What Matters in On-Policy Reinforcement Learning?
A Large-Scale Empirical Study
or
PPO: The Algorithm, the Myth, the Legend
Google Brain Team, ICLR 2021
Presented by Professor Zachary Sunberg, August 26th, 2025
AI used to confirm connections between ideas, create images
Motivation
- It's 2021
- DRL is a powerful tool
- PPO most popular algorithm
- Original PPO paper claimed clipped surrogate objective responsible for its performance
- Other research had raised questions: How much of PPO's performance is due to
- Clipped surrogate objective
- Implementation details
- Motivating Question: What matters in on-policy RL?
- Possible Tools:
- Theory: None available to answer these questions
- Numerical Experiments: scale challenge (thankfully, this is Google that we're talking about)
Motivation
- By 2021 deep reinforcement learning had become a powerful tool, with PPO beginning to emerge as the most popular algorithm
- The original PPO paper claimed that theoretically justified advances were responsible for its performance
- However, other research had raised questions about how much of PPO's performance is due to principles highlighted in the original paper and how much is due to other design choices and differences
- Tools: Theory, Numerical Experiments
- No Theory available to answer these questions
- Numerical Experiments very difficult because of scale (thankfully, this is google that we're talking about)
Contributions
- Investigated 68 choices by implementing all in a unified framework and testing on Mujoco "robotics" tasks
- Trained 250,000 agents with heuristically-guided sampling of choice values and offered recommendations
- Tons of results, including Mega Appendix: Figures 3-92
- "Most surprising finding": network initialization matters!
Background Paper: PPO
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov; 2017
https://arxiv.org/pdf/1707.06347 (Not Peer Reviewed!)

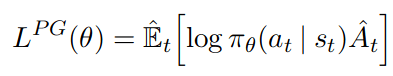
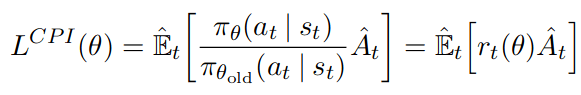
Advantage \(A_t = Q(s_t, a_t) - V(s_t)\)
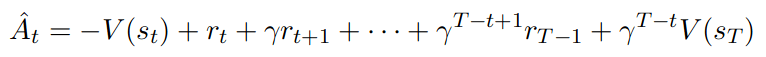
CPI = "Conservative Policy Iteration"
Problem: Can produce large update
=> only one step before collecting new data
(TRPO solved this with KL constraint/penalty)

Background Paper: PPO
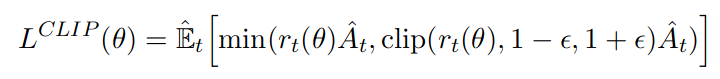
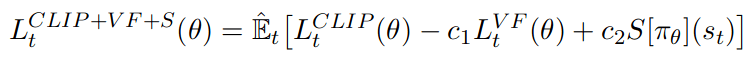
Value
Entropy
"We don’t share parameters between the policy and value function (so coefficient c1 is irrelevant), and we don’t use an entropy bonus."
Story:
- Easy to implement
- Enables minibatch updates
- Superior empirical performance


The Algorithm
Background Paper: PPO
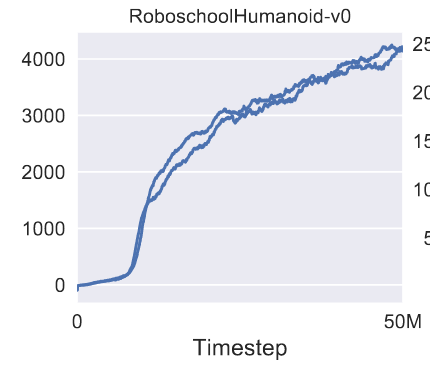
Cited 29262 times (as of last night)
Impact

- John Schulman was a co-founder of OpenAI
- InstructGPT (first large-scale RLHF) used PPO to get a GPT model to obey human intent (crucial to get a language model to act as a chatbot)
- ChatGPT is a successor to InstructGPT
(avg ~10x per day)
But...
Background Paper: Impl Matters
Implementation Matters in Deep Policy Gradients: A Case Study on PPO and TRPO
Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Firdaus Janoos, Larry Rudolph, and Aleksander Madry; ICLR 2020
Implementation Details
- Value function clipping
- Reward scaling
- Orthogonal initialization and layer scaling
- Adam learning rate annealing
- Reward clipping
- Observation normalization
- Observation clipping
- Hyperbolic tan activations
- Global gradient clipping
"PPO’s marked improvement over TRPO (and even stochastic gradient descent) can be largely attributed to these optimizations."
Background Paper: Impl Matters
Implementation Matters in Deep Policy Gradients: A Case Study on PPO and TRPO
Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Firdaus Janoos, Larry Rudolph, and Aleksander Madry; ICLR 2020


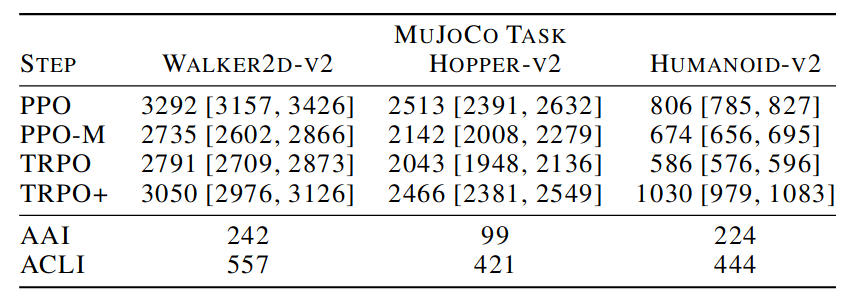
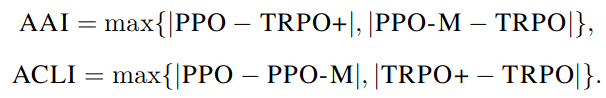
AAI = Average Algorithmic Improvement
ACLI = Average Code Level Improvement
The Myth
Back to "What Matters"
Thematic Groups:
- Policy Losses (PG, PPO, ...)
- Networks Architecture (size, activation function, ...)
- Normalization and clipping (gradient clip, obs norm, ...)
- Advantage Estimation (N-step, GAE, ...)
- Training setup (minibatches, ...)
- Timestep handling (discount, frameskip, ...)
- Optimizers (Adam, RMSProp, ...)
- Regularization (Entropy, KL w.r.t some policy, ...)
Goal: Evaluate which design choices are most effective
Problem Setting
- MDP reinforcement learning
- Continuous control tasks in Mujoco
s, r, done, info = env.step(a)





Methods
68 choices with ~3 values each \(\implies 3^{68} \approx 2.8 \times 10^{32}\) configurations.
~250,000 agents trained
(C24: Learning Rate included in some other groups)
Sample Uniformly for Choices within Group
Baseline
\(\approx\) ppo2
Group: Policy Losses
Group: Regularizers
Group: Optimizers
...
C23: Adam/RMSProp
C24: Learning Rate
C26: Momentum
Methods
Uniform sampling \(\implies\) sometimes bad combination \(\implies\) report 95th percentile
95th percentile
95% confidence interval for 95th percentile
Computational Resources
- Computational resources not reported
- How long would it take on your desktop?
- Claude says about an hour with your GPU
- 250,000 GPU-hours = 28.5 GPU-years
- Probably not feasible for a student to do

Numerical Results
(Very Selected - there are 92 figures)
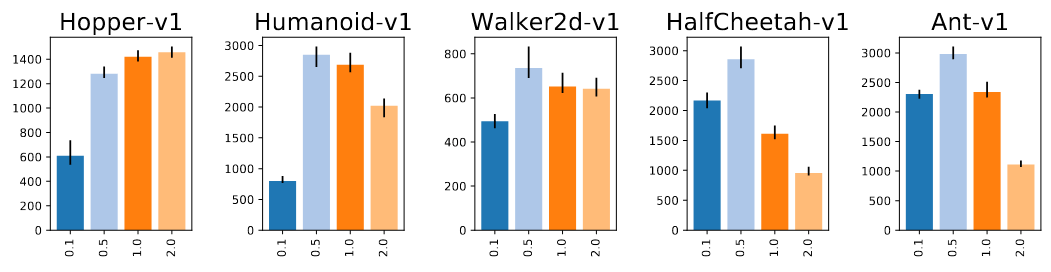
Normalization and Clipping
Observation Normalization
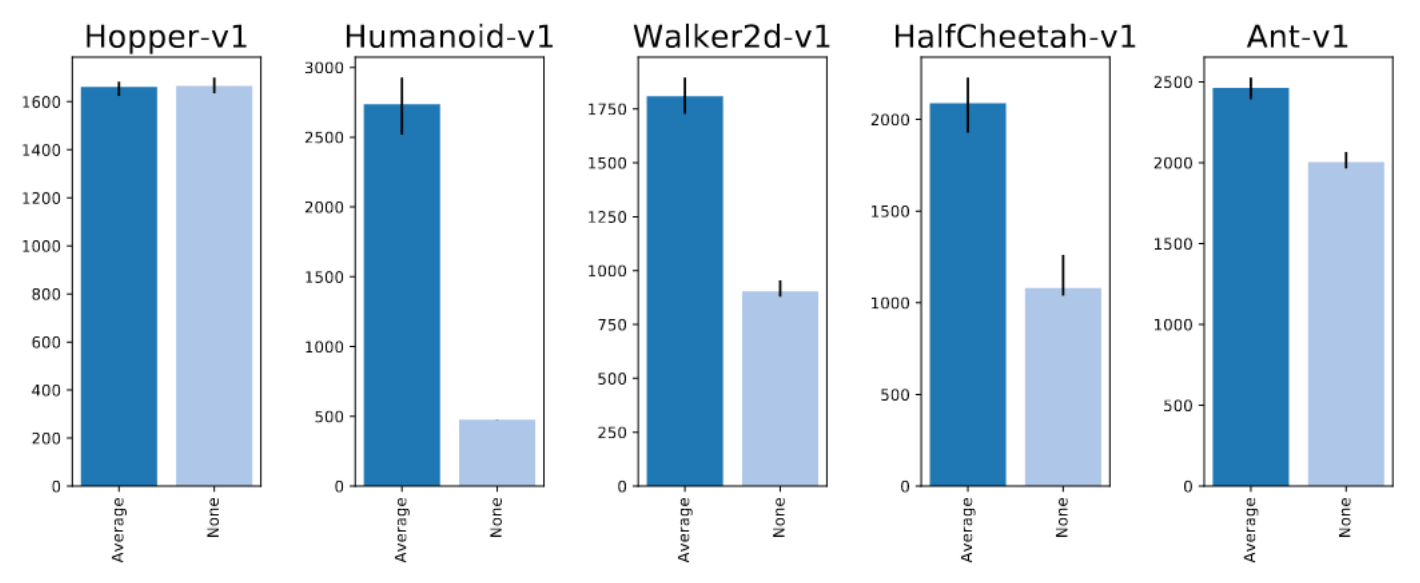
Value Function Normalization
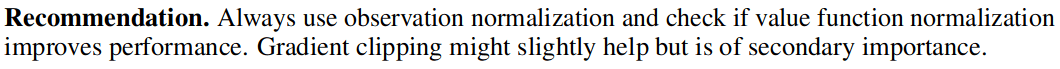
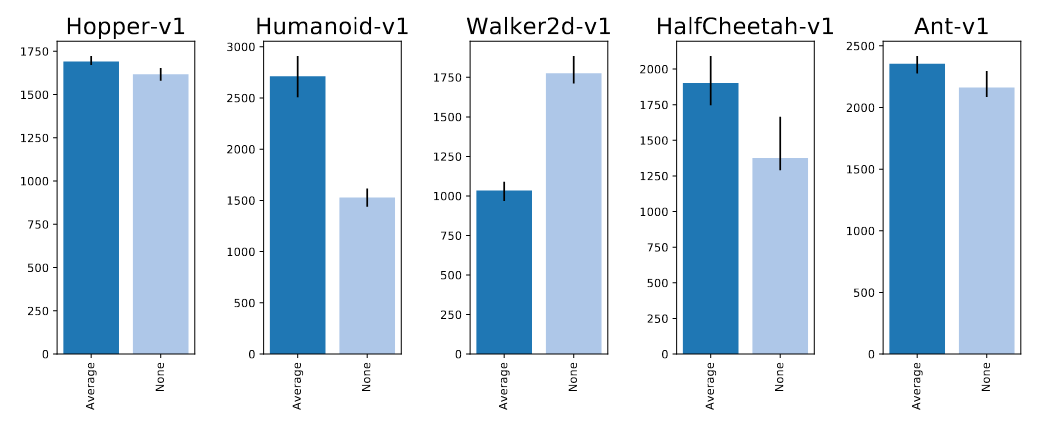
Numerical Results
Networks Architecture
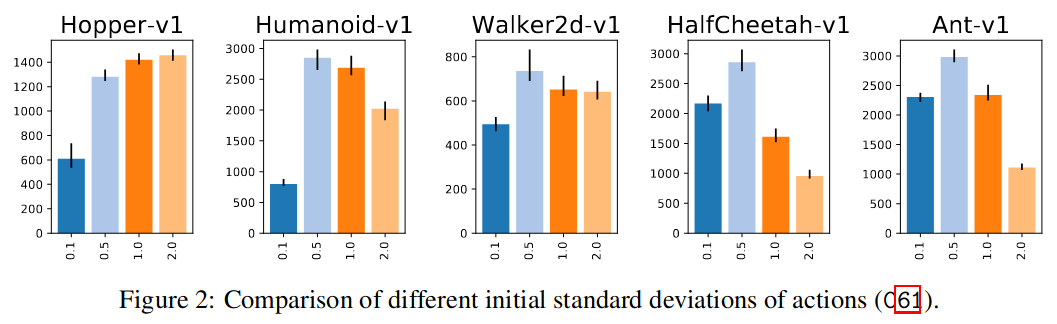

"Most surprising results"
Numerical Results
Policy Losses
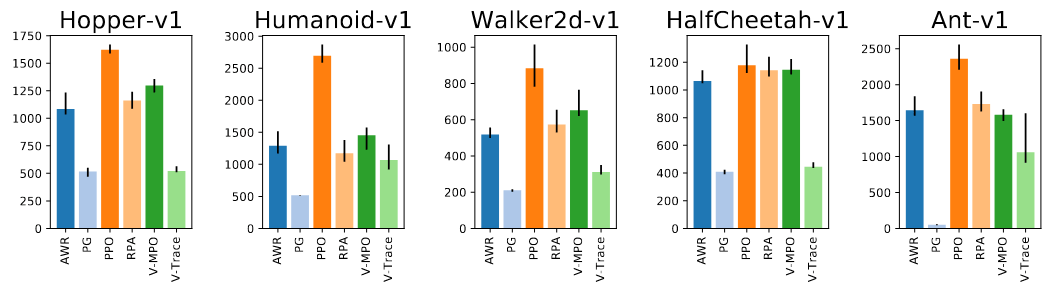
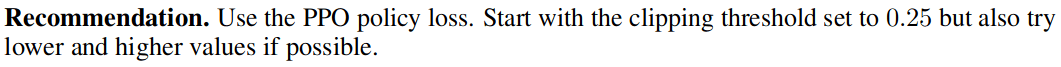
Vindication!
The Legend
Critique
Commendations
- Thorough
- Did not give computational setup
- Not the kind of research we can do - good that Google does it.
- Kudos for managing huge amount of data
Criticisms
- Lack of environment diversity
Impact and Legacy
- Most people who implement an RL algorithm will read this paper.
- Best answer to "Why isn't my PPO working?"
- Cited by ~500
- Dreamer V3
- Magnetic control of tokamak plasmas through deep reinforcement learning
Recommended Reading
The 37 Implementation Details of PPO; 2022 ICLR Blog Track
Huang, Shengyi; Dossa, Rousslan Fernand Julien; Raffin, Antonin; Kanervisto, Anssi; Wang, Weixun
Contributions
- Investigated 68 choices by implementing all in a unified framework and testing on Mujoco "robotics" tasks
- Trained 250,000 agents with heuristically-guided sampling of choice values and offered recommendations
- Tons of results, including Mega Appendix: Figures 3-92
- "Most surprising finding": network initialization matters!