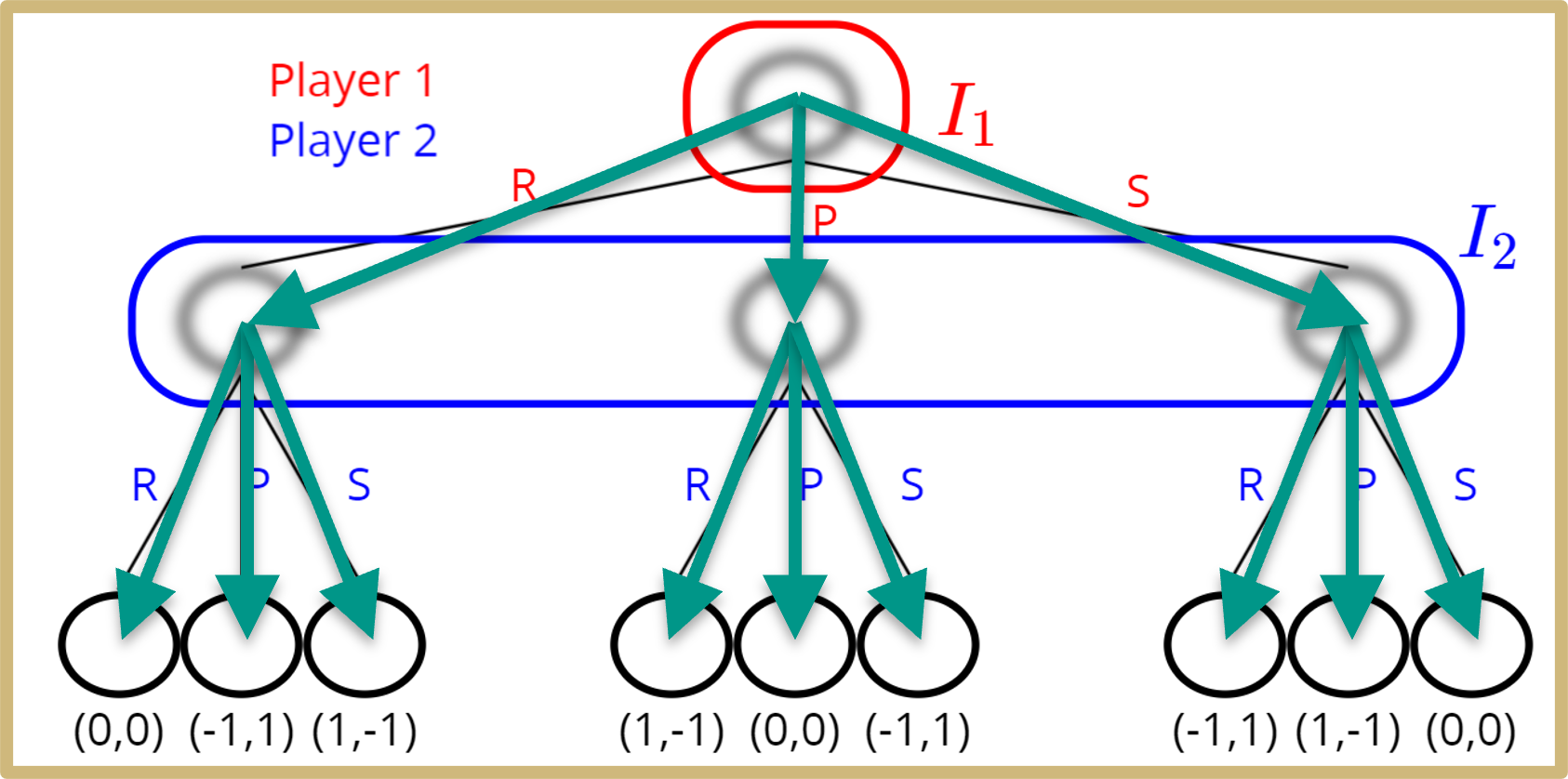
Imperfect Information Extensive Form Games
- Reasoning about information sets
R
P
S
R
P
S
R
P
S
R
P
S
Player 1
Player 2
(0,0)
(0,0)
(0,0)
(-1,1)
(-1,1)
(-1,1)
(1,-1)
(1,-1)
(1,-1)
I_1
I_2
\sigma : \mathcal{I} \rightarrow \mathcal{A}
Counterfactual Regret Minimization
R_{i}^{T}(I, a)=\frac{1}{T} \sum_{t=1}^{T} \pi_{-i}^{\sigma^{t}}(I)\left(u_{i}\left(\left.\sigma^{t}\right|_{I \rightarrow a}, I\right)-u_{i}\left(\sigma^{t}, I\right)\right)
u_{i}(\sigma, I)=\frac{\sum_{h \in I, h^{\prime} \in Z} \pi_{-i}^{\sigma}(h) \pi^{\sigma}\left(h, h^{\prime}\right) u_{i}\left(h^{\prime}\right)}{\pi_{-i}^{\sigma}(I)}
Subgame utility evaluation
Counterfactual Regret Minimization
\sigma_{i}^{T+1}(I)(a)= \begin{cases}\frac{R_{i}^{T,+}(I, a)}{\sum_{a \in A(I)} R_{i}^{T,+}(I, a)} & \text { if } \sum_{a \in A(I)} R_{i}^{T,+}(I, a)>0 \\ \frac{1}{|A(I)|} & \text { otherwise. }\end{cases}
\bar{\sigma}_{i}^{t}(I)(a)=\frac{\sum_{t=1}^{T} \pi_{i}^{\sigma^{t}}(I) \sigma^{t}(I)(a)}{\sum_{t=1}^{T} \pi_{i}^{\sigma^{t}}(I)}
CFR Variants
(non Monte Carlo)
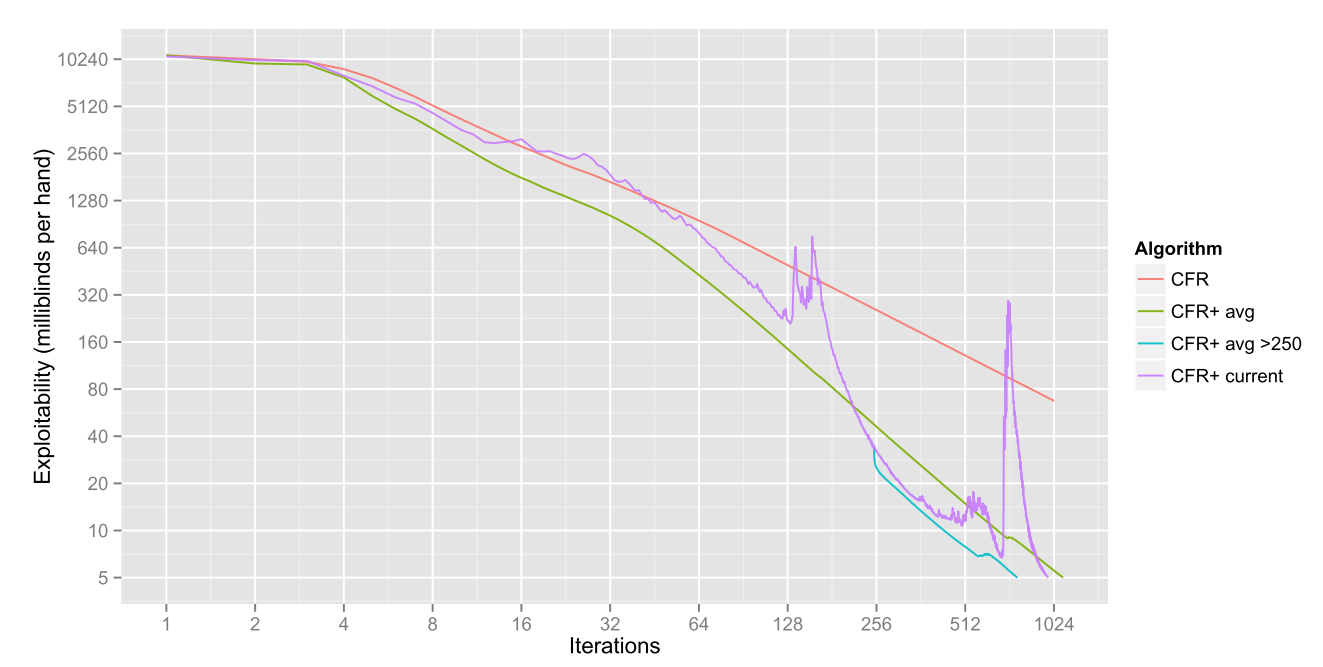
Tightest known convergence bound for CFR+ is 2x worse than vanilla CFR
(but in practice CFR+ converges significantly faster)
CFR+
R_i^T(I,a) = \max(0, R_i^{T-1}(I,a) + r_i^{T}(I,a))
\sigma^{T+1}_i(I,a) = \frac{R_i^{T,+}(I,a)}{\sum_{a'}R_i^{T,+}(I,a')}
\bar{\sigma}_{i}^{t}(I)(a)=\frac{\sum_{t=1}^{T} t\pi_{i}^{\sigma^{t}}(I) \sigma^{t}(I)(a)}{\sum_{t=1}^{T} t\pi_{i}^{\sigma^{t}}(I)}
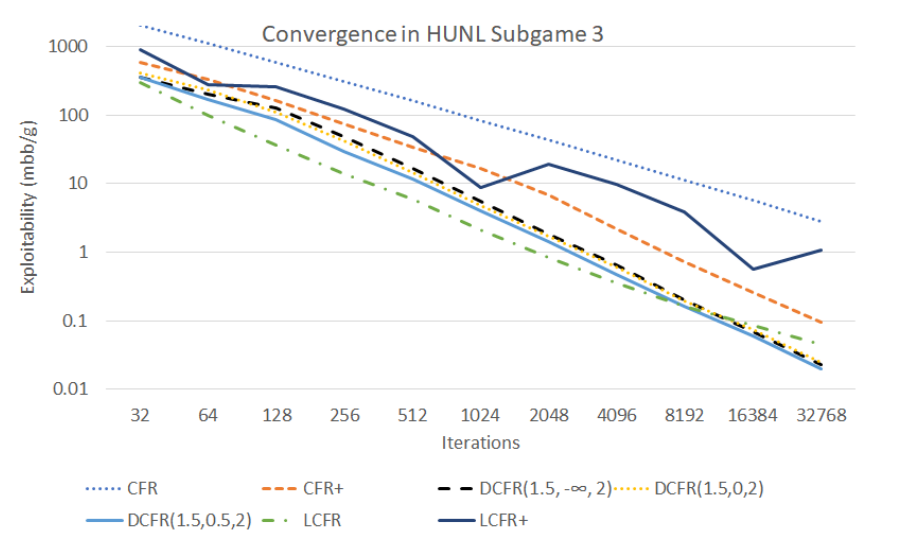
DCFR
R_i^T(I,a) = \begin{cases}
R_i^{T-1}(I,a) + T^\alpha r_i^{T}(I,a) \quad & R_i^{T-1}(I,a) > 0 \\
R_i^{T-1}(I,a) + T^\beta r_i^{T}(I,a) \quad & R_i^{T-1}(I,a) \le 0 \\
\end{cases}
\sigma^{T+1}_i(I,a) = \frac{R_i^{T,+}(I,a)}{\sum_{a'}R_i^{T,+}(I,a')}
\bar{\sigma}_{i}^{t}(I)(a)=\frac{\sum_{t=1}^{T} t^\gamma\pi_{i}^{\sigma^{t}}(I) \sigma^{t}(I)(a)}{\sum_{t=1}^{T} t^\gamma\pi_{i}^{\sigma^{t}}(I)}
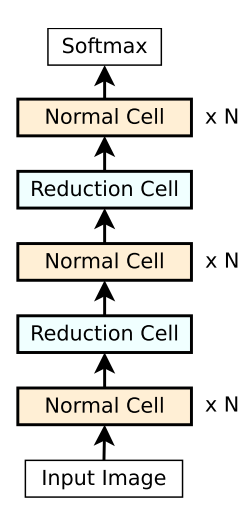
Regularized Evolution
(A solution to graduate student descent)
\{

Sample subset of population
Random architecture population initialization
Cull the old
Mutate best, evaluate, store
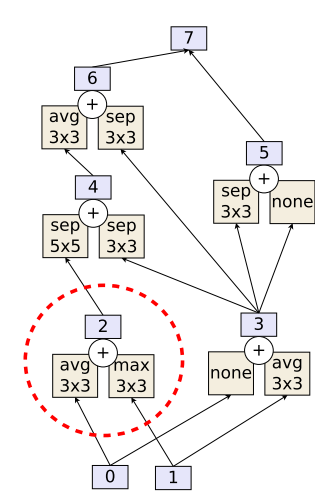
AutoCFR
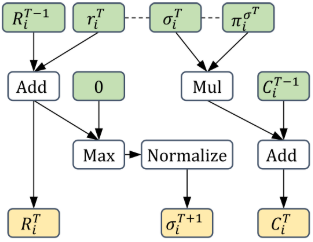
R_i^T(I,a) = R_i^{T-1}(I,a) + r_i^{T}(I,a)
\sigma^{T+1}_i(I,a) = \frac{R_i^{T,+}(I,a)}{\sum_{a'}R_i^{T,+}(I,a')}
C_i^{T}(I,a) = C_i^{T-1}(I,a) + \pi_i^{\sigma^T}(I)\sigma_i^T(I,a)
Back to simulink...
CFR
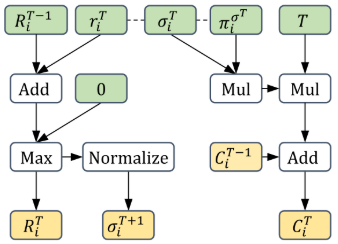
R_i^T(I,a) = \max(0, R_i^{T-1}(I,a) + r_i^{T}(I,a))
\sigma^{T+1}_i(I,a) = \frac{R_i^{T,+}(I,a)}{\sum_{a'}R_i^{T,+}(I,a')}
C_i^{T}(I,a) = C_i^{T-1}(I,a) + T\pi_i^{\sigma^T}(I)\sigma_i^T(I,a)
CFR+
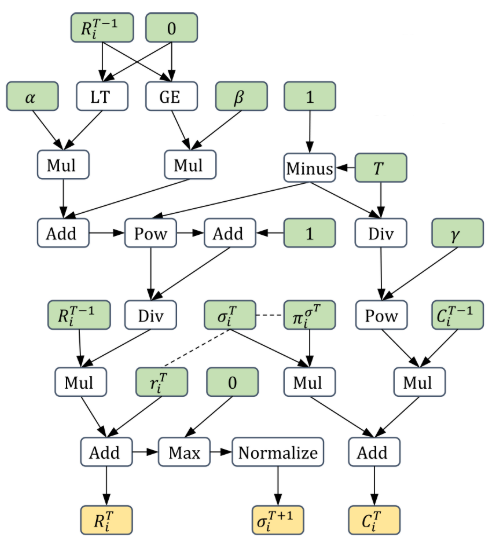
R_i^T(I,a) = \begin{cases}
R_i^{T-1}(I,a)\frac{(T-1)^\alpha}{(T-1)^\alpha + 1} + r_i^{T}(I,a) \quad & R_i^{T-1}(I,a) > 0 \\
R_i^{T-1}(I,a)\frac{(T-1)^\beta}{(T-1)^\beta + 1} + r_i^{T}(I,a) \quad & R_i^{T-1}(I,a) \le 0 \\
\end{cases}
\sigma^{T+1}_i(I,a) = \frac{R_i^{T,+}(I,a)}{\sum_{a'}R_i^{T,+}(I,a')}
C_i^{T}(I,a) = C_i^{T-1}(I,a)\left(\frac{T-1}{T}\right)^\gamma + \pi_i^{\sigma^T}(I)\sigma_i^T(I,a)
DCFR
A^{*}=\underset{A \in \mathbb{A}}{\arg \max }\left[\sum_{G \in \mathbb{G}} W_{G} \operatorname{Eval}(A, G)\right]
\operatorname{Eval}(A, G)=\min \left(S_{G}, \frac{\log E_{\mathrm{CFR}}^{G}-\log E_{A}^{G}}{\log E_{\mathrm{CFR}}^{G}-\log E_{\mathrm{DCFR}}^{G}}\right)
Evaluation
Clipped, normalized exploitability
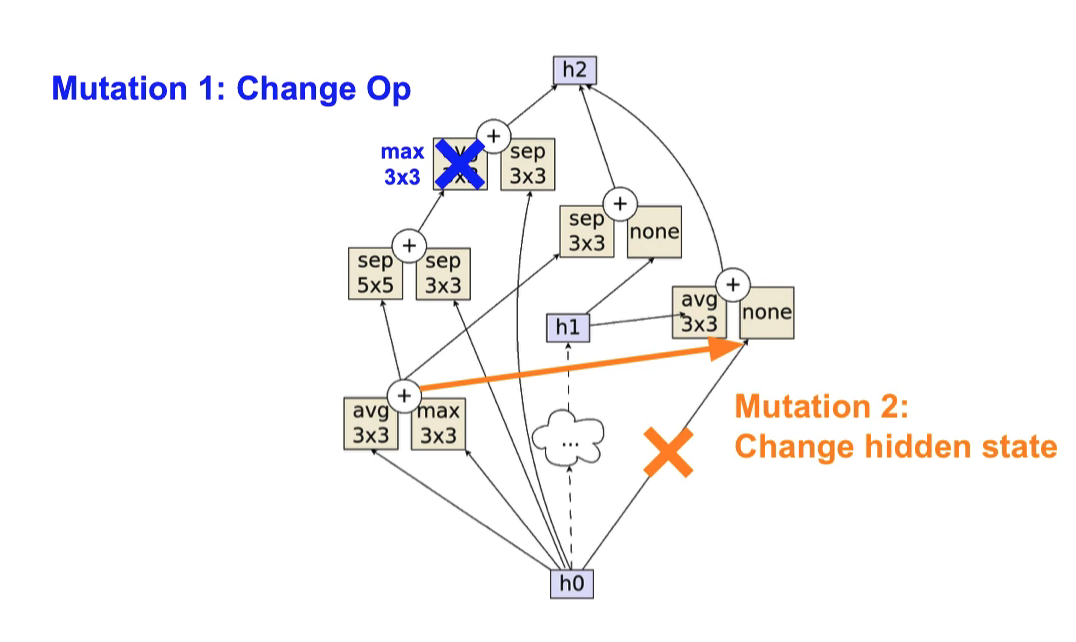
Algorithm

Initialize random (or bootstrapped) population
Sample from subset of population
Mutate & ensure candidate is reasonable contender
Evaluate mutant & store
Algorithm

Intermediate Policy Improvement
Intermediate Policy Evaluation
Final Policy Evaluation
DDCFR
Double-clipped Discounted CFR
R_{i}^{T}(I, a)=\max \left(0, \min \left(1, R_{i}^{T-1}(I, a) * \frac{(T-1)^{1.5}}{(T-1)^{1.5}+1.5}\right)+r_{i}^{T}(I, a)\right) \\
\sigma^{T+1}_i(I,a) = \frac{R_i^{T,+}(I,a)}{\sum_{a'}R_i^{T,+}(I,a')} \\
C_{i}^{T}(I, a)=C_{i}^{T-1}(I, a) * \frac{T-1}{T}+\pi_{i}^{\sigma^{T}} * T^{3} * \sigma_{i}^{T}(I, a)
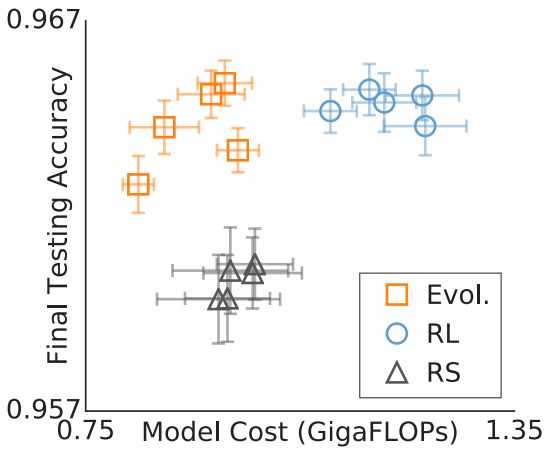
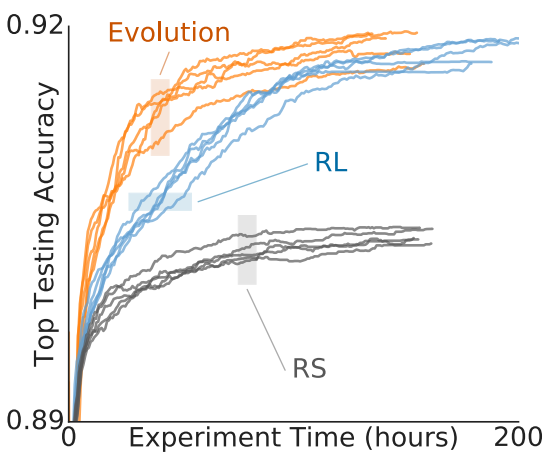
Results


Training
Testing
AutoCFR
By Tyler Becker



