Robotics Summer Student Seminar (RSSS) 2022


Himanshu Gupta

Autonomous Navigation in Environments Shared with Humans through POMDP Planning
Autonomous systems in the real world


A capable robot must
Infer pedestrian's intention
Predict pedestrian's behavior given its intention
Plan a path
to its goal location
Prior Work
Reactive Controller
Predict and Act Controller


Issues
- Pedestrian Model?
- Future effect of immediate actions?
Issue
- Uncertainty in pedestrian intention estimation?

Need a method that determines the optimal action by reasoning over the uncertainty in pedestrian intention!

Need a method that determines the optimal action by reasoning over the uncertainty in pedestrian intention!
Outline of the talk
- Brief Introduction to POMDPs
- Previous Approach
(Limited Space Planner or \(\textbf{1D-A}^*\))
- Our Approach
(Extended Space Planner or 2D Approach)
Preliminaries
- \(\mathcal{S}\) - State space
- \(\mathcal{A}\) - Action space
- \(T:\mathcal{S}\times \mathcal{A} \times\mathcal{S} \to \mathbb{R}\) - Transition probability distribution
- \(R:\mathcal{S}\times \mathcal{A} \to \mathbb{R}\) - Reward

Markov Decision Process (MDP)
Partially Observable Markov Decision Process (POMDP)

- \(\mathcal{S}\) - State space
- \(\mathcal{A}\) - Action space
- \(T:\mathcal{S}\times \mathcal{A} \times\mathcal{S} \to \mathbb{R}\) - Transition probability distribution
- \(R:\mathcal{S}\times \mathcal{A} \to \mathbb{R}\) - Reward
- \(\mathcal{O}\) - Observation space
- \(Z:\mathcal{S} \times \mathcal{A}\times \mathcal{S} \times \mathcal{O} \to \mathbb{R}\) - Observation probability distribution
\begin{aligned}
& \mathcal{S} = \mathbb{Z} \quad \quad \quad ~~ \mathcal{O} = \mathbb{R} \\
& s' = s+a \quad \quad o \sim \mathcal{N}(s, s-10) \\
& \mathcal{A} = \{-10, -1, 0, 1, 10\} \\
& R(s, a) = \begin{cases}
100 & \text{ if } a = 0, s = 0 \\
-100 & \text{ if } a = 0, s \neq 0 \\
-1 & \text{ otherwise}
\end{cases} & \\
\end{aligned}

State
Timestep
Accurate Observations
Goal: \(a=0\) at \(s=0\)
Optimal Policy
Localize
\(a=0\)
POMDP Example: Light-Dark
POMDP Sense-Plan-Act Loop
Environment
Belief Updater
Policy
\(b\)
\(a\)
\[b_t(s) = P\left(s_t = s \mid a_1, o_1 \ldots a_{t-1}, o_{t-1}\right)\]

True State
\(s = 7\)
Observation \(o = -0.21\)
Solving a POMDP
- Obtaining exact solutions to POMDPs is an intractable problem [1].
- They are solved approximately in an online fashion by performing a tree search over the belief space.
[1] Christos H. Papadimitriou and John N. Tsitsiklis. 1987. The Complexity of Markov Decision Processes. Mathematics of Operations Research 12, 3 (1987), 441–450.

Action Nodes
Belief Nodes
Solving a POMDP


Roll-out Policy is important


Previous Approach ( \(\textbf{1D-A}^*\) )

Bai et. al, ICRA 2015
Previous Approach ( \(\textbf{1D-A}^*\) )

Bai et. al, ICRA 2015
Solving POMDP using DESPOT
- STATE:
\((x_c,y_c,\theta_c,v_c, g_c)\)
corresponding to the 2D pose, speed and goal of the vehicle.
\((x_i,y_i,v_i, g_i)\)
corresponding to the \(i^{th}\) pedestrian's state
- ACTION:
$$\delta_s \in \{\textbf{Increase Speed, Decrease Speed,}$$ $$\textbf{Maintain Speed, Sudden Brake\}}$$
Effective
Roll-out Policy is important
Bai et. al, ICRA 2015
Previous Approach ( \(\textbf{1D-A}^*\) )
$$\delta_s \in \{\textbf{Increase Speed, Decrease Speed,}$$ $$\textbf{Maintain Speed, Sudden Brake\}}$$
Bai et. al, ICRA 2015
\(\textbf{1D-A}^*\) Approach
ISSUES?
- Decoupling of heading angle planning and speed planning often leads to unnecessary stalling of the vehicle!
- Hybrid A* path can't be found at at every time step!

Bai et. al, ICRA 2015
2D Approach

2D Approach

Solving POMDP using DESPOT
- STATE:
\((x_c,y_c,\theta_c,v_c, g_c)\)
corresponding to the 2D pose, speed and goal of the vehicle.
\((x_i,y_i,v_i, g_i)\)
corresponding to the \(i^{th}\) pedestrian's state
- ACTION:
$$\delta_s(t) \in \{\textbf{Increase Speed, Decrease Speed,}$$ $$\textbf{Maintain Speed, Sudden Brake\}}$$
Same as previous POMDP
- ACTION:
$$\mathcal{a = ( \delta_\theta , \delta_s )}$$
2D Approach
- Critical Challenge: Determining a good roll-out policy for the vastly increased set of states during tree search.
Effective roll-out policy
- Obtain a path using multi query motion planning technique
- Probabilistic RoadMap (PRM)
- Fast Marching Method (FMM)
Probabilistic RoadMaps (PRM) for Multi-Query Path Planning

Fast Marching Method for Multi-Query Path Planning





Effective roll-out policy
- Obtain a path using multi query motion planning technique
- Probabilistic RoadMap (PRM)
- Fast Marching Method (FMM)
- Roll-out policy: Execute a reactive controller over the obtained path
Simulation Environment
- Environment: \(100\)m x \(100\)m square field

-
Autonomous vehicle: A holonomic vehicle.
- Inspired by Kinova MOVO
- Max speed: \(2\) m/s

Experimental Scenarios



Scenario 1
(Open Field)
Scenario 2 (Cafeteria Setting)
Scenario 3
(L shaped lobby)
Planners
# possible actions in POMDP Planning: 4
# possible actions in POMDP Planning: 11

Experimental Details
- In simulations, the planning time for the vehicle at each step is 0.5 seconds

Experimental Details
- For each scenario, we ran sets of 100 different experiments with different pedestrian densities in the environment.



# humans = 100
# humans = 200
# humans = 300
# humans = 400
Scenario 1
Results
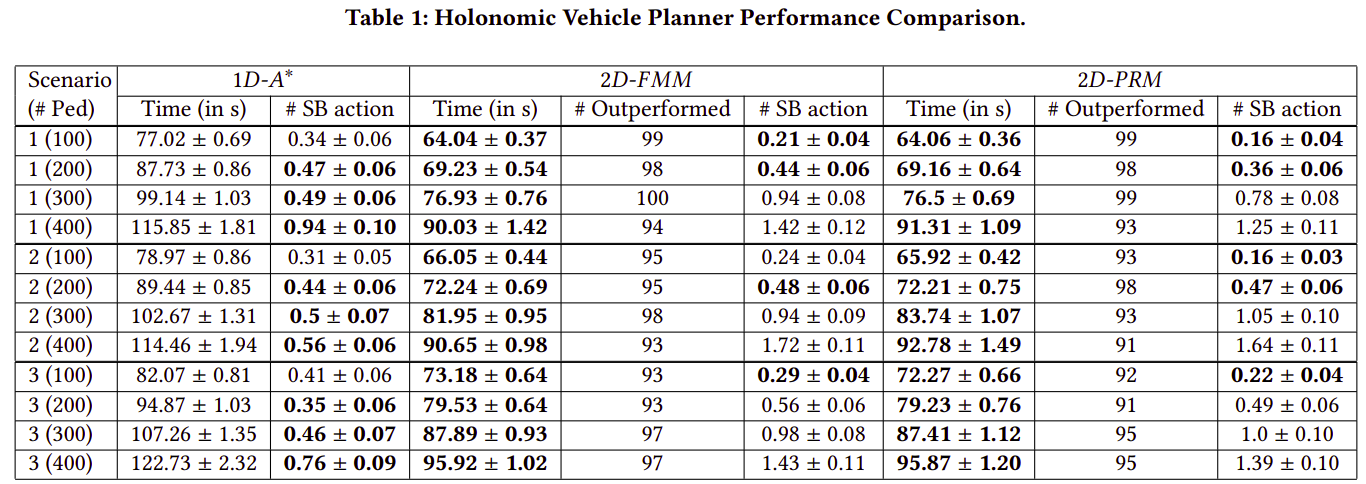
Evaluation Metric: Travel Time (in s)
Results
Evaluation Metric: #Outperformed
Scenario 2



\(1D-A^*\)
\(2D-FMM\)
\(2D-PRM\)
Results
Results



Scenario 1
\(1D-A^*\)
\(2D-FMM\)
\(2D-PRM\)
Results
Scenario 3



\(1D-A^*\)
\(2D-FMM\)
\(2D-PRM\)

Limited Space Planner
Extended Space Planner
Conclusion
Future Work
Future Work
-
THE NEXT TALK
Extending the proposed approach to non-holonomic vehicles.

Future Work
- Extending this work to a high DOF agent

- Robotic manipulator
(Pellegrinelli et. al, IROS 16)
Future Work
- Goal-Object Data Association for Life Long Learning

Future Work
- Online POMDP solvers for POMDPs with continuous or large action space
Thank You!
Himanshu Gupta
himanshu.gupta@colroado.edu
Extended Space POMDP Planning
(AAMAS 2022)
https://github.com/himanshugupta1009/extended_space_navigation_pomdp
Feedback from Zach
- Too Smooth
- Slide numbers
- Our conception of a POMDP
- If you can't fix gif, probably just remove animations
- Use same name for two-step
- Map for old approach and new approach
- In Limited Space/Extended space say (action space)
- Future work -> Next talk
- Continuous space POMDP solvers
- Results - make sure to point to which graph you are talking about
- Don't make a big deal about the non-holonomic - leave that to Will
Experiments (NHV)
Limited Space
Planner
Extended Space
Planners
\(1D\)-\(A^*\)
\(2D\)-\(NHV\)

Roll-out Policy (NHV)
Results (NHV)

Evaluation Metric: Travel Time (in s)
Evaluation Metric: #Outperformed
Results (NHV)


\(1D-A^*\)
\(2D-NHV\)
Results (NHV)
RSSS 2022
By Himanshu Gupta



